Kunstig intelligens
AudioSep : Adskil Noget Du Beskriver
LASS eller Language-queried Audio Source Separation er det nye paradigme for CASA eller Computational Auditory Scene Analysis, der sigter mod at adskille en målsætning lyd fra en given blanding af lyd ved hjælp af en naturlig sprogforespørgsel, der giver den naturlige, men skalerbare grænseflade for digitale lydopgaver og -applikationer. Selvom LASS-rammerne har udviklet sig betydeligt i de seneste år i forhold til at opnå ønsket præstation på bestemte lydkilder som musikinstrumenter, er de ikke i stand til at adskille målsætningslyden i det åbne domæne.
AudioSep, er en grundlæggende model, der sigter mod at løse de nuværende begrænsninger i LASS-rammerne ved at aktivere målsætningslydadskillelse ved hjælp af naturlige sprogforespørgsler. Udviklerne af AudioSep-rammen har trænet modellen omfattende på en bred vifte af store multimodale datasæt og har vurderet rammens præstation på en bred vifte af lydopgaver, herunder adskillelse af musikinstrumenter, lydhændelsesadskillelse og forbedring af tale iblandt mange andre. Den initiale præstation af AudioSep tilfredsstiller benchmarkene, da den demonstrerer imponerende zero-shot-læringsfærdigheder og leverer stærk lydadskillelsespræstation.
I denne artikel vil vi dykke dybere ind i AudioSep-rammens funktionsmåde, da vi vil vurdere modellens arkitektur, datasættene brugt til træning og vurdering samt de væsentlige begreber, der er involveret i AudioSep-modellens funktionsmåde. Så lad os begynde med en grundlæggende introduktion til CASA-rammen.
CASA, USS, QSS, LASS-rammer : Grundlaget for AudioSep
CASA eller Computational Auditory Scene Analysis-rammen er en ramme, der bruges af udviklere til at designe maskinlytningssystemer, der har evnen til at opfatte komplekse lydmiljøer på en måde, der ligner den måde, mennesker opfatter lyd ved hjælp af deres auditive systemer. Lydadskillelse, med særlig fokus på målsætningslydadskillelse, er et grundlæggende forskningsområde inden for CASA-rammen, og det sigter mod at løse ”cocktail party-problemet” eller adskille virkelige lydoptagelser fra individuelle lydkildere eller -filer. Betydningen af lydadskillelse kan tilskrives primært dets vidt udbredte anvendelser, herunder musiklydkildeadskillelse, lydkildeadskillelse, taleforbedring, målsætningslydidentifikation og meget mere.
Det meste af arbejdet med lydadskillelse, der er udført i fortiden, drejer sig primært om adskillelse af en eller flere lydkilder, som musikadskillelse eller taleadskillelse. En ny model med navnet USS eller Universal Sound Separation sigter mod at adskille vilkårlige lyde i virkelige lydoptagelser. Det er dog en udfordrende og begrænsende opgave at adskille hver lydkilde fra en lydblanding, primært på grund af den brede vifte af forskellige lydkilder, der findes i verden, hvilket er den primære årsag til, at USS-metoden ikke er gennemførlig for virkelige anvendelser, der fungerer i realtid.
En gennemførlig alternativ til USS-metoden er QSS eller Query-baseret Lydadskillelse-metoden, der sigter mod at adskille en enkelt eller målsætningslydkilde fra lydblandingen på basis af en bestemt sæt forespørgsler. Takket være dette giver QSS-rammen udviklere og brugere mulighed for at udtrække de ønskede kilder af lyd fra blandingen på basis af deres krav, hvilket gør QSS-metoden til en mere praktisk løsning for digitale virkelige anvendelser som multimedieindholdsbearbejdning eller lydbearbejdning.
