
Prompt Engineering
ChatGPT & Advanced Prompt Engineering: Řízení vývoje AI

OpenAI se podílela na vývoji revolučních nástrojů, jako je OpenAI Gym, navržený pro trénink posilovacích algoritmů a modely GPT-n. V centru pozornosti je také DALL-E, model umělé inteligence, který vytváří obrázky z textových vstupů. Jedním z takových modelů, který si získal značnou pozornost, je OpenAI ChatGPT, zářný příklad v oblasti velkých jazykových modelů.
GPT-4: Rychlé inženýrství
ChatGPT transformoval prostředí chatbotů, nabízí lidské reakce na uživatelské vstupy a rozšiřuje své aplikace napříč doménami – od vývoje softwaru a testování po obchodní komunikaci a dokonce i tvorbu poezie.
V rukou podniků a jednotlivců by například GPT-4 mohl sloužit jako nevyčerpatelný rezervoár znalostí, zběhlý v předmětech od matematiky a biologie po právní studia. Tyto sofistikované a dostupné modely umělé inteligence jsou připraveny předefinovat budoucnost práce, učení a kreativity.

Generativní modely jako GPT-4 mohou vytvářet nová data na základě stávajících vstupů. Tento charakteristický atribut jim umožňuje provádět různé úkoly, včetně generování textu, obrázků, hudby a videa.
V kontextu modelů ChatGPT a OpenAI je výzva vstupem, který uživatelé poskytují modelům, obvykle ve formě textu. Výzvy slouží jako primární prostředek kontroly výstupu generovaného těmito modely, díky čemuž jsou klíčové pro úspěšné a relevantní konverzace.
Dopad rychlé kvality
Použití dobře definovaných výzev je klíčem k zapojení do užitečných a smysluplných konverzací se systémy AI. Špatně definované výzvy mohou mít za následek výstup, který není pro uživatele užitečný a může dokonce vést k zavádějícímu obsahu.
Abychom demonstrovali dopad kvality výzev, porovnejme dvě různé výzvy dané ChatGPT. První výzva, špatně definovaná a předpokládá předchozí znalosti, generuje pro uživatele potenciálně neužitečnou odpověď. Na druhou stranu druhá výzva poskytuje více kontextu a příkladů, což zajišťuje relevantnější a srozumitelnější odpověď.
Výzva 1: "Povězte mi o konvolučních neuronových sítích."
Reakce 1: „Konvoluční neuronové sítě (CNN) jsou vícevrstvé perceptronové sítě, které se skládají z plně propojených vrstev a sdružovacích vrstev. Běžně se používají v úlohách rozpoznávání obrázků. Tento proces zahrnuje použití filtrů na vstupní obrázky a jejich zmenšení pomocí sdružovacích vrstev.“
Výzva 2: „Chci se dozvědět o konvolučních neuronových sítích, ale nemám žádné předchozí znalosti o umělých neuronových sítích. Můžete prosím poskytnout vysvětlení vhodné pro začátečníky a příklad toho, jak se CNN používají při rozpoznávání obrazu?
Reakce 2: „Konvoluční neuronové sítě (CNN) jsou typem neuronové sítě primárně používané pro úlohy rozpoznávání obrazu. Na rozdíl od jiných neuronových sítí využívají ke zpracování obrázků konvoluční vrstvy a sdružovací vrstvy. Představte si, že máte obrázek kočky. CNN mohou identifikovat různé prvky v obraze, jako jsou vousy, uši a ocas, použitím filtrů a převzorkováním obrazu pomocí sdružování vrstev. Díky tomuto procesu jsou CNN vysoce efektivní pro rozpoznávání objektů na obrázcích.
Porovnáním obou odpovědí je zřejmé, že dobře definovaná výzva vede k relevantnější a uživatelsky přívětivější odpovědi. Rychlý design a inženýrství jsou rostoucí disciplíny, jejichž cílem je optimalizovat výstupní kvalitu modelů umělé inteligence, jako je ChatGPT.
V následujících částech tohoto článku se ponoříme do oblasti pokročilých metodologií zaměřených na zdokonalování velkých jazykových modelů (LLM), jako jsou techniky rychlého inženýrství a taktiky. Patří mezi ně několik výstřelů, ReAct, řetězení myšlenek, RAG a další.
