
Kunstig intelligens
Deepfake-detektorer forfølger ny jord: Latent diffusionsmodeller og GAN'er

Udtalelse På det seneste har forskningsmiljøet for deepfake-detektion, som siden slutningen af 2017 næsten udelukkende har været beskæftiget med autoindkodning-baseret ramme, der havde premiere på det tidspunkt til sådan offentlig ærefrygt (og forfærdelse), er begyndt at interessere sig for kriminalteknisk interesse for mindre stillestående arkitekturer, bl.a latent diffusion modeller som f.eks DALL-E2 og Stabil diffusionsåvel som output fra generative modstridende netværk (GANS). For instance, in June, UC Berkeley offentliggjorde resultaterne af sin forskning i udviklingen af en detektor til output fra den på det tidspunkt dominerende DALL-E 2.
Det, der ser ud til at drive denne voksende interesse, er det pludselige evolutionære spring i mulighederne og tilgængeligheden af latente diffusionsmodeller i 2022 med lukket kildekode og begrænset adgang frigive af DALL-E 2 i foråret, efterfulgt i sensommeren af det opsigtsvækkende open source af stabil diffusion ved stabilitet.ai.
GANs har også været længe studeret i denne sammenhæng, dog mindre intensivt, da det er meget vanskeligt at bruge dem til at overbevise og udarbejde videobaserede genskabelser af mennesker; i hvert fald sammenlignet med de efterhånden ærværdige autoencoder-pakker som f.eks ansigtsbytte og DeepFaceLab – og sidstnævntes livestreamende fætter, DeepFaceLive.
Flytning af billeder
I begge tilfælde ser den galvaniserende faktor ud til at være udsigten til en efterfølgende udviklingssprint for video syntese. Starten af oktober – og 2022's store konferencesæson – var præget af en lavine af pludselige og uventede løsninger på forskellige langvarige videosyntese-fejl: ikke før havde Facebook frigivet prøver af sin egen tekst-til-video-platform, endte Google Research hurtigt overdøvede den første anerkendelse ved at annoncere sin nye Imagen-to-Video T2V-arkitektur, der er i stand til at udsende høj opløsning optagelser (omend kun via et 7-lags netværk af opskalere).
Hvis du tror, at den slags kommer i tre, så overvej også stability.ai's gådefulde løfte om, at 'video kommer' til Stable Diffusion, tilsyneladende senere på året, mens Stable Diffusion-medudvikleren Runway har afgivet et lignende løfte, selvom det er uklart, om de henviser til det samme system. Det Discord besked fra Stabilitets administrerende direktør Emad Mostaque også lovet 'lyd, video [og] 3d'.
Hvad med et ude af det blå udbud af flere nye Lydgenereringsrammer (nogle baseret på latent diffusion) og en ny diffusionsmodel, der kan generere autentisk karakterbevægelse, Ideen om, at 'statiske' rammer som gans og diffusorer endelig vil indtage deres plads som støtte tillæg til eksterne animationsrammer begynder at vinde rigtig indpas.
Kort sagt virker det sandsynligt, at den hårde verden af autoencoder-baserede videodeepfakes, som kun effektivt kan erstatte den centrale del af et ansigt, kunne på dette tidspunkt næste år være formørket af en ny generation af diffusionsbaserede deepfake-kompatible teknologier – populære, open source-tilgange med potentiale til fotorealistisk at forfalske ikke bare hele kroppe, men hele scener.
Af denne grund er anti-deepfake-forskningssamfundet måske begyndt at tage billedsyntese alvorligt og indse, at det måske tjener flere formål end blot at skabe falske LinkedIn profilbilleder; og det, hvis alle deres vanskelige latente rum kan udføre i form af tidsmæssig bevægelse er at fungere som en rigtig god teksturgengiver, det kan faktisk være mere end nok.
Blade Runner
De seneste to artikler om henholdsvis latent diffusion og GAN-baseret deepfake-detektion er hhv. DE-FAKE: Detektering og tilskrivning af falske billeder genereret af tekst-til-billede-diffusionsmodeller, et samarbejde mellem CISPA Helmholtz Center for Information Security og Salesforce; og BLADERUNNER: Hurtig modforanstaltning til syntetiske (AI-genererede) StyleGAN-ansigter, fra Adam Dorian Wong ved MIT's Lincoln Laboratory.
Inden dens nye metode forklares, tager sidstnævnte papir noget tid til at undersøge tidligere tilgange til at bestemme, om et billede blev genereret af et GAN eller ej (papiret omhandler specifikt NVIDIAs StyleGAN-familie).
'Brady Bunch'-metoden – måske en meningsløs reference for alle, der ikke så tv i 1970'erne, eller som gik glip af 1990'ernes filmatiseringer - identificerer GAN-forfalsket indhold baseret på de faste positioner, som bestemte dele af et GAN-ansigt helt sikkert vil indtage, på grund af den rote og skabelonkarakter af 'produktions proces'.