Desuden har udviklere nyligt foreslået en udvidelse af QSS-rammen, LASS-rammen eller Language-queried Audio Source Separation-rammen, der sigter mod at adskille vilkårlige lydkilder fra en lydblanding ved hjælp af naturlige sprogbeskrivelser af målsætningslydkilden. Da LASS-rammen giver brugerne mulighed for at udtrække målsætningslydkilderne ved hjælp af et sæt naturlige sprogforespørgsler, kan det muligvis blive et kraftfuldt værktøj med vidt udbredte anvendelser i digitale lydanvendelser. Når det sammenlignes med traditionelle lydforespørgsler eller vision-forespørgsler, giver brug af naturlige sprogforespørgsler til lydadskillelse en større grad af fordel, da det tilføjer fleksibilitet og gør erhvervelse af forespørgselsinformation meget lettere og mere bekvem. Desuden, når det sammenlignes med mærkeforespørgselsbaseret lydadskillelse-rammer, der bruger et foruddefineret sæt af instruktioner eller forespørgsler, begrænser LASS-rammen ikke antallet af inputforespørgsler og har mulighed for at generalisere til åbent domæne uden problemer.
Oprindeligt afhænger LASS-rammen af overvåget læring, hvor modellen trænes på et sæt af mærkede lyd-tekst-par-data. Det primære problem med denne tilgang er den begrænsede tilgængelighed af annoterede og mærkede lyd-tekst-data. For at reducere afhængigheden af LASS-rammen af annoterede lyd-tekst-mærkede data, trænes modellerne ved hjælp af multimodal overvåget læringstilgang. Det primære formål med at bruge en multimodal overvåget tilgang er at bruge multimodal kontrastiv fortræning-modeller som CLIP eller Contrastive Language Image Pre Training-model som forespørgselskodifikator for rammen. Da CLIP-rammen har evnen til at justere tekst-embeddinger med andre modaliteter som lyd eller vision, giver det udviklere mulighed for at træne LASS-modellerne ved hjælp af data-rige modaliteter og giver mulighed for interferens med tekstdata i en zero-shot-indstilling. De nuværende LASS-rammer bruger dog små datasæt til træning, og anvendelser af LASS-rammen på hundredvis af potentielle domæner er endnu ikke udforsket.
For at løse de nuværende begrænsninger, som LASS-rammerne står over for, har udviklere introduceret AudioSep, en grundlæggende model, der sigter mod at adskille lyd fra en lydblanding ved hjælp af naturlige sprogbeskrivelser. Det nuværende fokus for AudioSep er at udvikle en fortrænet lydadskillelsesmodel, der udnytter eksisterende store multimodale datasæt for at muliggøre generalisering af LASS-modeller i åbent domæne-anvendelser. For at sammenfatte er AudioSep-modellen: ”En grundlæggende model for universel lydadskillelse i åbent domæne ved hjælp af naturlige sprogforespørgsler eller beskrivelser trænet på store multimodale datasæt”.
AudioSep : Nøglekomponenter og Arkitektur
AudioSep-rammens arkitektur består af to nøglekomponenter: en tekstkodifikator og en adskillelsesmodel.
Tekstkodifikatoren
AudioSep-rammen bruger en tekstkodifikator af CLIP eller Contrastive Language Image Pre Training-model eller CLAP eller Contrastive Language Audio Pre Training-model til at udtrække tekst-embeddinger inden for en naturlig sprogforespørgsel. Input-tekstforespørgslen består af en sekvens af ”N” token, der herefter bearbejdes af tekstkodifikatoren til at udtrække tekst-embeddinger for den givne input-sprogforespørgsel. Tekstkodifikatoren bruger en stak af transformer-blokke til at kodificere input-teksttoken, og output-repræsentationerne samles efter, at de er passeret gennem transformer-lagene, hvilket resulterer i udviklingen af en D-dimensionel vektorrepræsentation med fast længde, hvor D svarer til dimensionerne af CLAP eller CLIP-modellerne, mens tekstkodifikatoren er frosset under træningsperioden.
CLIP-modellen er fortrænet på et stort datasæt af billed-tekst-par-data ved hjælp af kontrastiv læring, hvilket er den primære årsag til, at dens tekstkodifikator lærer at kortlægge tekstbeskrivelser på den semantiske rum, der også deles af visuelle repræsentationer. Fordelen, som AudioSep opnår ved at bruge CLIP-tekstkodifikatoren, er, at den kan skaleres op eller trænes fra ukodificerede lyd-visualiseringsdata ved hjælp af visuelle embeddinger som en alternativ, hvilket muliggør træning af LASS-modeller uden krav om annoterede eller mærkede lyd-tekst-data.