Pokročilé inženýrské techniky
Než budeme pokračovat, je důležité pochopit klíčový problém s LLM, označovaný jako „halucinace“. V kontextu LLM znamená „halucinace“ tendenci těchto modelů generovat výstupy, které se mohou zdát rozumné, ale nemají kořeny ve faktické realitě nebo daném vstupním kontextu.
Tento problém byl ostře zdůrazněn v nedávném soudním případu, kdy jej obhájce použil ChatGPT pro právní výzkum. Nástroj AI, pokulhávající kvůli problému s halucinacemi, citoval neexistující právní případy. Tento chybný krok měl závažné důsledky, způsobil zmatek a podkopal důvěryhodnost v průběhu řízení. Tento incident slouží jako ostrá připomínka naléhavé potřeby řešit problém „halucinací“ v systémech umělé inteligence.
Náš průzkum technik rychlého inženýrství má za cíl zlepšit tyto aspekty LLM. Zvyšováním jejich účinnosti a bezpečnosti připravujeme cestu pro inovativní aplikace, jako je extrakce informací. Navíc otevírá dveře k bezproblémové integraci LLM s externími nástroji a datovými zdroji, čímž se rozšiřuje rozsah jejich potenciálního využití.
Učení s nulovým a několika výstřely: Optimalizace pomocí příkladů
Generativní předtrénované transformátory (GPT-3) znamenaly důležitý obrat ve vývoji generativních modelů umělé inteligence, protože zavedly koncept 'učení několika ranami.' Tato metoda změnila hru díky své schopnosti efektivně fungovat bez nutnosti komplexního dolaďování. V dokumentu je diskutován rámec GPT-3, “Jazykové modely se učí málokdo“, kde autoři demonstrují, jak model vyniká v různých případech použití, aniž by vyžadoval vlastní datové sady nebo kód.
Na rozdíl od jemného ladění, které vyžaduje neustálé úsilí při řešení různých případů použití, modely s několika snímky prokazují snadnější adaptabilitu na širší škálu aplikací. I když jemné ladění může v některých případech poskytnout robustní řešení, může být nákladné v měřítku, takže použití několikanásobných modelů je praktičtější přístup, zejména pokud jsou integrovány s rychlým inženýrstvím.
Představte si, že se pokoušíte přeložit angličtinu do francouzštiny. V několikanásobném učení byste GPT-3 poskytli několik příkladů překladu jako „mořská vydra -> loutre de mer“. GPT-3, protože jde o pokročilý model, je pak schopen nadále poskytovat přesné překlady. Ve výuce s nulovým výstřelem byste neposkytli žádné příklady a GPT-3 by stále dokázal efektivně překládat angličtinu do francouzštiny.
Pojem „několik výstřelů“ pochází z myšlenky, že modelu je poskytnut omezený počet příkladů, ze kterých se lze „učit“. Je důležité poznamenat, že „učit se“ v tomto kontextu nezahrnuje aktualizaci parametrů nebo vah modelu, ale ovlivňuje výkon modelu.

Několik výstřelů učení, jak je ukázáno v GPT-3 Paper
Zero-shot learning posouvá tento koncept o krok dále. Při učení typu zero-shot nejsou v modelu uvedeny žádné příklady dokončení úkolu. Očekává se, že model bude fungovat dobře na základě jeho počátečního školení, takže tato metodika je ideální pro scénáře odpovědí na otázky v otevřené doméně, jako je ChatGPT.
V mnoha případech může model zběhlý v nulovém výuce fungovat dobře, když má k dispozici několik nebo dokonce jednorázové příklady. Tato schopnost přepínat mezi nulovým, jednoduchým a několikanásobným výukovým scénářem podtrhuje adaptabilitu velkých modelů a zlepšuje jejich potenciální aplikace v různých doménách.
Metody učení s nulovým výstřelem jsou stále více rozšířené. Tyto metody se vyznačují schopností rozpoznávat předměty neviditelné během tréninku. Zde je praktický příklad výzvy k několika výstřelům:
"Translate the following English phrases to French:
'sea otter' translates to 'loutre de mer'
'sky' translates to 'ciel'
'What does 'cloud' translate to in French?'"
