Kunstig intelligens
Oprettelse af en brugerdefineret Generative Adversarial Network med skitser

Forskere fra Carnegie Mellon og MIT har udviklet en ny metode, der giver brugeren mulighed for at oprette brugerdefinerede Generative Adversarial Network (GAN) billedskabningssystemer ved blot at tegne indicative skitser.
Et system af denne type kunne give slutbrugeren mulighed for at oprette billedgenereringsystemer, der kan generere meget specifikke billeder, såsom bestemte dyr, bygningstyper – og endda enkelte personer. For tiden producerer de fleste GAN-genereringssystemer bredt og ret tilfældigt output, med begrænset mulighed for at specificere bestemte egenskaber, såsom dyrearter, hårtypes hos mennesker, arkitekturstilarter eller faktiske ansigtsidentiteter.
Tilgangen, der er beskrevet i artiklen Tegn din egen GAN, anvender en ny skitsegrænseflade som en effektiv ‘søgefunktion’ til at finde funktioner og klasser i ellers overfyldte billeddatabase, der kan indeholde tusinder af objekter, herunder mange underkategorier, der ikke er relevante for brugerens formål. GAN bliver derefter trænet på denne filtrerede undermængde af billeder.
Ved at tegne den specifikke objektype, som brugeren ønsker at kalibrere GAN, bliver rammevirkningens genereringsmuligheder specialiseret til denne klasse. For eksempel, hvis en bruger ønsker at oprette en ramme, der genererer en bestemt type kat (i stedet for bare en hvilken som helst kat, som kan opnås med This Cat Does Not Exist), fungerer brugerens inputskitser som et filter til at udelukke ikke-relevante katteklasser.

Kilde: https://peterwang512.github.io/GANSketching/
Forskningen er ledet af Sheng Yu-Wang fra Carnegie Mellon University, sammen med medarbejder Jun-Yan Zhu og David Bau fra MIT’s Computer Science & Artificial Intelligence Laboratory.
Metoden selv kaldes ‘GAN-skitsning’, og anvender inputskitserne til direkte at ændre vægtningerne af en ‘skabelon’ GAN-model til specifikt at målrette den identificerede domæne eller underdomæne gennem cross-domæne-adversarial-tab.
Forskellige reguleringsteknikker blev udforsket for at sikre, at modellens output er divers, samtidig med at den opretholder en høj billedkvalitet. Forskerne oprettede prøveapplikationer, der kan interpolere latent rum og udføre billedredigering.
Dette [$class] eksisterer ikke
GAN-baserede billedgenereringssystemer er blevet en fad, hvis ikke en meme, over de sidste par år, med en udbredelse af projekter, der kan generere billeder af ikke-eksisterende ting, herunder mennesker, lejeboliger, snacks, fødder, heste, politikere og insekter, blandt mange andre.
GAN-baserede billedsynthesisystemer oprettes ved at samle eller kuratere omfattende datasæt, der indeholder billeder fra måldomænet, såsom ansigter eller heste; træne modeller, der generaliserer en række funktioner på tværs af billederne i databasen; og implementere generatormoduler, der kan producere tilfældige eksempler baseret på de lænte funktioner.