CLAP-modellen fungerer på samme måde som CLIP-modellen og bruger en kontrastiv læringsmål til at bruge en tekst- og en lydkodifikator til at forbinde lyd og sprog, hvilket bringer tekst- og lyd-beskrivelser på et lyd-tekst-ladt rum sammen.
Adskillelsesmodel
AudioSep-rammen bruger en frekvens-domæne ResUNet-model, der fødes en blanding af lydklip som adskillelsesrygrod for rammen. Rammen fungerer ved først at anvende en STFT eller en Short-Time Fourier Transform på waveformet for at udtrække et komplekst spektrogram, et størrelses-spektrogram og fasen af X. Modellen følger herefter samme indstilling og konstruerer en encoder-decoder-netværk til at bearbejde størrelses-spektrogrammet.
ResUNet-encoder-decoder-netværket består af 6 residual-blokke, 6 decoder-blokke og 4 flaskehalssblokke. Spektrogrammet i hver encoder-blok bruger 4 residual-konventionelle blokke til at nedsample sig selv til en flaskehalssfunktion, mens decoder-blokke bruger 4 residual-dekonvolutionsblokke til at opnå adskillelseskomponenterne ved at opsample funktionerne. Herefter etablerer hver af encoder-blokke og dens korresponderende decoder-blokke en hop-forbindelse, der fungerer på samme optimerings- eller nedsample-hastighed. Residual-blokken i rammen består af 2 Leaky-ReLU-aktiveringslag, 2 batch-normaliseringslag og 2 CNN-lag, og desuden introducerer rammen en ekstra residual-genvej, der forbinder input og output af hver enkelt residual-blok. ResUNet-modellen tager det komplekse spektrogram X som input og producerer størrelses-masken M som output med faseresiduum, der er betinget af tekst-embeddinger, der kontrollerer størrelsen af skala og rotation af vinklen på spektrogrammet. Det adskilte komplekse spektrogram kan herefter udtrækkes ved at multiplicere den forudsigede størrelsesmaske og faseresiduum med STFT (Short-Time Fourier Transform) af blandingen.

I sin ramme bruger AudioSep en FiLm eller Feature-wise Linearly moduleret lag til at forbinde adskillelsesmodellen og tekstkodifikatoren efter udrulning af konvolutionsblokkene i ResUNet.
Træning og Tab
Under træningen af AudioSep-modellen bruger udviklerne støjforstærkning-metoden og træner AudioSep-rammen fra ende til ende ved hjælp af en L1-tab-funktion mellem grundsandheden og den forudsigede bølgeform.
Datasæt og Benchmark
Som nævnt i tidligere afsnit er AudioSep en grundlæggende model, der sigter mod at løse den nuværende afhængighed af LASS-modeller af annoterede lyd-tekst-par-datasæt. AudioSep-modellen er trænet på en bred vifte af datasæt for at udstyre den med multimodale læringsfærdigheder, og her er en detaljeret beskrivelse af datasættet og benchmarkene, der bruges af udviklerne til at træne AudioSep-rammen.
AudioSet
AudioSet er et svagt-mærket stort datasæt af lyd, der består af over 2 millioner 10-sekunders lydklip, der er udtrukket direkte fra YouTube. Hver lydklip i AudioSet-datasættet er kategoriseret af fraværet eller tilstedeværelsen af lydklasser uden specifikke tidspunktsdetaljer for lydhændelserne. AudioSet-datasættet har over 500 forskellige lydklasser, herunder naturlige lyde, menneskelige lyde, køretøjslyde og meget mere.
VGGSound
VGGSound-datasættet er et stort datasæt af visuelt-lyd, der ligesom AudioSet er udtrukket direkte fra YouTube, og det indeholder over 200.000 video-klip, hver med en længde på 10 sekunder. VGGSound-datasættet er kategoriseret i over 300 lydklasser, herunder menneskelige lyde, naturlige lyde, fuglelyde og mere. Brugen af VGGSound-datasætt sikrer, at objektet, der er ansvarligt for at producere målsætningslyden, også er beskrevet i den korresponderende visuelle klip.
