
Umělá inteligence
Jsou nedostatečně upravené datové sady hyperškálové umělé inteligence horší než samotný internet?

Výzkumníci z Irska, Spojeného království a USA varovali, že růst hyperškálových tréninkových datových souborů AI ohrožuje šíření nejhorších aspektů jejich internetových zdrojů, a tvrdí, že nedávno vydaná akademická datová sada obsahuje „obtížné a explicitní obrázky a textové dvojice znásilnění, pornografie, zhoubných stereotypů, rasistických a etnických nadávek a dalšího extrémně problematického obsahu“.
Výzkumníci se domnívají, že nová vlna masivních nedostatečně upravených nebo nesprávně filtrovaných multimodálních datových souborů (například obrázků a obrázků) je pravděpodobně škodlivější ve své schopnosti posílit účinky takového negativního obsahu, protože datové soubory uchovávají snímky a další obsah. které mohly být od té doby odstraněny z online platforem prostřednictvím stížností uživatelů, místního moderování nebo algoritmů.
Dále poznamenávají, že může trvat roky – v případě mocné datové sady ImageNet i celé desetiletí – než budou vyřešeny dlouhodobé stížnosti na obsah datové sady, a že tyto pozdější revize se ne vždy projeví ani v nových datových sadách z nich odvozených. .
Projekt papírS názvem Multimodální datové soubory: misogynie, pornografie a maligní stereotypy, pochází od výzkumníků z University College Dublin & Lero, University of Edinburgh a hlavního vědeckého pracovníka autentizační platformy UnifyID.
Přestože se práce zaměřuje na nedávné vydání CLIP-filtrovaný Datová sada LAION-400M, autoři argumentují proti obecnému trendu vrhat stále větší množství dat do rámců strojového učení, jako je model neuronového jazyka GPT-3, a tvrdí, že zaměřené na výsledky směřují k lepšímu vyvozování (a dokonce k umělé obecné inteligenci [AGI]). ), má za následek ad hoc použití škodlivých zdrojů dat s nedbalým dohledem nad autorským právem; potenciál způsobovat a podporovat škodu; a schopnost nejen udržovat nelegální data, která by jinak mohla zmizet z veřejné sféry, ale skutečně začlenit morální modely takových dat do následných implementací AI.
LAION-400M
Minulý měsíc byla vydána datová sada LAION-400M, která přidala k rostoucímu počtu multimodálních, lingvistických datových sad, které se spoléhají na Společné procházení úložiště, které bez rozdílu šrotuje internet a předává odpovědnost za filtrování a správu projektům, které jej využívají. Odvozená datová sada obsahuje 400 milionů párů text/obrázek.
LAION-400M je open source varianta uzavřeného WIT (WebImageText) Google AI dataset vydané v březnu 2021 a obsahuje páry text-obrázek, kde byl obrázek v databázi spojen s doprovodným explicitním textem nebo textem metadat (například alternativní text obrázku ve webové galerii). To umožňuje uživatelům provádět načítání obrázků na základě textu a odhalovat asociace, které si základní AI vytvořila s těmito doménami (tj. 'zvíře', 'kolo', 'osoba', 'muž', 'žena').
Tento vztah mezi obrázkem a textem a kosinusová podobnost, která může začlenit zkreslení do výsledků dotazů, jsou jádrem volání po vylepšených metodologiích, protože velmi jednoduché dotazy do databáze LAION-400M mohou odhalit zkreslení.
Například snímek průkopnické astronautky Eileen Collins v knihovně obrázků scitkit získává dva související titulky v LAION-400M: „Toto je portrét astronauta s americkou vlajkou“ a "Toto je fotografie usmívající se ženy v domácnosti v oranžové kombinéze s americkou vlajkou".

Americká astronautka Eileen Collinsová získává dva velmi odlišné pohledy na své úspěchy jako první žena ve vesmíru pod LAION-400M. Zdroj: https://arxiv.org/pdf/2110.01963.pdf
Hlášené kosinusové podobnosti, díky nimž je pravděpodobné, že bude použitelný kterýkoli z titulků, jsou si velmi blízké a autoři tvrdí, že taková blízkost by způsobila, že systémy AI, které používají LAION-400M, budou relativně pravděpodobně prezentovat jeden z nich jako vhodný titulek.
