Kunstig intelligens
AI-understøttet objekteredigering med Google’s Imagic og Runway’s ‘Slet og Erstat’

Denne uge tilbyder to nye, men modsatrettede AI-drevne grafikalgoritmer nye måder for slutbrugere at foretage meget detaljerede og effektive ændringer af objekter i billeder.
Den første er Imagic, fra Google Research, i samarbejde med Israels Teknologiske Institut og Weizmann Institute of Science. Imagic tilbyder tekstbetinget, fin-granet redigering af objekter via finjustering af diffusionsmodeller.

Ændr det, du gerne vil, og lad resten være – Imagic lover granet redigering af kun de dele, du gerne vil ændre. Kilde: https://arxiv.org/pdf/2210.09276.pdf
Enhver, der nogensinde har forsøgt at ændre kun ét element i en Stable Diffusion-genreret billedrender, ved kun alt for godt, at for hvert succesfuldt redigeret element, vil systemet ændre fem ting, du gerne vil have, som de var. Det er en svaghed, der i øjeblikket har mange af de mest talentfulde SD-entusiaster konstant skiftende mellem Stable Diffusion og Photoshop for at fikse denne type ‘collateral damage’. Set fra dette synspunkt alene, synes Imagics præstationer bemærkelsesværdige.
På tidspunktet for skrivning mangler Imagic endnu en promotionsvideo, og med Google’s forsigtige holdning til at udgive ubegrænsede billedsynthesetools, er det usikkert, i hvilken udstrækning, hvis overhovedet, vi får mulighed for at teste systemet.
Den anden tilbud er Runway ML’s mere tilgængelige Slet og Erstat-funktion, en ny funktion i ‘AI Magic Tools’-sektionen af deres eksklusivt online-suite af maskinlæringsbaserede visuelle effektværktøjer.