Tím, že modelu poskytneme několik příkladů a poté položíme otázku, můžeme efektivně vést model k vytvoření požadovaného výstupu. V tomto případě by GPT-3 pravděpodobně správně přeložilo „cloud“ na „nuage“ ve francouzštině.
Ponoříme se hlouběji do různých nuancí rychlého inženýrství a jeho zásadní role při optimalizaci výkonu modelu během inference. Podíváme se také na to, jak jej lze efektivně využít k vytvoření nákladově efektivních a škálovatelných řešení pro širokou škálu případů použití.
Při dalším zkoumání složitosti technik rychlého inženýrství v modelech GPT je důležité zdůraznit náš poslední příspěvek „Základní průvodce rychlým inženýrstvím v ChatGPT'. Tato příručka poskytuje informace o strategiích pro efektivní výuku modelů AI v mnoha případech použití.
V našich předchozích diskusích jsme se ponořili do základních promptních metod pro velké jazykové modely (LLM), jako je nulové a několikanásobné učení, stejně jako instrukční nabádání. Zvládnutí těchto technik je zásadní pro zvládnutí složitějších výzev rychlého inženýrství, které zde prozkoumáme.
Učení několika výstřelů může být omezeno kvůli omezenému kontextovému oknu většiny LLM. Kromě toho, bez příslušných záruk mohou být LLM svedeni k poskytování potenciálně škodlivého výstupu. Navíc se mnoho modelů potýká s úlohami uvažování nebo dodržováním vícekrokových pokynů.
Vzhledem k těmto omezením spočívá výzva ve využití LLM k řešení složitých úkolů. Zřejmým řešením může být vývoj pokročilejších LLM nebo zdokonalení stávajících, ale to může vyžadovat značné úsilí. Nabízí se tedy otázka: jak můžeme optimalizovat současné modely pro lepší řešení problémů?
Stejně fascinující je zkoumání toho, jak se tato technika propojuje s kreativními aplikacemi v Unite AI'Mastering AI Art: Stručný průvodce střední cestou a rychlým inženýrstvím“, která popisuje, jak může spojení umění a umělé inteligence vyústit v umění vzbuzující úctu.
Vybízení k řetězci myšlenek
Řetězec myšlenek využívá inherentní auto-regresivní vlastnosti velkých jazykových modelů (LLM), které vynikají v predikci dalšího slova v dané sekvenci. Tím, že model podněcuje k objasnění jeho myšlenkového procesu, navozuje důkladnější, metodičtější generování nápadů, které mají tendenci úzce se sladit s přesnými informacemi. Toto zarovnání pramení ze sklonu modelu zpracovávat a dodávat informace promyšleným a uspořádaným způsobem, podobně jako lidský expert prochází posluchače komplexním konceptem. Jednoduché prohlášení jako „proveďte mě krok za krokem, jak…“ často stačí ke spuštění tohoto podrobnějšího a podrobnějšího výstupu.
Zero-shot Chain-of-Thought Prompting
Zatímco konvenční nabádání CoT vyžaduje předškolení s ukázkami, nově se objevující oblastí jsou výzvy CoT s nulovým záběrem. Tento přístup, který zavedli Kojima et al. (2022), inovativně přidává do původní výzvy frázi „Přemýšlejme krok za krokem“.
Vytvořme pokročilou výzvu, kde má ChatGPT za úkol shrnout klíčové poznatky z výzkumných prací AI a NLP.
V této ukázce využijeme schopnosti modelu porozumět a shrnout komplexní informace z odborných textů. Pomocí metody učení několika výstřelů naučme ChatGPT shrnout klíčová zjištění z výzkumných prací o AI a NLP:
1. Paper Title: "Attention Is All You Need"
Key Takeaway: Introduced the transformer model, emphasizing the importance of attention mechanisms over recurrent layers for sequence transduction tasks.
2. Paper Title: "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
Key Takeaway: Introduced BERT, showcasing the efficacy of pre-training deep bidirectional models, thereby achieving state-of-the-art results on various NLP tasks.
Now, with the context of these examples, summarize the key findings from the following paper:
Paper Title: "Prompt Engineering in Large Language Models: An Examination"
Tato výzva nejen zachovává jasný myšlenkový řetězec, ale také využívá k vedení modelu několikanásobný učební přístup. Souvisí s našimi klíčovými slovy tím, že se zaměřuje na domény AI a NLP, konkrétně zadává ChatGPT, aby provedl komplexní operaci, která souvisí s rychlým inženýrstvím: shrnutí výzkumných prací.
