Kunstig intelligens
Adobe Research Udvider Disentangled GAN Ansigt Redigering

Det er ikke svært at forstå, hvorfor entanglement er et problem i billedsynthese, fordi det ofte er et problem i andre områder af livet; for eksempel er det meget sværere at fjerne kurkuma fra en curry end at smide pickle i en burger, og det er praktisk taget umuligt at desødne en kop kaffe. Nogle ting kommer bare i pakken.
Ligesom entanglement er et hindringsspørgsmål for billedsynthese-arkitekturer, der idealistisk set gerne vil adskille forskellige funktioner og begreber, når de bruger maskinel læring til at oprette eller redigere ansigter (eller hunde, både eller andre domæner).
Hvis du kunne adskille tråde som alder, køn, hårfarve, hudtone, følelse og så videre, ville du have begyndelsen på rigtig instrumentlighed og fleksibilitet i en ramme, der kunne oprette og redigere ansigtsbilleder på et virkelig detaljeret niveau, uden at trække uønskede “passagerer” med i disse konverteringer.

Ved maksimal entanglement (oven til venstre), kan du kun ændre billedet af et lært GAN-netværk til billedet af en anden person.
Dette er effektivt at bruge den seneste AI-computervisionsteknologi til at opnå noget, der blev løst ved andre midler for over 30 år siden.
Med en vis grad af adskillelse (‘Medium Separation’ i ovennævnt billede), er det muligt at udføre stilbaserede ændringer såsom hårfarve, udtryk, kosmetisk ansøgning og begrænset hovedrotation, blandt andre.

Kilde: FEAT: Face Editing with Attention, februar 2022, https://arxiv.org/pdf/2202.02713.pdf
Der har været en række forsøg i de sidste to år på at oprette interaktive ansigtsredigeringsmiljøer, der tillader en bruger at ændre ansigtskarakteristika med skydere og andre traditionelle brugergrænsefladeinteraktioner, mens de holder kernefunktionerne af målansigtet intakt, når der tilføjes eller ændres noget. Det har dog vist sig at være en udfordring på grund af den underliggende funktion/stil-entanglement i den latente rum af GAN.
For eksempel er briller-egenskaben ofte forbundet med aldrende-egenskaben, hvilket betyder, at tilføjelse af briller også kan “aldre” ansigtet, mens aldring af ansigtet kan tilføje briller, afhængigt af graden af anvendt adskillelse af højniveaufunktioner (se ‘Test’ nedenfor for eksempler).
Det er næsten umuligt at ændre hårfarve og andre hårfacetter uden at hårfiltrene og dispositionen bliver genberegnet, hvilket giver en ‘sizzlig’, overgangseffekt.

Kilde: InterFaceGAN Demo (CVPR 2020), https://www.youtube.com/watch?v=uoftpl3Bj6w
Latent-til-Latent GAN-Travers
En ny Adobe-ledet artikel indgivet til WACV 2022 tilbyder en ny tilgang til disse underliggende problemer i en artikel med titlen Latent til Latent: En Lært Mapper til Identitetsbevarende Redigering af Flere Ansigtsegenskaber i StyleGAN-genererede Billeder.