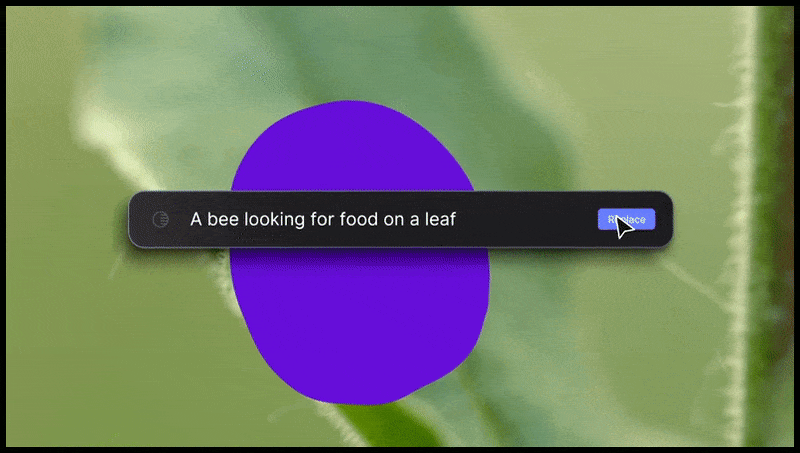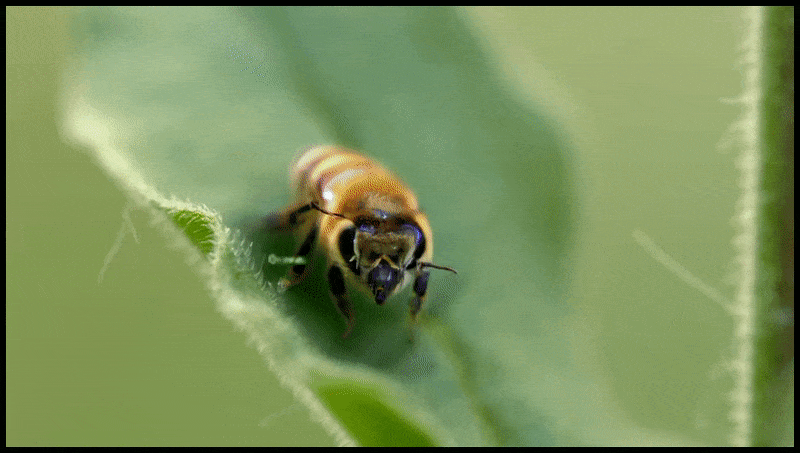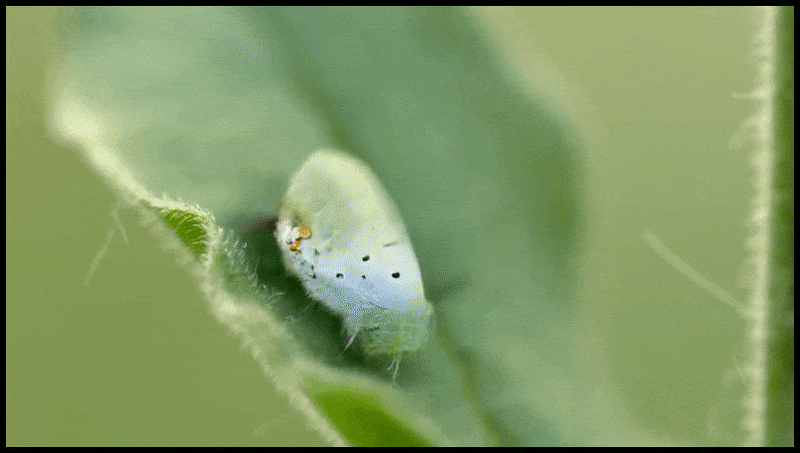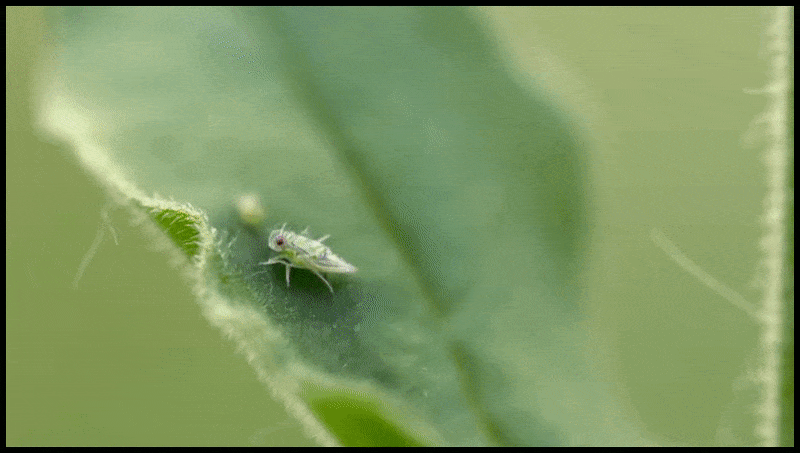
Runway ML’s Slet og Erstat-funktion, allerede set i en forhåndsvisning af et tekst-til-video-redigeringsystem. Kilde: https://www.youtube.com/watch?v=41Qb58ZPO60
Lad os se på Runway’s udgave først.
Slet og Erstat
Som Imagic, handler Slet og Erstat eksklusivt med stille billeder, selvom Runway har forhåndsvist den samme funktionalitet i et tekst-til-video-redigeringsløsning, der endnu ikke er udgivet:

Selvom alle kan teste den nye Slet og Erstat på billeder, er videoversionen endnu ikke offentligt tilgængelig. Kilde: https://twitter.com/runwayml/status/1568220303808991232
Runway ML har ikke offentliggjort detaljer om teknologierne bag Slet og Erstat, men hastigheden, hvormed du kan erstatte en husplante med en rimeligt overbevisende buste af Ronald Reagan, antyder, at en diffusionsmodel som Stable Diffusion (eller, langt mindre sandsynligt, en licenseret DALL-E 2) er motoren, der genopfinder objektet af din valg i Slet og Erstat.

At erstatte en husplante med en buste af The Gipper er ikke helt så hurtigt, men det er ret hurtigt. Kilde: https://app.runwayml.com/
Systemet har nogle DALL-E 2-type begrænsninger – billeder eller tekst, der flagrer Slet og Erstat-filtrene, vil udløse en advarsel om mulig konto-suspension i tilfælde af yderligere overtrædelser – praktisk talt en kopi af OpenAI’s politik for DALL-E 2.