AudioCaps
AudioCaps er det største offentligt tilgængelige lyd-underskriftsdatasæt, og det består af over 50.000 10-sekunders lydklip, der er udtrukket fra AudioSet-datasættet. Data i AudioCaps er inddelt i tre kategorier: træningsdata, testdata og valideringsdata, og lydklipene er menneskeligt-annoterede med naturlige sprogbeskrivelser ved hjælp af Amazon Mechanical Turk-platformen. Det er værd at bemærke, at hver lydklip i træningsdatasættet har en enkelt undertekst, mens data i test- og valideringsdatasættene hver har 5 grundsandheds-underskrifter.
ClothoV2
ClothoV2 er et lyd-underskriftsdatasæt, der består af klip, der er udtrukket fra FreeSound-platformen, og ligesom AudioCaps er hver lydklip menneskeligt-annoteret med naturlige sprogbeskrivelser ved hjælp af Amazon Mechanical Turk-platformen.
WavCaps
Ligesom AudioSet er WavCaps et svagt-mærket stort datasæt af lyd, der består af over 400.000 lydklip med undertekster, og en total køretid, der nærmer sig 7568 timers træningsdata. Lydklipene i WavCaps-datasættet er udtrukket fra en bred vifte af lydkilder, herunder BBC Sound Effects, AudioSet, FreeSound, SoundBible og mere.

Træningsdetaljer
Under træningsfasen sampler AudioSep-modellen tilfældigt to lydsegmenter fra to forskellige lydklip fra træningsdatasættet og herefter blander dem sammen for at skabe en træningsblanding, hvor længden af hvert lydsegment er omkring 5 sekunder. Modellen udtrækker herefter det komplekse spektrogram fra waveform-signalet ved hjælp af et Hann-vindu af størrelse 1024 med en 320 hop-størrelse.
Modellen bruger herefter tekstkodifikatoren af CLIP/CLAP-modellerne til at udtrække tekst-embeddinger med tekst-overvågning som standardkonfiguration for AudioSep. For adskillelsesmodellen bruger AudioSep-rammen en ResUNet-lag, der består af 30 lag, 6 encoder-blokke og 6 decoder-blokke, der ligner arkitekturen, der følges i den universelle lydadskillelse-ramme. Desuden har hver encoder-blok to konvolutionslag med en 3×3 kernel-størrelse, og antallet af output-funktioner af encoder-blokke er 32, 64, 128, 256, 512 og 1024 henholdsvis. Decoder-blokke dele symmetri med encoder-blokke, og udviklerne anvender Adam-optimizeren til at træne AudioSep-modellen med en batch-størrelse på 96.
Vurderingsresultater
På Sete Datasæt
Følgende figur sammenligner AudioSep-rammens præstation på sete datasæt under træningsfasen, herunder træningsdatasættet. Figuren nedenfor repræsenterer benchmark-vurderingsresultaterne af AudioSep-rammen, når den sammenlignes med baseline-systemer, herunder taleforbedringsmodeller, LASS og CLIP. AudioSep-modellen med CLIP-tekstkodifikator er repræsenteret som AudioSep-CLIP, mens AudioSep-modellen med CLAP-tekstkodifikator er repræsenteret som AudioSep-CLAP.

Som det kan ses i figuren, fungerer AudioSep-rammen godt, når den bruger lyd-underskrifter eller tekstmærker som input-forespørgsler, og resultaterne indikerer den overlegne præstation af AudioSep-rammen, når den sammenlignes med tidligere benchmark LASS og lydforespørgselsbaseret lydadskillelse-modeller.
På Usete Datasæt
For at vurdere AudioSep-modellens præstation i en zero-shot-indstilling fortsætter udviklerne med at vurdere præstationen på usete datasæt, og AudioSep-rammen leverer imponerende adskillelsespræstation i en zero-shot-indstilling, og resultaterne vises i figuren nedenfor.

Desuden viser billedet nedenfor resultaterne af at vurdere AudioSep-modellen mod Voicebank-Demand taleforbedring.

Vurderingen af AudioSep-rammen indikerer en stærk og ønsket præstation på usete datasæt i en zero-shot-indstilling, og det åbner dermed mulighed for at udføre lydoperationer på nye datafordelinger.