Supplementalmateriale fra artiklen Latent til Latent: En Lært Mapper til Identitetsbevarende Redigering af Flere Ansigtsegenskaber i StyleGAN-genererede Billeder. Her ser vi, at basis-karakteristika i det lært ansigt ikke trækkes ind i urelaterede ændringer. Se det fulde videoindhold ved slutningen af artiklen for bedre detaljer og opløsning. Kilde: https://www.youtube.com/watch?v=rf_61llRH0Q
Artiklen er ledet af Adobe Applied Scientist Siavash Khodadadeh, sammen med fire andre Adobe-forskere og en forsker fra Department of Computer Science ved University of Central Florida.
Artiklen er interessant dels, fordi Adobe har været aktiv i dette område i nogen tid, og det er fristende at forestille sig, at denne funktionalitet kommer ind i et Creative Suite-projekt i de næste få år; men hovedsagelig, fordi arkitekturen, der er oprettet til projektet, tager en anden tilgang til at opretholde visuel integritet i en GAN-ansigtsredaktør, mens ændringer anvendes.
Forfatterne erklærer:
‘[Vi] træner et neuralt netværk til at udføre en latent-til-latent-transformation, der finder den latente kodning, der svarer til billedet med den ændrede egenskab. Da teknikken er one-shot, afhænger den ikke af en lineær eller ikke-lineær trajektorie af den gradvise ændring af egenskaberne.’
‘Ved at træne netværket end-to-end over det fulde genereringsrør, kan systemet tilpasse sig til de latente rum af off-the-shelf generator-arkitekturer. Bevarelsesejenskaber, såsom at opretholde identiteten af personen, kan kodes i form af trænings-tab.
‘Når det latent-til-latent netværk var trænet, kan det genbruges til vilkårlige billeder uden gen-træning.’
Dette sidste punkt betyder, at den foreslåede arkitektur ankommer hos slutbrugeren i en færdig tilstand. Det skal stadig køre et neuralt netværk på lokale ressourcer, men nye billeder kan “droppes ind” og være klar til ændring næsten med det samme, da rammen er afkoblet nok til ikke at kræve yderligere billedspecifik træning.
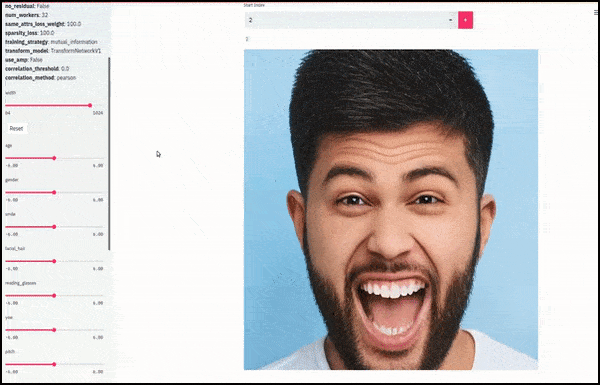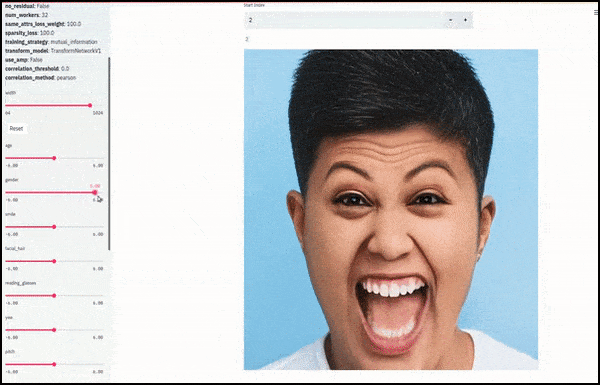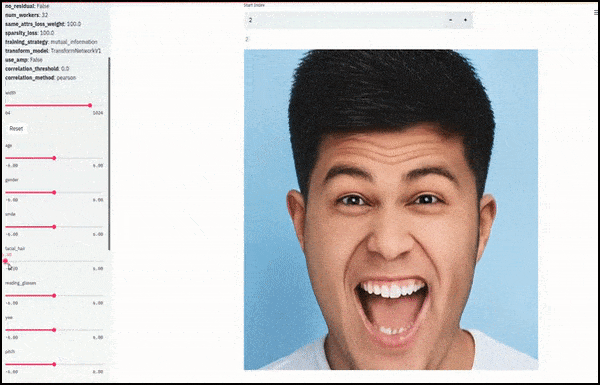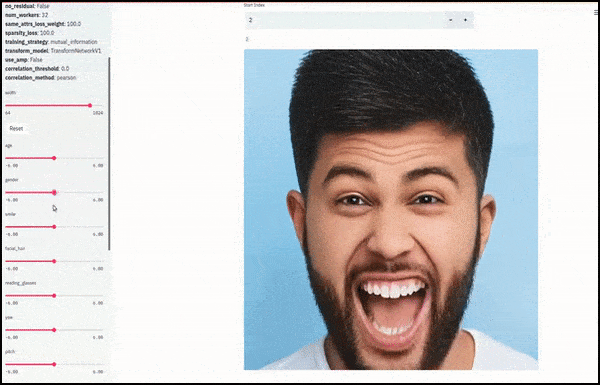
Køn og ansigtsbehåring ændret, mens skydere tegner tilfældige og vilkårlige stier gennem det latente rum, ikke kun ‘scubber’ mellem endepunkter’. Se videoen ved slutningen af artiklen for flere transformationer i bedre opløsning.
Blandt de vigtigste resultater i arbejdet er netværkets evne til at “fryse” identiteter i det latente rum ved at ændre kun egenskaben i en målvektor og give “korrektionsbetingelser”, der bevare identiteter, der transformeres.
Essentieligt er det foreslåede netværk indbygget i en bredere arkitektur, der orkestrerer alle de behandlede elementer, der passerer gennem forudtrænede komponenter med frosne vægte, der ikke producerer uønskede laterale effekter på transformationer.
Da træningsprocessen afhænger af tripletter, der kan genereres enten af et seed-billede (under GAN-inversion) eller en eksisterende initial latent kodning, er hele træningsprocessen unsupervised, med de typiske handlinger af den sædvanlige række af mærknings- og kurations-systemer i sådanne systemer effektivt bagt ind i arkitekturen. Faktisk bruger det nye system off-the-shelf attribut-regressorer:
‘[Antallet af] egenskaber, som vores netværk kan uafhængigt kontrollere, er kun begrænset af erkendelses-evnernes (recognizer(s)) – hvis man har en erkendelse for en egenskab, kan vi tilføje det til vilkårlige ansigter. I vores eksperimenter trænede vi det latent-til-latent netværk til at tillade justering af 35 forskellige ansigtsegenskaber, mere end nogen tidligere tilgang.’
Systemet inkorporerer en yderligere sikkerhedsforanstaltning mod uønskede “side-effekt”-transformationer: i mangelen på en anmodning om en egenskabsændring, vil det latent-til-latent netværk kortlægge en latent vektor til sig selv, hvilket yderligere øger stabil persistens af målidentiteten.
Ansigtsgenkendelse
Et tilbagevendende problem med GAN og encoder/decoder-baserede ansigtsredigeringer i de seneste år har været, at anvendte transformationer tenderer til at nedbryde lighed. For at bekæmpe dette bruger Adobe-projektet en indbygget ansigtsgenkendelsesnetværk kaldet FaceNet som en diskriminator.