'Brady Bunch'-metoden fremsat af en webcast fra SANS-instituttet i 2022: en GAN-baseret ansigtsgenerator vil i visse tilfælde udføre en usandsynlig ensartet placering af visse ansigtstræk, der modsiger billedets oprindelse. Kilde: https://arxiv.org/ftp/arxiv/papers/2210/2210.06587.pdf
En anden nyttig kendt indikation er StyleGANs hyppige manglende evne til at gengive flere ansigter (første billede nedenfor), hvis det er nødvendigt, såvel som dets mangel på talent inden for tilbehørskoordinering (midterste billede nedenfor), og en tendens til at bruge en hårgrænse som starten på en improviseret hat (tredje billede nedenfor).

Den tredje metode, som forskeren gør opmærksom på, er fotooverlejring (et eksempel kan ses i vores artikel i august om AI-støttet diagnose af psykiske lidelser), som bruger kompositorisk 'billedblanding'-software såsom CombineZ-serien til at sammenkæde flere billeder til et enkelt billede, hvilket ofte afslører underliggende fællestræk i strukturen - en potentiel indikation på syntese.

Arkitekturen, der foreslås i det nye papir, har titlen (muligvis imod alle SEO-råd) Blade Runner, med henvisning til Voight-Kampff test der afgør, om antagonister i sci-fi-serien er 'falske' eller ej.
Pipelinen er sammensat af to faser, hvoraf den første er PapersPlease-analysatoren, som kan evaluere data skrabet fra kendte GAN-face-websteder såsom thispersondoesnotexist.com, eller generated.photos.

Selvom en nedskæret version af koden kan inspiceres på GitHub (se nedenfor) er der få detaljer om dette modul, bortset fra at OpenCV og DLIB bruges til at skitsere og detektere ansigter i det indsamlede materiale.
Det andet modul er Blandt os detektor. Systemet er designet til at søge efter koordineret øjenplacering i fotos, et vedvarende træk ved StyleGAN's ansigtsoutput, typisk i 'Brady Bunch'-scenariet beskrevet ovenfor. AmongUs er drevet af en standard 68-vartegnsdetektor.

Ansigtspunktannoteringer via Intelligent Behavior Understanding Group (IBUG), hvis ansigts vartegnplotkode bruges i Blade Runner-pakken.
AmongUs afhænger af forudtrænede vartegn baseret på de kendte 'Brady-bunch'-koordinater fra PapersPlease og er beregnet til brug mod levende, web-vendte prøver af StyleGAN-baserede ansigtsbilleder.
Blade Runner, foreslår forfatteren, er en plug-and-play-løsning beregnet til virksomheder eller organisationer, der mangler ressourcer til at udvikle interne løsninger til den slags deepfake-detektion, der behandles her, og en 'stop-gap-foranstaltning til at købe tid til mere permanente modforanstaltninger«.
Faktisk er der ikke mange skræddersyede i en sikkerhedssektor, der er så ustabil og hurtigt voksende or off-the-rack cloud-leverandørløsninger, som en virksomhed med mangel på ressourcer i øjeblikket kan henvende sig til med tillid.
Skønt Blade Runner klarer sig dårligt imod bebrillet StyleGAN-falskede mennesker, dette er et relativt almindeligt problem på tværs af lignende systemer, som forventer at kunne evaluere øjenafgrænsninger som centrale referencepunkter, skjult i sådanne tilfælde.
En reduceret version af Blade Runner har været frigivet to open source on GitHub. Der findes en mere funktionsrig proprietær version, som kan behandle flere fotos i stedet for det enkelte foto pr. operation af open source-lageret. Forfatteren har til hensigt, siger han, at opgradere GitHub-versionen til den samme standard med tiden, som tiden tillader det. Han indrømmer også, at StyleGAN sandsynligvis vil udvikle sig ud over dets kendte eller nuværende svagheder, og softwaren vil ligeledes skulle udvikle sig i tandem.
DE-FAKE
DE-FAKE-arkitekturen har ikke kun til formål at opnå 'universel detektion' for billeder produceret af tekst-til-billede-diffusionsmodeller, men at tilvejebringe en metode til at skelne som latent diffusion (LD) model producerede billedet.
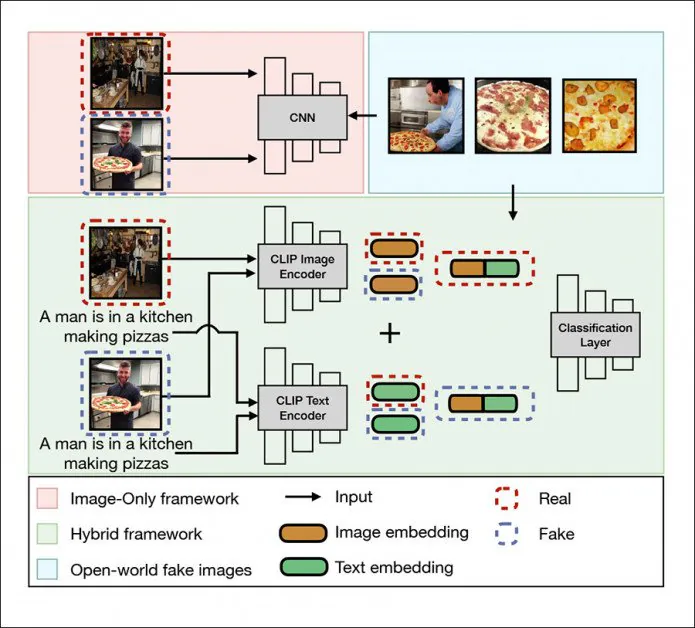
Den universelle detektionsramme i de-fake adresserer lokale billeder, en hybridramme (grøn) og Open World Images (blå). Kilde: http://export.arxiv.org/pdf/2210.06998
For at være ærlig er dette i øjeblikket en ret let opgave, da alle de populære LD-modeller – lukket eller åben kildekode – har bemærkelsesværdige kendetegn.
Derudover deler de fleste nogle fælles svagheder, såsom en tilbøjelighed til at skære hoveder af på grund af vilkårlig måde at ikke-kvadratiske web-skrabede billeder optages i de massive datasæt, som driver systemer som DALL-E 2, Stable Diffusion og MidJourney:

Latente diffusionsmodeller kræver, ligesom alle computervisionsmodeller, kvadratisk input; men den samlede web-skrabning, der giver næring til LAION5B-datasættet, tilbyder ingen "luksusekstra" såsom evnen til at genkende og fokusere på ansigter (eller noget andet), og afkorter billeder ganske brutalt i stedet for at udfylde dem (hvilket ville beholde hele kilden billede, men i en lavere opløsning). Når de er trænet i, bliver disse 'afgrøder' normaliserede og forekommer meget hyppigt i outputtet af latente diffusionssystemer såsom stabil diffusion. Kilder: https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac og Stable Diffusion.
DE-FAKE er beregnet til at være algoritme-agnostisk, et længe elsket mål for autoencoder anti-deepfake forskere, og lige nu et ganske opnåeligt mål med hensyn til LD-systemer.
Arkitekturen bruger OpenAI's Contrastive Language-Image Pretraining (CLIP) multimodalt bibliotek – et væsentligt element i stabil diffusion og hurtigt ved at blive hjertet i den nye bølge af billed-/videosyntesesystemer – som en måde at udtrække indlejringer fra 'smedede' LD-billeder og træne en klassifikator på de observerede mønstre og klasser.
I et mere 'black box'-scenarie, hvor de PNG-bidder, der indeholder information om genereringsprocessen, længe er blevet fjernet ved at uploade processer og af andre årsager, bruger forskerne Salesforce BLIP-ramme (også en komponent i mindst en Distribution af stabil diffusion) for at 'blindt' afstemme billederne for den sandsynlige semantiske struktur af prompterne, der skabte dem.

Forskerne brugte Stable Diffusion, Latent Diffusion (i sig selv et diskret produkt), GLIDE og DALL-E 2 til at udfylde et trænings- og testdatasæt, der udnytter MSCOCO og Flickr30k.
Normalt ville vi kigge ret omfattende på resultaterne af forskernes eksperimenter til en ny ramme; men i sandhed ser DE-FAKEs resultater sandsynligvis ud til at være mere nyttige som et fremtidigt benchmark for senere iterationer og lignende projekter, snarere end som en meningsfuld målestok for projektsucces i betragtning af det flygtige miljø, det opererer i, og at systemet konkurrerer imod i avisens forsøg er næsten tre år gammel – fra dengang billedsyntesescenen virkelig var begyndende.

To billeder længst til venstre: den "udfordrede" forudgående ramme, der opstod i 2019, klarede sig forudsigeligt mindre godt i forhold til DE-FAKE (to billeder længst til højre) på tværs af de fire testede LD-systemer.
Holdets resultater er overvældende positive af to grunde: der er sparsomt tidligere arbejde at sammenligne det med (og slet ingen, der giver en rimelig sammenligning, dvs. det dækker de blot tolv uger siden Stable Diffusion blev frigivet til open source).
For det andet, som nævnt ovenfor, selv om LD-billedsyntesefeltet udvikler sig med eksponentiel hastighed, vandmærker outputindholdet af nuværende tilbud sig effektivt på grund af sine egne strukturelle (og meget forudsigelige) mangler og excentriciteter – hvoraf mange sandsynligvis vil blive afhjulpet, i det mindste i tilfælde af stabil diffusion ved frigivelsen af det bedre ydende 1.5 kontrolpunkt (dvs. den 4 GB trænede model, der driver systemet).
Samtidig har Stability allerede indikeret, at den har en klar køreplan for V2 og V3 af systemet. I lyset af de overskrifter, der fanger begivenheder i de sidste tre måneder, er enhver virksomheds-torpor fra OpenAI's og andre konkurrerende aktørers side i billedsynteseområdet sandsynligvis blevet fordampet, hvilket betyder, at vi kan forvente et tilsvarende hurtigt fremskridt også i lukket kilde billedsyntese rum.
Først offentliggjort 14. oktober 2022.