Mange af resultaterne mangler de typiske ru kanter af Stable Diffusion. Runway ML er investorer og forskningspartnere i SD, og det er muligt, at de har trænet en proprietær model, der er overlegen i forhold til den åbne kilde 1.4 checkpoint-vejningsfaktorer, som resten af os i øjeblikket kæmper med (som mange andre udviklingsgrupper, hobby- og professionelle, i øjeblikket træner eller finjusterer Stable Diffusion-modeller).
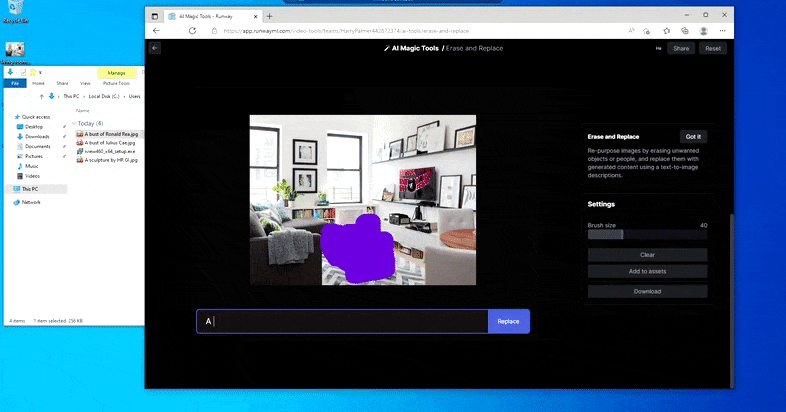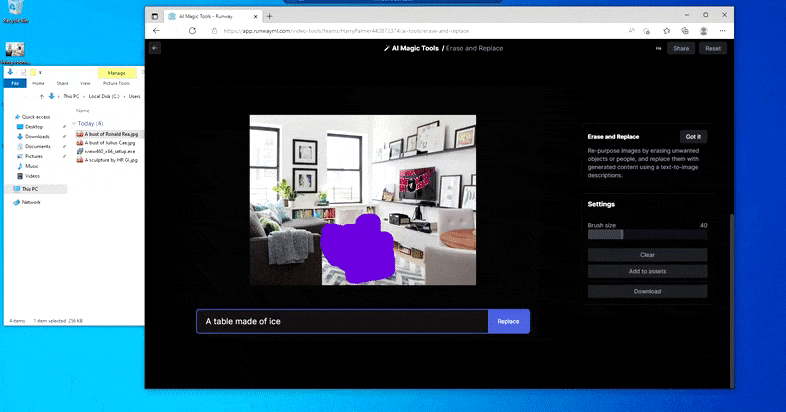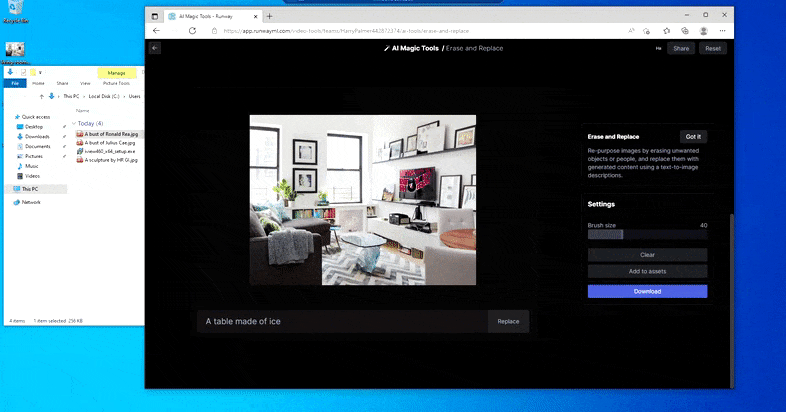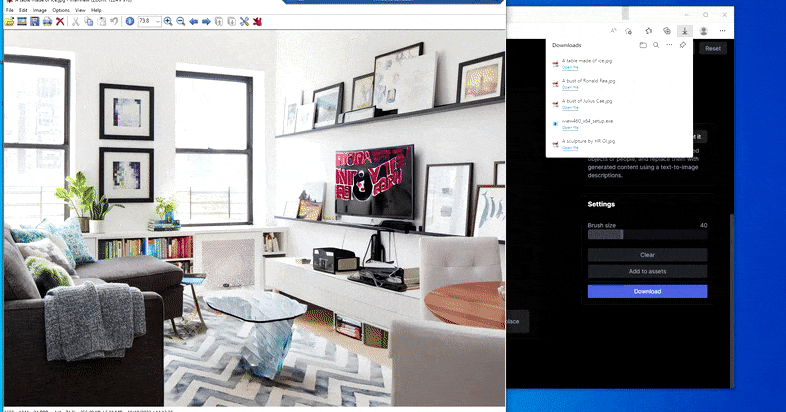
At erstatte en hjemmeborde med en ‘bord lavet af is’ i Runway ML’s Slet og Erstat.