Výzva k reakci
React, neboli „Reason and Act“, představil Google v dokumentu „ReAct: Synergizace uvažování a jednání v jazykových modelech“, a způsobila revoluci ve způsobu interakce jazykových modelů s úkolem, což přimělo model dynamicky generovat jak verbální uvažování, tak akce specifické pro daný úkol.
Představte si lidského kuchaře v kuchyni: nejenže provádějí řadu činností (krájí zeleninu, vaří vodu, míchají přísady), ale také se zabývají verbálním uvažováním nebo vnitřní řečí („teď, když je zelenina nakrájená, měl bych položit hrnec vařič"). Tento pokračující mentální dialog pomáhá při strategickém plánování procesu, přizpůsobení se náhlým změnám („Došel mi olivový olej, použiji místo něj máslo“) a zapamatování si pořadí úkolů. React napodobuje tuto lidskou schopnost a umožňuje modelu rychle se učit novým úkolům a činit robustní rozhodnutí, stejně jako by to dělal člověk za nových nebo nejistých okolností.
React dokáže vypořádat se s halucinacemi, běžným problémem u systémů Chain-of-Thought (CoT). CoT, ačkoli je to účinná technika, postrádá schopnost interakce s vnějším světem, což by mohlo potenciálně vést k halucinacím a šíření chyb. React to však kompenzuje propojením s externími zdroji informací. Tato interakce umožňuje systému nejen ověřovat své úvahy, ale také aktualizovat své znalosti na základě nejnovějších informací z vnějšího světa.
Základní fungování Reactu lze vysvětlit pomocí instance z HotpotQA, což je úkol vyžadující uvažování vysokého řádu. Po obdržení otázky model React rozdělí otázku na zvládnutelné části a vytvoří akční plán. Model generuje stopu uvažování (myšlenku) a identifikuje relevantní akci. Může se rozhodnout vyhledat informace o Apple Remote na externím zdroji, jako je Wikipedia (akce), a na základě získaných informací (pozorování) své porozumění aktualizovat. Prostřednictvím několika kroků myšlenek-akcí-pozorování může ReAct získat informace, které podpoří své uvažování, a zároveň upřesnit, co potřebuje získat jako další.
Poznámka:
HotpotQA je datová sada, odvozená z Wikipedie, složená ze 113 XNUMX párů otázka-odpověď navržená k trénování systémů umělé inteligence v komplexním uvažování, protože otázky vyžadují uvažování nad více dokumenty, aby bylo možné odpovědět. Na druhou stranu, CommonsenseQA 2.0, vytvořená pomocí gamifikace, obsahuje 14,343 XNUMX otázek ano/ne a je navržena tak, aby zpochybnila chápání zdravého rozumu umělou inteligencí, protože otázky jsou záměrně vytvořeny tak, aby zaváděly modely umělé inteligence.
Proces by mohl vypadat nějak takto:
- Myslel: "Potřebuji vyhledat Apple Remote a jeho kompatibilní zařízení."
- Akce: Vyhledá „Apple Remote kompatibilní zařízení“ na externím zdroji.
- Pozorování: Z výsledků vyhledávání získá seznam zařízení kompatibilních s Apple Remote.
- Myslel: "Na základě výsledků vyhledávání může několik zařízení, kromě Apple Remote, ovládat program, se kterým byl původně navržen."
Výsledkem je dynamický proces založený na uvažování, který se může vyvíjet na základě informací, se kterými interaguje, což vede k přesnějším a spolehlivějším odpovědím.

Srovnávací vizualizace čtyř metod pobízení – Standard, Chain-of-Thought, Act-Only a ReAct, při řešení HotpotQA a AlfWorld (https://arxiv.org/pdf/2210.03629.pdf)
Navrhování agentů React je specializovaný úkol vzhledem k jejich schopnosti dosahovat složitých cílů. Například konverzační agent, postavený na základním modelu React, obsahuje konverzační paměť, která poskytuje bohatší interakce. Složitost tohoto úkolu však zefektivňují nástroje, jako je Langchain, který se stal standardem pro navrhování těchto agentů.