Pornografie opět stoupá na vrchol
LAION-400M vytvořil prohledávatelné rozhraní dostupný, kde zrušení zaškrtnutí tlačítka „bezpečné vyhledávání“ odhalí, do jaké míry pornografické snímky a textové asociace dominují štítkům a třídám. Například, hledám 'jeptiška' (NSFW, pokud následně deaktivujete bezpečný režim) v databázi vrátí výsledky většinou související s hororem, cosplayem a kostýmy, přičemž je k dispozici jen velmi málo skutečných jeptišek.
Vypnutí nouzového režimu při stejném vyhledávání odhalí spoustu pornografických obrázků souvisejících s tímto výrazem, které posouvají jakékoli nepornografické obrázky dolů na stránku s výsledky vyhledávání, což odhaluje, do jaké míry LAION-400M přiřadil větší váhu pornografickým obrázkům, protože oni jsou převládající pro termín ' jeptiška ' v online zdrojích.
Výchozí aktivace nouzového režimu je v rozhraní online vyhledávání klamná, protože představuje zvláštnost uživatelského rozhraní, filtr, který nejenže nemusí být nutně aktivován v odvozených systémech umělé inteligence, ale který byl svým způsobem zobecněn do domény „jeptiška“. které nelze tak snadno filtrovat nebo odlišit od (relativně) výsledků SFW z hlediska použití algoritmů.
Práce obsahuje rozmazané příklady různých hledaných výrazů v doplňkových materiálech na konci. Nemohou zde být uvedeny kvůli jazyku v textu, který doprovází rozmazané fotografie, ale vědci berou na vědomí daň, kterou si na nich vyžádalo zkoumání a rozmazávání snímků, a uznávají, že je obtížné připravit takový materiál pro lidský dohled nad velkými -škálové databáze:
"My (stejně jako naši kolegové, kteří nám pomáhali) zažili různé úrovně nepohodlí, nevolnosti a bolesti hlavy během procesu zkoumání souboru dat. Navíc tento druh práce neúměrně naráží na významnou negativní kritiku v akademické sféře umělé inteligence hned po vydání, což nejen přidává další emocionální daň k již tak těžkému úkolu studovat a analyzovat takové soubory dat, ale také odrazuje od podobné budoucí práce, což je na škodu. pole AI a společnost obecně.“
Výzkumníci tvrdí, že zatímco kurátorství „člověk ve smyčce“ je drahé a je s ním spojeno osobní náklady, automatické filtrační systémy navržené k odstranění nebo jinému řešení takového materiálu zjevně nejsou adekvátní pro daný úkol, protože systémy NLP mají potíže s izolací nebo zlevněním útoků. materiál, který může dominovat seškrabovanému souboru dat a následně být vnímán jako významný kvůli samotnému objemu.
Zakotvení zakázaného obsahu a odstranění ochrany autorských práv
Dokument tvrdí, že nedostatečně upravené datové soubory této povahy „velmi pravděpodobně“ udrží vykořisťování menšinových jednotlivců a řeší, zda podobné open source datové projekty mají právo, právně nebo morálně, přenést odpovědnost za materiál na koncový uživatel:
„Jednotlivci mohou smazat svá data z webové stránky a domnívat se, že jsou nenávratně pryč, zatímco mohou stále existovat na serverech několika výzkumných pracovníků a organizací. Existuje otázka, kdo je zodpovědný za odstranění těchto dat z použití v datové sadě? U LAION-400M tvůrci delegovali tento úkol na uživatele datové sady. Vzhledem k tomu, že takové procesy jsou záměrně složité a že průměrný uživatel postrádá technické znalosti k odstranění svých dat, je to rozumný přístup?
Dále tvrdí, že LAION-400M nemusí být vhodný pro vydání v rámci přijatého licenčního modelu Creative Common CC-BY 4.0, a to navzdory potenciálním výhodám pro demokratizaci rozsáhlých datových sad, které byly dříve výhradní doménou dobře financovaných společností, jako je Google a OpenAI.
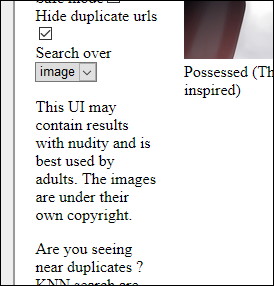
Doména LAION-400M tvrdí, že obrázky datových sad „jsou pod jejich vlastními autorskými právy“ – mechanismus „průchodu“ z velké části umožněný soudními rozhodnutími a vládními směrnicemi z posledních let, které široce schvalují web-scraping pro výzkumné účely. Zdroj: https://rom1504.github.io/clip-retrieval/
Autoři naznačují, že místní (tj. davově získaní dobrovolníci) by mohli řešit některé problémy s datovými soubory a že výzkumníci by mohli vyvinout vylepšené techniky filtrování.