Som Imagic (se nedenfor) er Slet og Erstat ‘objekt-orienteret’, som det være – du kan ikke bare slette en ‘tom’ del af billedet og inpainte det med resultatet af din tekstprompt; i den situation vil systemet blot spore den nærmeste synlige genstand langs maskens sigtelinje (såsom en væg eller en tv), og anvende transformationen der.
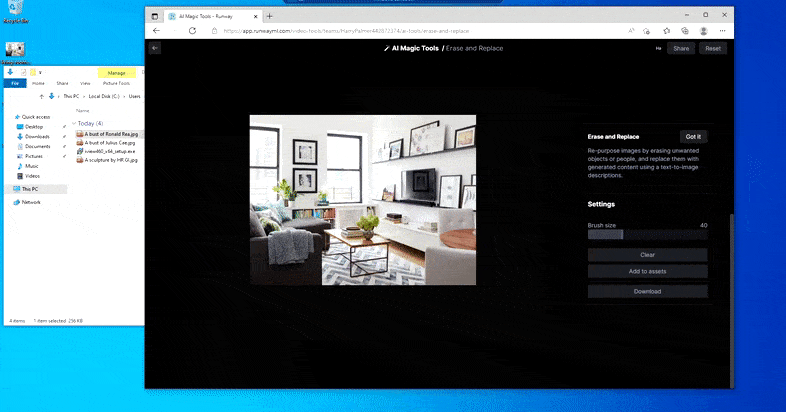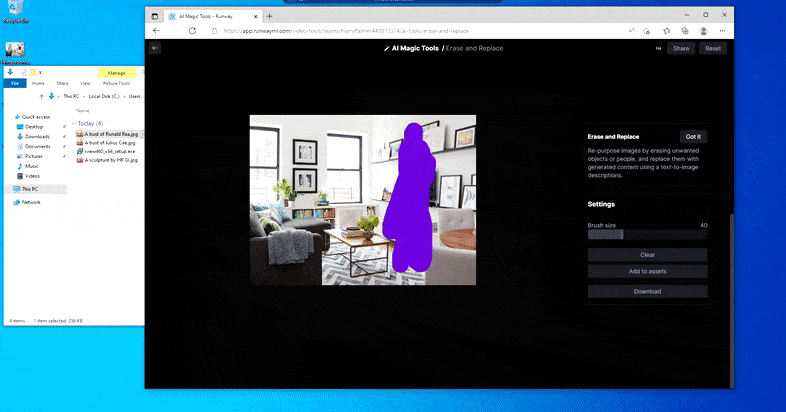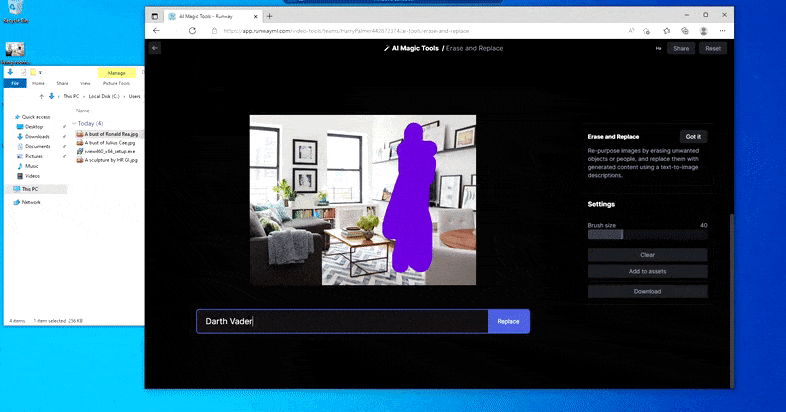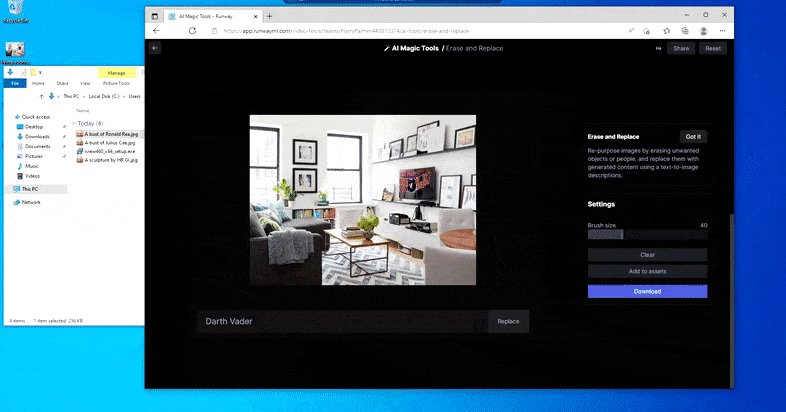
Som navnet antyder, kan du ikke injicere objekter i tomrum i Slet og Erstat. Her, et forsøg på at fremkalde den mest berømte af Sith-lordene resulterer i en underlig Vader-relateret mural på tv’et, omtrent hvor ‘erstat’-området var tegnet.
Det er svært at sige, om Slet og Erstat er undvigende i forhold til brugen af ophavsretsbegrænsede billeder (hvilket stadig er delvist blokeret, om end med varierende succes, i DALL-E 2), eller om modellen, der anvendes i backend-renderingen, blot ikke er optimeret til den slags.

Den lidt NSFW ‘Mural of Nicole Kidman’ antyder, at den (formodentlig) diffusionsbaserede model på hånden mangler DALL-E 2’s tidligere systematiske afvisning af at renderere realistiske ansigter eller risqué-indhold, mens resultaterne for forsøg på at fremkalde ophavsretsbegrænsede værker varierer fra det tvetydige (‘xenomorph’) til det absurde (‘the iron throne’). Indsat nederst til højre, kildebilledet.
Det ville være interessant at vide, hvilke metoder Slet og Erstat anvender til at isolere de objekter, det er i stand til at erstatte. Formodentlig køres billedet gennem en eller anden afledning af CLIP, med de diskrete elementer individueret af objektgenkendelse og efterfølgende semantisk segmentering. Ingen af disse operationer fungerer nær så godt i en almindelig installation af Stable Diffusion.
Men intet er perfekt – nogle gange synes systemet at slette og ikke erstatte, selv når (som vi har set i billedet ovenfor), den underliggende renderingsmekanisme bestemt ved, hvad en tekstprompt betyder. I dette tilfælde viser det sig umuligt at omdanne en kaffebord til en xenomorph – i stedet forsvinder blot bordet.