Output fra skitser i DeepFacePencil, der giver brugeren mulighed for at oprette fotorealistiske ansigter fra skitser. Mange lignende skitse-til-billede-projekter findes. Kilde: https://arxiv.org/pdf/2008.13343.pdf
Højdimensionelle funktioner er blandt de første, der konkreteres under træningsprocessen, og svarer til en malers første brede penselstrøg på en canvas. Disse højdimensionelle egenskaber vil til sidst korrelerer med langt mere detaljerede funktioner (f.eks. øjneglans og skarpe vibrer på en kat, i stedet for bare en generisk beige klump, der repræsenterer hovedet).
Jeg ved, hvad du mener…
Ved at kortlægge forholdet mellem disse tidlige seminale former og de endelige detaljerede fortolkninger, der opnås meget senere i træningsprocessen, er det muligt at slutte forhold mellem ‘vage’ og ‘specifikke’ billeder, hvilket giver brugeren mulighed for at oprette komplekse og fotorealistiske billeder fra grove skitser.
For nylig udgav NVIDIA en skrivebordsversion af sin langsigtede GauGAN-forskning i GAN-baseret landskabsgenerering, der let demonstrerer dette princip:
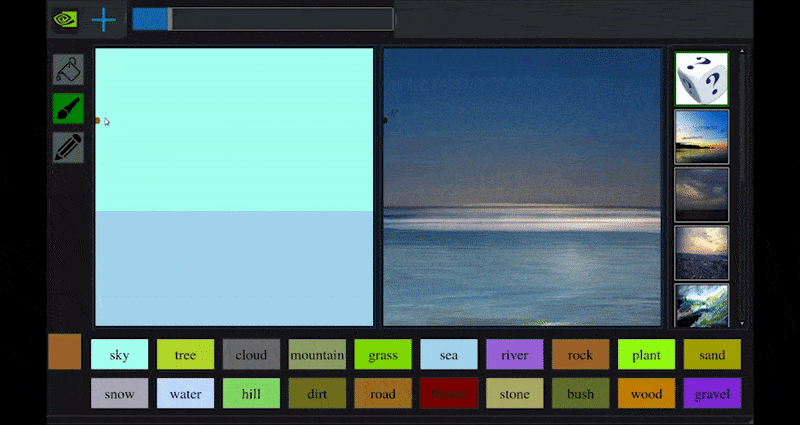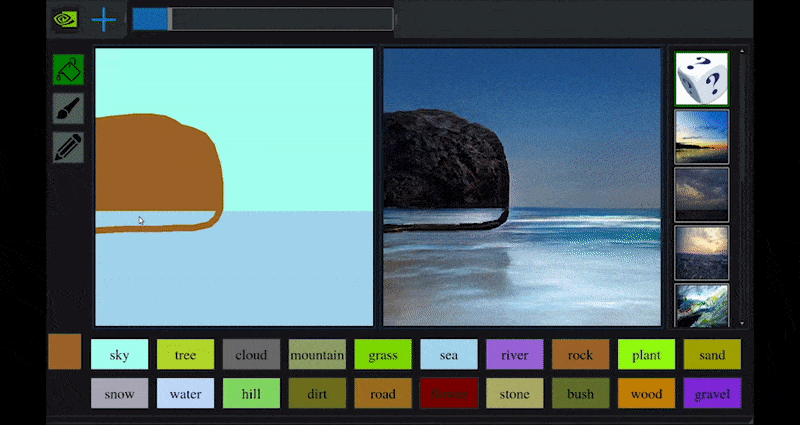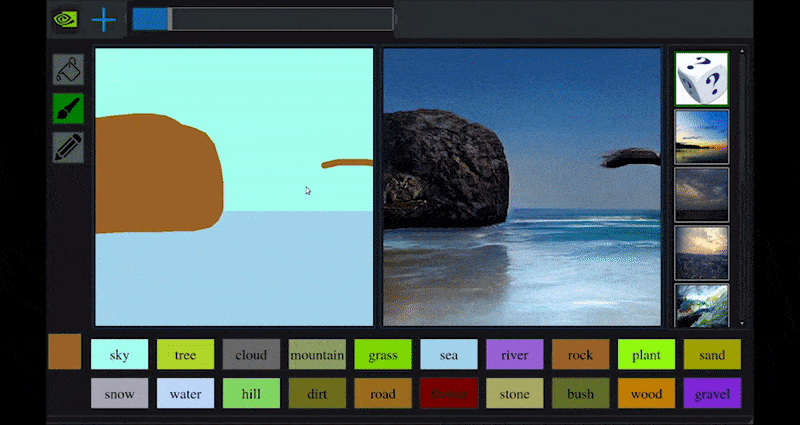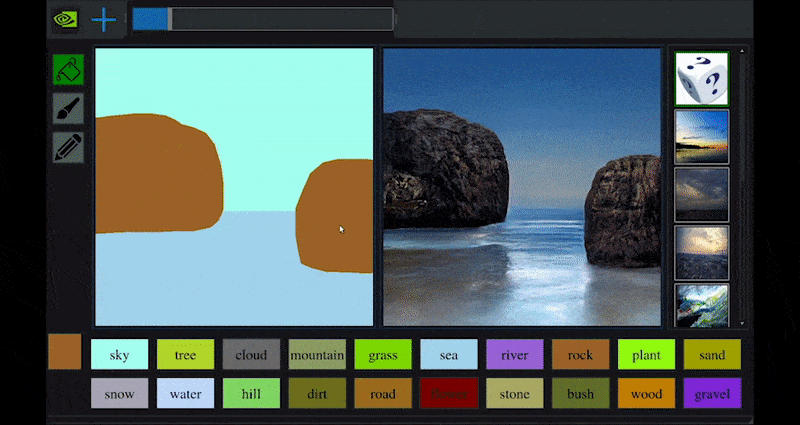
Omtrentlige skitser oversættes til rigtige landskabsbilleder via NVIDIA’s GauGAN og nu NVIDIA Canvas-applikationen. Kilde: https://rossdawson.com/futurist/implications-of-ai/future-of-ai-image-synthesis/
Ligesom multiple systemer som DeepFacePencil har brugt samme princip til at oprette skitseinduceret fotorealistisk billedgenerering for forskellige domæner.