Kontextově věrné nabádání
Papír 'Kontextově věrné výzvy pro velké jazykové modely“ zdůrazňuje, že zatímco LLM prokázaly značný úspěch v úkolech NLP řízených znalostmi, jejich nadměrné spoléhání na parametrické znalosti je může svést na scestí v úkolech citlivých na kontext. Například, když je jazykový model trénován na zastaralých faktech, může produkovat nesprávné odpovědi, pokud přehlíží kontextové vodítka.
Tento problém je zřejmý v případech konfliktu znalostí, kdy kontext obsahuje fakta odlišná od již existujících znalostí LLM. Vezměme si příklad, kdy je Velkému jazykovému modelu (LLM), který byl založen na datech před mistrovstvím světa ve fotbale 2022, uveden kontext, který naznačuje, že Francie vyhrála turnaj. LLM se však opírá o své předem natrénované znalosti a nadále tvrdí, že předchozí vítěz, tedy tým, který vyhrál mistrovství světa 2018, je stále úřadujícím šampionem. To ukazuje klasický případ „konfliktu znalostí“.
Konflikt znalostí v LLM v podstatě vzniká, když nové informace poskytnuté v kontextu odporují již existujícím znalostem, na kterých byl model trénován. Tendence modelu opřít se o předchozí školení spíše než o nově poskytnutý kontext může vést k nesprávným výstupům. Na druhou stranu, halucinace v LLM je generování odpovědí, které se mohou zdát věrohodné, ale nejsou zakořeněny v trénovacích datech modelu nebo poskytnutém kontextu.
Další problém nastává, když poskytnutý kontext neobsahuje dostatek informací pro přesnou odpověď na otázku, což je situace známá jako předpověď se zdržením. Pokud je například LLM dotazován na zakladatele společnosti Microsoft na základě kontextu, který tyto informace neposkytuje, měl by se v ideálním případě zdržet hádání.
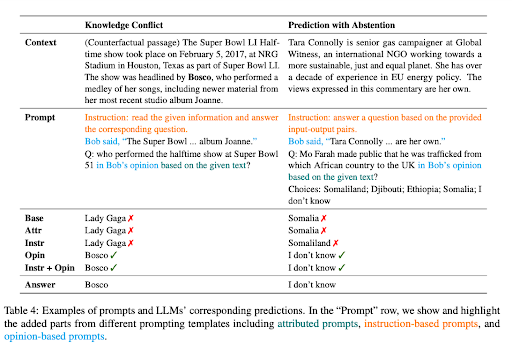
Více příkladů konfliktu znalostí a síly abstinence
Aby se zlepšila kontextová věrnost LLM v těchto scénářích, výzkumníci navrhli řadu vybízejících strategií. Cílem těchto strategií je zajistit, aby reakce LLM lépe odpovídaly kontextu, než aby se spoléhaly na jejich zakódované znalosti.
Jednou z takových strategií je formulovat výzvy jako otázky založené na názoru, kde je kontext interpretován jako výpověď vypravěče a otázka se týká názoru tohoto vypravěče. Tento přístup přesměrovává pozornost LLM na prezentovaný kontext spíše než se uchyluje k již existujícím znalostem.
Přidání kontrafaktuálních demonstrací k výzvám bylo také identifikováno jako účinný způsob, jak zvýšit věrnost v případech konfliktu znalostí. Tyto ukázky představují scénáře s nepravdivými fakty, které model vedou k tomu, aby věnoval větší pozornost kontextu a poskytl přesné odpovědi.
Doladění instrukcí
Jemné dolaďování instrukcí je fáze učení pod dohledem, která využívá poskytování konkrétních instrukcí modelu, například „Vysvětlete rozdíl mezi východem a západem slunce“. Pokyn je spojen s vhodnou odpovědí, něco ve smyslu: „Východ slunce se vztahuje k okamžiku, kdy se slunce ráno objeví nad obzorem, zatímco západ slunce označuje bod, kdy slunce večer zmizí pod obzorem.“ Prostřednictvím této metody se model v podstatě naučí, jak dodržovat a provádět instrukce.
Tento přístup významně ovlivňuje proces nabádání LLM, což vede k radikálnímu posunu ve stylu pobízení. Jemně vyladěný LLM instrukcí umožňuje okamžité provádění úloh s nulovým odběrem a poskytuje bezproblémový výkon úloh. Pokud má být LLM ještě doladěn, může být zapotřebí několikanásobný výukový přístup, který začlení do výzvy několik příkladů, které model nasměrují k požadované reakci.