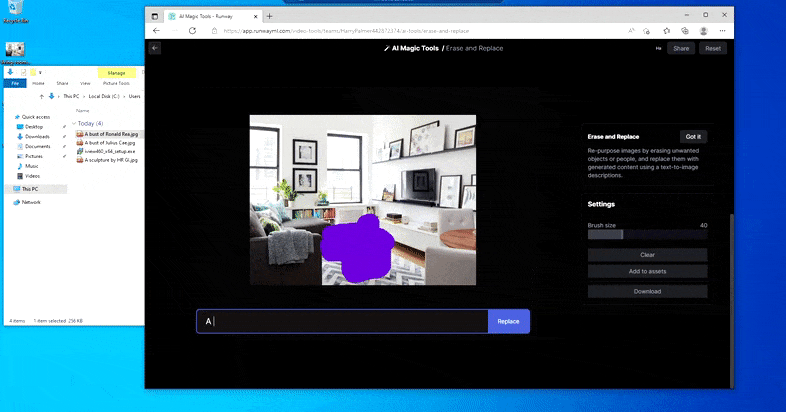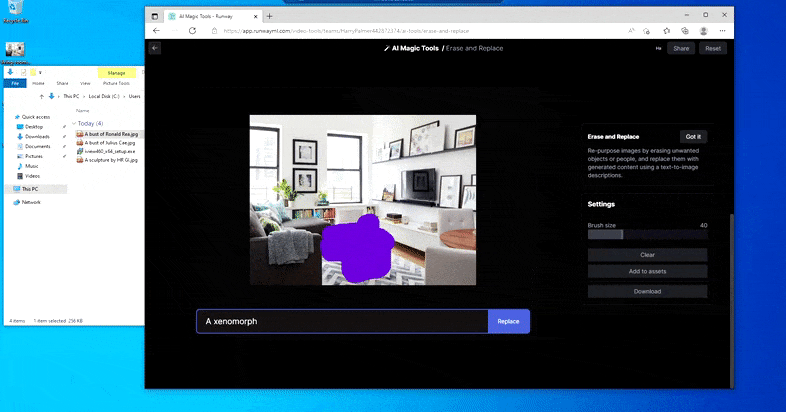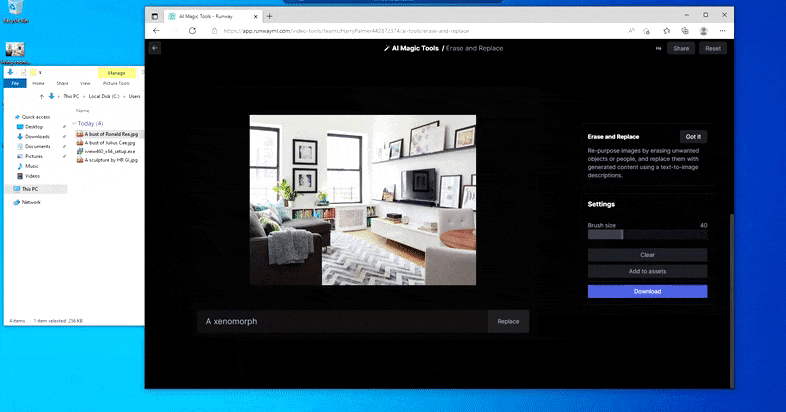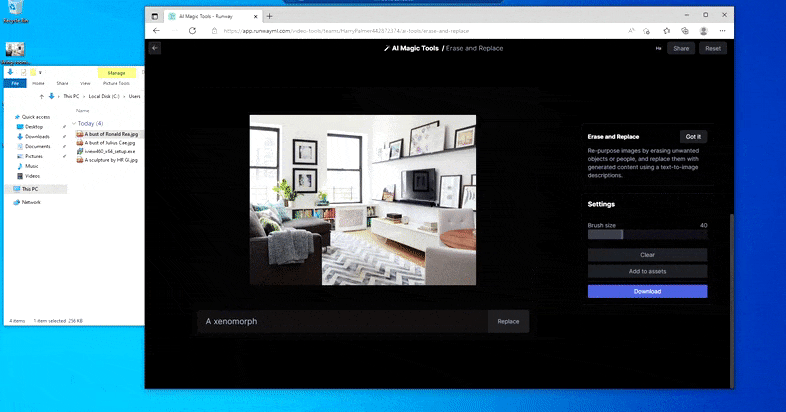
En mere skræmmende iteration af ‘Where’s Waldo’, da Slet og Erstat fejler i at producere en alien.
Slet og Erstat synes at være et effektivt objektersætningsystem med fremragende inpainting. Men det kan ikke redigere eksisterende opfattede objekter, kun erstatte dem. At redigere eksisterende billedindhold uden at kompromittere omgivende materiale er sandsynligvis en langt sværere opgave, forbundet med computer vision-forskningssektorens lange kamp mod disentanglement i de forskellige latente rum af de populære rammer.
Imagic
Det er en opgave, som Imagic løser. Den nye artikel tilbyder talrige eksempler på redigeringer, der med held ændrer enkeltfacetter af et billede, mens resten af billedet forbliver urørt.

