Kunstig intelligens
Andrew Ng kritiserer overfitting-kulturen i maskinlæring
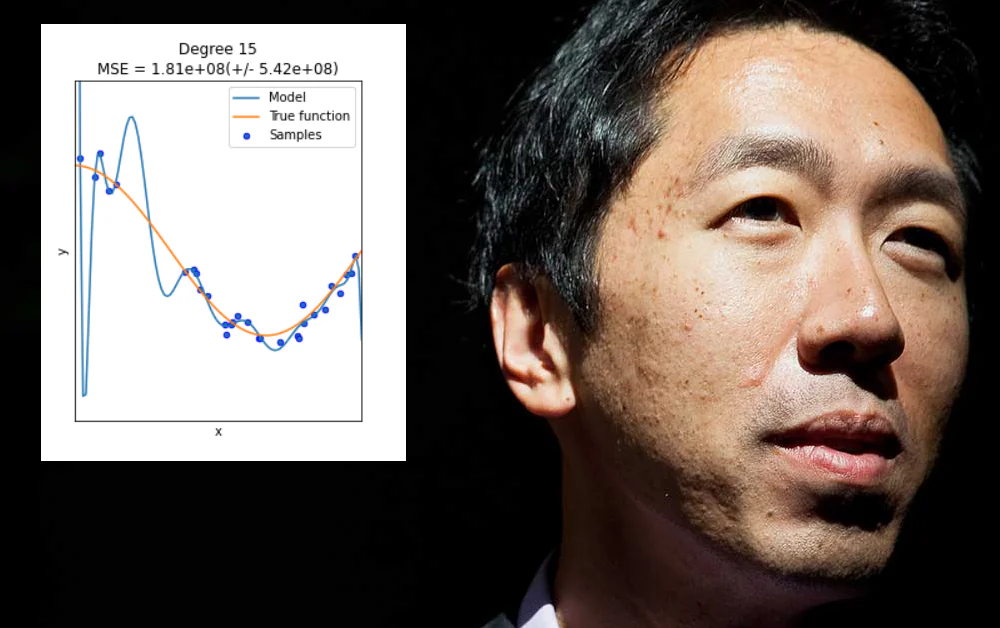
Andrew Ng, en af de mest indflydelsesrige stemmer i maskinlæring over det sidste årti, udtrykker nu bekymring over, i hvilken udstrækning sektoren lægger vægt på innovationer i modelarkitektur over data – og specifikt, i hvilken udstrækning det tillader ‘overfitting’-resultater at blive fremstillet som generaliserede løsninger eller fremskridt.
Dette er omfattende kritik af den nuværende maskinlæringkultur, der kommer fra en af dets højeste myndigheder, og har konsekvenser for tilliden til en sektor, der er ramt af frygt over en tredje sammenbrud af erhvervstillid til AI-udvikling i løbet af 60 år.
Ng, en professor ved Stanford University, er også en af grundlæggerne af deeplearning.ai, og i marts offentliggjorde han en skrivelse på organisationens website, der kondenserer en nylig tale af ham til et par kerneanbefalinger:
Først og fremmest, at forskningssamfundet skal ophøre med at klage over, at datarensning udgør 80% af udfordringerne i maskinlæring, og i stedet få ansvar for at udvikle solide MLOps-metodologier og -praksis.
For det andet, at det skal flytte sig væk fra de ‘lette sejre’, der kan opnås ved at overfitte data til en maskinlæringsmodel, så den fungerer godt på den model, men ikke generaliserer eller producerer en bredt anvendelig model.
At acceptere udfordringen i dataarkitektur og -kuratering
‘Min opfattelse’, skrev Ng, ‘er, at hvis 80 procent af vores arbejde er dataforberedelse, så er sikring af datakvalitet det vigtige arbejde for et maskinlæringshold.’
Han fortsatte:
‘I stedet for at regne med, at ingeniører tilfældigt finder den bedste måde at forbedre en dataset på, håber jeg, vi kan udvikle MLOps-værktøjer, der hjælper med at gøre opbygning af AI-systemer, herunder opbygning af højkvalitetsdatasets, mere gentagne og systematiske.
‘MLOps er et nyt felt, og forskellige mennesker definerer det på forskellige måder. Men jeg mener, at den vigtigste organisatoriske princip for MLOps-hold og -værktøjer skal være at sikre en konsekvent og højkvalitetsflow af data på alle stadier af et projekt. Dette vil hjælpe mange projekter med at gå mere glat.’