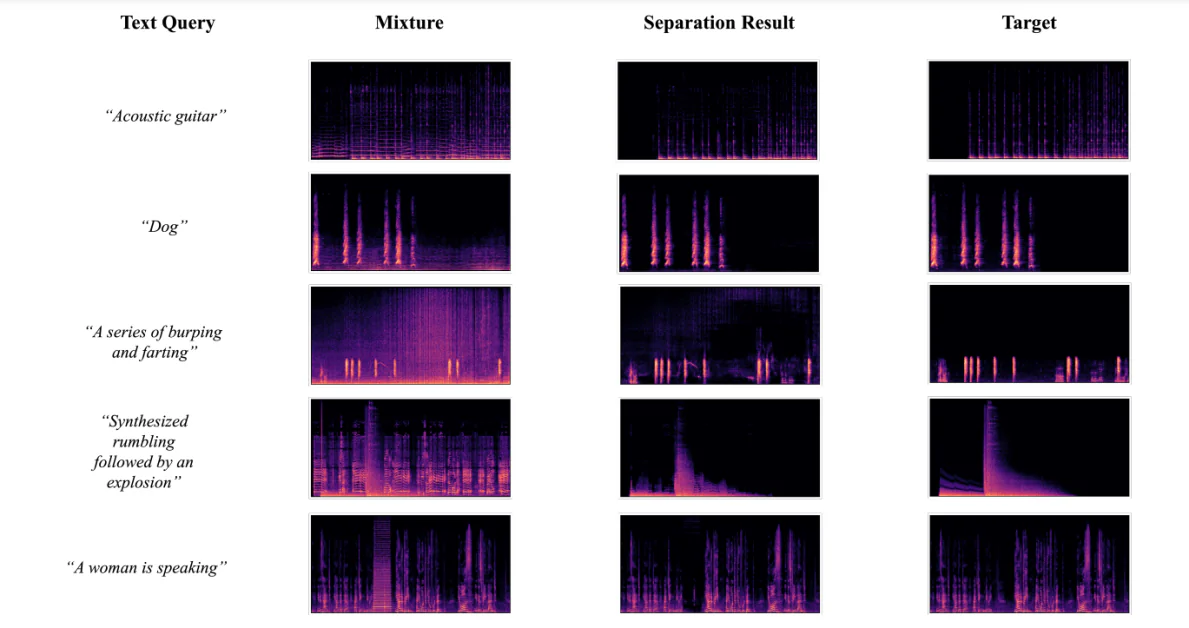
Visualisering af Adskillelsesresultater
Figuren nedenfor viser resultaterne, der opnås, når udviklerne bruger AudioSep-CLAP-rammen til at visualisere spektrogrammer for grundsandheds-målsætningslydkilder, lydblandinger og adskilte lydkilder ved hjælp af tekstforespørgsler af diverse lyde eller lyde. Resultaterne giver udviklerne mulighed for at observere, at spektrogrammets adskilte kilde-mønster er tæt på kilden af grundsandheden, hvilket yderligere støtter de objektive resultater, der opnås under eksperimenterne.
Sammenligning af Tekstforespørgsler
Udviklerne vurderer AudioSep-CLAP og AudioSep-CLIP på AudioCaps Mini, og udviklerne bruger AudioSet-hændelsesmærker, AudioCaps-underskrifter og gen-annoterede naturlige sprogbeskrivelser til at undersøge effekterne af forskellige forespørgsler, og figuren nedenfor viser et eksempel på AudioCaps Mini i aktion.

Konklusion
AudioSep er en grundlæggende model, der er udviklet med det formål at være en åbent domæne-universal lydadskillelse-ramme, der bruger naturlige sprogbeskrivelser til lydadskillelse. Som observeret under vurderingen er AudioSep-rammen i stand til at udføre zero-shot- og ubeskyttet læring uden problemer ved hjælp af lyd-underskrifter eller tekstmærker som forespørgsler. Resultaterne og vurderingspræstationen af AudioSep indikerer en stærk præstation, der overgår den nuværende tilstand af kunstig lydadskillelse-rammer som LASS, og det kan muligvis være i stand til at løse de nuværende begrænsninger i populære lydadskillelse-rammer.