I Imagic lider de ændrede billeder ikke under den karakteristiske strækning, forvrængning og ‘occlusion guessing’, der er karakteristisk for deepfake-puppetry, som anvender begrænsede priorer, der er afledt fra et enkelt billede.
Systemet anvender en tre-trinsproces – tekst-embedding-optimering; model-finjustering; og endelig generering af det ændrede billede.

Imagic kodificerer den målrettede tekstprompt for at hente den initielle tekst-embedding, og derefter optimerer resultatet for at få inputbilledet. Derefter finjusteres den generative model til kildebilledet, med tilføjelse af en række parametre, før den underkastes den anmodede interpolation.
Uventet er rammen baseret på Google’s Imagen-tekst-til-video-arkitektur, selvom forskerne påstår, at systemets principper er bredt anvendelige på latente diffusionsmodeller.
Imagen anvender en tre-lags-arkitektur, snarere end den syv-lags-array, der anvendes til firmaets mere nyere tekst-til-video-iteration af softwaren. De tre distinkte moduler består af en generativ diffusionsmodel, der opererer ved 64x64px opløsning; en super-resolution-model, der forøger denne output til 256x256px; og en yderligere super-resolution-model til at tage output helt op til 1024×1024 opløsning.
Imagic griber ind i den tidligste fase af denne proces, hvor den optimerer den anmodede tekst-embedding på 64px-stadiet på en Adam-optimizer med en statisk læringsrate på 0,0001.

En mesterklasse i disentanglement: de slutbrugere, der har forsøgt at ændre noget så simpelt som farven på et renderet objekt i en diffusions-, GAN- eller NeRF-model, ved, hvor betydningsfuldt det er, at Imagic kan udføre sådanne transformationer uden at ‘flå’ sammenhængen i resten af billedet fra hinanden.
Finjustering finder derefter sted på Imagens basis-model, i 1500 trin per inputbillede, betinget af den reviderede embedding. Samtidig optimeres den sekundære 64px>256px-lag parallelt på det betingede billede. Forskerne påpeger, at en lignende optimering for den endelige 256px>1024px-lag har ‘meget lidt eller ingen’ effekt på de endelige resultater, og har derfor ikke implementeret dette.
Artiklen påstår, at optimeringsprocessen tager cirka otte minutter per billede på dobbelt TPUV4-chips. Den endelige rendering finder sted i core Imagen under DDIM-sampleskemaet.
På samme måde som lignende finjusteringsprocesser for Google’s DreamBooth, kan de resulterende embeddings yderligere anvendes til at aktivere stilisering, samt fotorealistiske redigeringer, der indeholder informationer fra den underliggende database, der driver Imagen (da, som den første kolonne nedenfor viser, kildebillederne ikke har nogen af den nødvendige indhold til at effektuere disse transformationer).

Fleksible fotorealistiske bevægelser og redigeringer kan fremkaldes via Imagic, mens de afledte og disentanglede koder, der erhverves under processen, kan lige så let anvendes til stiliseret output.
Forskerne sammenlignede Imagic med tidligere værker SDEdit, en GAN-baseret tilgang fra 2021, et samarbejde mellem Stanford University og Carnegie Mellon University; og Text2Live, et samarbejde fra april 2022 mellem Weizmann Institute of Science og NVIDIA.

En visuel sammenligning mellem Imagic, SDEdit og Text2Live.
Det er klart, at de tidligere tilgange kæmper, men i den nederste række, der indebærer en massiv ændring af holdning, fejler de siddende fuldstændigt i at omforme kildematerialet, i modsætning til en bemærkelsesværdig succes fra Imagic.
Imagics ressourcekrav og træningstid per billede, mens kort i forhold til sådanne forfølgelse, gør det til en usandsynlig inklusion i en lokal billedredigeringsapplikation på personlige computere – og det er ikke klart, i hvilken udstrækning processen med finjustering kan reduceres til forbruger niveauer.
Som det står, er Imagic et imponerende tilbud, der er mere egnet til API’er – en miljø, Google Research, forsigtig i forhold til at facilitere deepfaking, måske i hvert fald er mest komfortabel med.
Først udgivet 18. oktober 2022.