Under en live-streamet Q&A-session på Zoom i slutningen af april, adresserede Ng den anvendelige mangel i maskinlæringsanalyse-systemer for radiologi:
“Det viser sig, at når vi indsamler data fra Stanford Hospital, og derefter træner og tester på data fra det samme hospital, kan vi faktisk offentliggøre artikler, der viser, at [algoritmerne] er sammenlignelige med menneskelige radiologer i spotting bestemte tilstande.
“…[Når] du tager det samme model, det samme AI-system, til et ældre hospital ned ad gaden, med en ældre maskine, og teknikeren bruger en lidt anden billedprotokol, så vil data-drift forårsage, at AI-systemets præstation falder betydeligt. Til gengæld kan enhver menneskelig radiolog gå ned ad gaden til det ældre hospital og klare sig fint.”
Under-specifikation er ikke en løsning
Overfitting opstår, når en maskinlæringsmodel specifikt er designet til at tilpasse sig de særlige egenskaber af en bestemt dataset (eller af den måde, data er formateret på). Dette kan indebære, for eksempel, at specifikke vægte defineres, der vil producere gode resultater fra den dataset, men ikke ‘generaliserer’ på andre data.
I mange tilfælde er sådanne parametre defineret på ‘ikke-data’-aspekter af træningssættet, såsom den specifikke opløsning af den indsamlede information eller andre særheder, der ikke er garanteret at gentage sig på andre efterfølgende datasets.
Selv om det ville være rart, er overfitting ikke et problem, der kan løses ved blindt at udvide omfanget eller fleksibiliteten af dataarkitektur eller modeldesign, når hvad der faktisk er nødvendigt, er bredt anvendelige og højtydende funktioner, der vil fungere godt på tværs af en række data-miljøer – en mere kompliceret udfordring.
I almindelighed fører denne type ‘under-specifikation’ kun til de samme problemer, som Ng har beskrevet, hvor en maskinlæringsmodel fejler på usete data. Forskellen i dette tilfælde er, at modellen fejler ikke, fordi data eller dataformateringen er anderledes end den overfitning originale træningssæt, men fordi modellen er for fleksibel i stedet for for skrøbelig.
Sent i 2020 offentliggjorde artiklen Underspecification Presents Challenges for Credibility in Modern Machine Learning intens kritik af denne praksis og bar navnene på ikke færre end fyrre maskinlæringsforskere og -videnskabsmænd fra Google og MIT, blandt andre institutioner.
Artiklen kritiserer ‘shortcut-læring’ og observerer, hvordan underspecifikke modeller kan tage af i vilde retninger på grund af det tilfældige seed-punkt, hvor modeltræningen begynder. Bidragerne observerer:
‘Vi har set, at underspecifikation er almindelig i praktiske maskinlærings-pipelines på tværs af mange domæner. Faktisk, takket være underspecifikation, bestemmes substantielt vigtige aspekter af beslutningerne af tilfældige valg, såsom den tilfældige seed, der bruges til parameterinitialisering.’
Økonomiske konsekvenser af at ændre kulturen
Trods sin akademiske baggrund er Ng ikke en luftig akademiker, men har dyb og højt niveau industriel erfaring som medstifter af Google Brain og Coursera, som tidligere chief scientist for Big Data og AI hos Baidu, og som stifter af Landing AI, der administrerer 175 millioner USD for nye startups i sektoren.
Når han siger “Hele AI, ikke kun sundhedssektoren, har et proof-of-concept-to-production-gap”, er det ment som en vækkelser til en sektor, hvis nuværende niveau af hype og plettet historie har mere og mere karakteriseret det som en usikker langsigtede erhvervsinvestering, ramt af problemer med definition og omfang.
Likevel kan proprietære maskinlærings-systemer, der fungerer godt på stedet og fejler i andre miljøer, repræsentere den type markedstilgang, der kan belønne industriel investering. At præsentere ‘overfitting-problemet’ i sammenhæng med en erhvervsfare tilbyder en uærlig måde at monetisere erhvervslig investering i open source-forskning og at producere (effektivt) proprietære systemer, hvor replikation af konkurrenter er mulig, men problematisk.
Om denne tilgang vil fungere på lang sigt afhænger af, i hvilken udstrækning virkelige gennembrud i maskinlæring fortsat kræver stigende niveauer af investering, og om alle produktive initiativer vil uundgåeligt migrere til FAANG i en vis udstrækning på grund af de kolossale ressourcer, der er nødvendige for hosting og operationer.