Arkitekturen af DeepFacePencil.
Forenkling af skitse-til-billede
Den nye artikels GAN-skitsningstilgang søger at fjerne den betydelige byrde af dataindsamling og kurering, der typisk er involveret i udviklingen af GAN-billedrammer, ved at bruge brugerinput til at definere, hvilken undermængde af billeder der skal udgøre træningsdataene.
Systemet er designet til at kræve kun et lille antal inputskitser for at kalibrere rammen. Systemet omvender effektivt funktionaliteten af PhotoSketch, et fælles forskningsinitiativ fra 2019 af forskere fra Carnegie Mellon, Adobe, Uber ATG og Argo AI, der er inkorporeret i det nye arbejde. PhotoSketch var designet til at oprette kunstneriske skitser fra billeder og indeholder allerede den effektive kortlægning af vagt>specifik billedskabelseforhold.
For genereringsdelen af processen ændrer den nye metode kun vægtningerne af StyleGAN2. Da billeddataene, der bruges, kun er en undermængde af den samlede tilgængelige data, opnås ønskede resultater ved blot at ændre kortlægningsnetværket.
Metoden blev evalueret på en række populære underdomæner, herunder heste, kirker og katte.

Princeton Universitets 2016 LSUN-datasæt blev brugt som det centrale materiale, hvorfra at udlede mål-underdomæner. For at etablere et skitsekortlægningsystem, der er robust over for de ekscentriciteter af virkelige brugerinputskitser, blev systemet trænet på billeder fra QuickDraw-datasættet udviklet af Microsoft mellem 2021-2016.
Selv om skitsekortlægning mellem PhotoSketch og QuickDraw er ret forskellige, fandt forskerne, at deres ramme fungerer godt i at overskride dem ret let på relativt simple stillinger, selv om mere komplicerede stillinger (såsom katte, der ligger ned) viser sig at være en større udfordring, mens meget abstrakt brugerinput (f.eks. overordentligt grove tegninger) også hæmmer kvaliteten af resultaterne.

Latent rum og naturlig billedredigering
Forskerne udviklede to applikationer baseret på det centrale arbejde: latent rumredigering og billedredigering. Latent rumredigering tilbyder fortolkelige brugerkontroller, der faciliteres på træningstidspunktet, og giver en bred variation, samtidig med at de forbliver tro mod måldomænet og behageligt konsekvent på tværs af variationer.

Jævn latent ruminterpolation med de brugerdefinerede modeller af GAN-skitsning.
Den latente rumredigering komponent blev drevet af 2020 GANSpace-projektet, et fælles initiativ fra Aalto Universitet, Adobe og NVIDIA.
Et enkelt billede kan også indsættes i den tilpassede model, hvilket giver mulighed for naturlig billedredigering. I denne applikation indsættes et enkelt billede projiceret til den tilpassede GAN, ikke kun giver direkte redigering, men også bevare højere niveau latent rumredigering, hvis dette også er blevet brugt.

Her indsættes et virkeligt billede som input til GAN (katmodel), der redigerer input til at matche indsendte skitser. Dette giver billedredigering via skitsning.
Selv om det er konfigurerbart, er systemet ikke designet til at fungere i realtid, i hvert fald ikke i forhold til træning og kalibrering. For tiden kræver GAN-skitsning 30.000 træningsiterationer. Systemet kræver også adgang til den oprindelige træningsdata for den oprindelige model.
I tilfælde, hvor datasættet er open source, og har en licens, der tillader lokal kopiering, kan dette være muligt ved at inkludere kilde-dataene i en lokal installeret pakke, selv om dette ville tage betydelig diskplads; eller ved at få adgang til eller behandle data på fjernbasis via en cloud-baseret tilgang, hvilket introducerer netværks-overhead og (i tilfælde af, at behandlingen faktisk finder sted i skyen) muligvis beregningsomkostninger.

Transformationer fra tilpassede FFHQ-modeller trænet på kun 4 menneskeskabte skitser.