„Práva subjektu údajů zde nicméně zůstávají nedořešena. Je bezohledné a nebezpečné podceňovat škody spojené s tak rozsáhlými datovými soubory a podporovat jejich používání v průmyslovém a komerčním prostředí. Odpovědnost za licenční schéma, podle kterého je datová sada poskytována, spadá výhradně na tvůrce datové sady“.
Problémy demokratizace hyperškálových dat
Dokument tvrdí, že visio-lingvistické datové sady tak velké jako LAION-400M byly dříve nedostupné mimo velké technologické společnosti a omezený počet výzkumných institucí, které disponují prostředky k jejich shromažďování, správě a zpracování. Dále vzdávají hold duchu nového vydání a zároveň kritizují jeho provedení.
Autoři tvrdí, že přijatá definice „demokratizace“, jak se vztahuje na open source hyperškálové datové sady, je příliš omezená a „nepřihlíží k právům, blahobytu a zájmům zranitelných jednotlivců a komunit, z nichž mnozí pravděpodobně nejhůře utrpí následnými dopady tohoto souboru dat a modelů, které se na něm vycvičily“.
Vzhledem k tomu, že vývoj modelů s otevřeným zdrojovým kódem v měřítku GPT-3 je v konečném důsledku navržen tak, aby byly distribuovány milionům (a prostřednictvím proxy, možná miliardám) uživatelů po celém světě, a protože výzkumné projekty mohou přijmout datové sady předtím, než budou následně upraveny nebo dokonce odstraněny, čímž se udrží cokoliv Problémy byly navrženy tak, aby je řešily úpravy, autoři tvrdí, že nedbalé vydávání nedostatečně upravených datových sad by se nemělo stát obvyklým prvkem strojového učení s otevřeným zdrojovým kódem.
Vložení džina zpět do láhve
Některé datové sady, které byly potlačeny dlouho poté, co jejich obsah prošel, možná neoddělitelně, do dlouhodobých projektů umělé inteligence, zahrnuty datový soubor Duke MTMC (Multi-Target, Multi-Camera), který byl nakonec stažen z důvodu opakované obavy od organizací pro lidská práva kolem jeho používání represivními orgány v Číně; Microsoft Celeb (MS-Celeb-1M), datová sada 10 milionů snímků obličejů „celebrit“, které proběhlo zahrnout novináře, aktivisty, tvůrce politik a spisovatele, jejichž zveřejnění biometrických údajů bylo silně kritizováno; a datový soubor Tiny Images, stažena v roce 2020 za sebepřiznané „předpojatosti, urážlivé a škodlivé obrázky a hanlivou terminologii“.
Pokud jde o datové soubory, které byly po kritice spíše pozměněny než staženy, příklady zahrnují velmi populární datový soubor ImageNet, který, jak vědci poznamenávají, trvalo deset let (2009-2019) jednat na základě opakované kritiky týkající se soukromí a tříd, které si nelze představit.
Dokument poznamenává, že LAION-400M účinně brzdí i tato odkladná vylepšení tím, že „z velké části ignoruje“ výše uvedené revize v reprezentaci ImageNet v nové verzi, a sleduje širší trend v tomto ohledu*:
„To je zvýrazněno vznikem větších souborů dat, jako je např Datový soubor Tencent ML-images (v únoru 2020), která zahrnuje většinu z nich nezobrazitelné třídy, pokračující dostupnost modelů trénovaných na úplném souboru dat ImageNet-21k v úložištích jako je TF-hub, pokračující používání nefiltrovaného-ImageNet-21k v nejnovějších modelech SotA (jako je nejnovější EfficientNetV2 od společnosti Google a modely CoAtNet) a výslovná oznámení povolující použití nefiltrovaného předběžného školení-ImageNet-21k v renomovaných soutěžích jako je výzva LVIS 2021.
„Zdůrazňujeme toto zásadní pozorování: Tým velikosti ImageNet, který spravuje méně než 15 milionů snímků, se v těchto pokusech o detoxikaci dosud potýkal a selhal.
"Rozsah pečlivého úsilí potřebného k důkladné detoxikaci tohoto masivního multimodálního souboru dat a následných modelů trénovaných na tomto souboru dat zahrnujících potenciálně miliardy párů obrázků a titulků bude nepopiratelně astronomický."
* Můj převod vložených citací autora na hypertextové odkazy.