Projektarkitektur, se lav midt-venstre for inklusion af FaceNet. Kilde: Latent til Latent: En Lært Mapper til Identitetsbevarende Redigering af Flere Ansigtsegenskaber i StyleGAN-genererede Billeder, OpenAccess.
(På en personlig note synes det her at være et opmuntrende skridt mod integration af standard ansigtsgenkendelse og selv udtryksgenkendelse i generative netværk, sandsynligvis den bedste vej frem for at overvinde den blinde pixel>pixel-mapping, der dominerer nuværende deepfake-arkitekturer på bekostning af udtryksfidelitet og andre vigtige domæner i ansigtsgenereringssektoren.)
Adgang til alle områder i det latente rum
En anden imponerende funktion i rammen er dens evne til at rejse vilkårligt mellem potentielle transformationer i det latente rum, efter brugerens ønske. Flere tidligere systemer, der tilbød eksplorerende grænseflader, efterlod ofte brugeren med at “scubbe” mellem faste funktionstransformationstidslinjer – imponerende, men ofte ret lineære eller proskriptive oplevelser.

Fra Forbedring af GAN-ligevægt ved at øge rumlig bevidsthed: her scubber brugeren gennem en række af potentielle overgangspunkter mellem to latente rum-lokationer, men inden for rammerne af forudtrænede lokationer i det latente rum. For at anvende andre typer af transformationer baseret på samme materiale er omkonfiguration og/eller gen-træning nødvendig. Kilde: https://genforce.github.io/eqgan/
Ud over at være modtagelig for helt nye bruger-billeder kan brugeren også manuelt “fryse” elementer, som de ønsker at bevare under transformationsprocessen. På denne måde kan brugeren sikre, at (for eksempel) baggrunde ikke skifter, eller at øjne holdes åbne eller lukkede.
Data
Attribut-regressionsnetværket blev trænet på tre netværk: FFHQ, CelebAMask-HQ og et lokalt, GAN-genereret netværk opnået ved at sampile 400.000 vektorer fra Z-rummet af StyleGAN-V2.
Udenfor-distribution (OOD) billeder blev filtreret væk, og attributterne blev trukket ud ved hjælp af Microsofts Face API, med det resulterende billedsæt delt 90/10, hvilket efterlod 721.218 træningsbilleder og 72.172 testbilleder til sammenligning.
Test
Selvom det eksperimentelle netværk initialt var konfigureret til at kunne håndtere 35 potentielle transformationer, blev disse reduceret til otte for at kunne gennemføre analoge tests mod de sammenlignelige rammer InterFaceGAN, GANSpace og StyleFlow.
De otte valgte attributter var Alder, Skaldethed, Skæg, Udtryk, Køn, Briller, Pitch og Yaw. Det var nødvendigt at omkonfigurere de konkurrerende rammer for visse af de otte attributter, der ikke var provisioneret i den oprindelige distribution, såsom tilføjelse af skaldethed og skæg til InterFaceGAN.
Som forventet skete en større grad af entanglement i de rivaliserende arkitekturer. For eksempel ændrede InterFaceGAN og StyleFlow begge kønnet på subjektet, når de blev bedt om at anvende alder:

To af de konkurrerende rammer rullede en kønsændring ind i ‘alder’-transformationen, og ændrede også hårfarve uden direkte bud fra brugeren.
Derudover fandt to af rivalerne, at briller og alder er uskillelige aspekter:

Briller og hårfarve ændret som en ekstra service!
Det er ikke en ensartet sejr for forskningen: som kan ses i den tilhørende video indlejret ved slutningen af artiklen, er rammen mindst effektiv, når det kommer til at ekstrapolere diverse vinkler (yaw), mens GANSpace har en bedre generel result for alder og påføring af briller. Det latent-til-latent ramme er lig med GANSpace og StyleFlow med hensyn til tilføjelse af pitch (hovedvinkel).

Resultater beregnet på basis af en kalibrering af MTCNN ansigtsgenkendelses-system. Lavere resultater er bedre.
For yderligere detaljer og bedre opløsning af eksempler, se artiklens tilhørende video nedenfor.
Først udgivet 16. februar 2022.