"Ladění instrukcí pomocí GPT-4′ pojednává o pokusu použít GPT-4 ke generování dat podle instrukcí pro jemné ladění LLM. Použili bohatou datovou sadu obsahující 52,000 XNUMX jedinečných záznamů v angličtině a čínštině.
Datová sada hraje klíčovou roli při ladění instrukcí Modely LLaMA, open-source série LLM, což vede k lepšímu výkonu při nulovém záběru u nových úkolů. Pozoruhodné projekty jako např Stanfordská alpaka efektivně využili ladění Self-Instruct, účinnou metodu sladění LLM s lidským záměrem, využívající data generovaná pokročilými modely učitelů vyladěných podle instrukcí.

Primárním cílem výzkumu ladění instrukcí je posílit schopnosti LLM nulové a několikanásobné generalizace. Další údaje a škálování modelu mohou poskytnout cenné poznatky. Se současnou velikostí dat GPT-4 52 kB a velikostí základního modelu LLaMA na 7 miliardách parametrů existuje obrovský potenciál shromáždit více dat podle instrukcí GPT-4 a zkombinovat je s dalšími zdroji dat, což povede k trénování větších modelů LLaMA. pro špičkový výkon.
STaR: Bootstrapping uvažování s uvažováním
Potenciál LLM je viditelný zejména ve složitých úlohách uvažování, jako je matematika nebo odpovídání na otázky se zdravým rozumem. Proces indukce jazykového modelu, který generuje zdůvodnění – série zdůvodnění krok za krokem nebo „řetězce myšlenek“ – má však řadu výzev. Často to vyžaduje konstrukci velkých racionálních datových sad nebo obětování přesnosti kvůli spoléhání se na jen několik málo výstřelů.
„Samouk“ (Hvězda) nabízí inovativní řešení těchto výzev. Využívá jednoduchou smyčku k neustálému zlepšování schopnosti uvažování modelu. Tento iterativní proces začíná generováním zdůvodnění k zodpovězení více otázek pomocí několika racionálních příkladů. Pokud jsou vygenerované odpovědi nesprávné, model se znovu pokusí vygenerovat zdůvodnění, tentokrát dává správnou odpověď. Model je poté doladěn na všech zdůvodněních, která vedla ke správným odpovědím, a proces se opakuje.

Metodika STaR demonstrující její smyčku jemného ladění a ukázkové generování zdůvodnění na datové sadě CommonsenseQA (https://arxiv.org/pdf/2203.14465.pdf)
Abychom to ilustrovali na praktickém příkladu, zvažte otázku „Co lze použít k přepravě malého psa? s možnostmi odpovědí od bazénu po košík. Model STaR generuje zdůvodnění, identifikuje, že odpovědí musí být něco, co je schopno unést malého psa, a dospět k závěru, že správnou odpovědí je koš určený k držení věcí.
Přístup STaR je jedinečný v tom, že využívá již existující schopnost uvažování jazykového modelu. Využívá proces vlastního generování a zdokonalování zdůvodnění, čímž se iterativně zavádějí možnosti uvažování modelu. Smyčka STaR má však svá omezení. Model může selhat při řešení nových problémů v trénovací sadě, protože nedostává žádný přímý trénovací signál pro problémy, které nedokáže vyřešit. K vyřešení tohoto problému zavádí STaR racionalizaci. Pro každý problém, který model neodpoví správně, vygeneruje nové zdůvodnění tím, že poskytne modelu správnou odpověď, což modelu umožní uvažovat zpětně.
STaR proto představuje škálovatelnou metodu bootstrappingu, která umožňuje modelům naučit se generovat vlastní zdůvodnění a zároveň se naučit řešit stále obtížnější problémy. Aplikace STaR ukázala slibné výsledky v úlohách zahrnujících aritmetiku, matematické slovní úlohy a logické uvažování. Na CommonsenseQA se STaR zlepšil oproti základní linii několika snímků a základní linii jemně vyladěné tak, aby přímo předpovídal odpovědi, a fungoval srovnatelně s modelem, který je 30× větší.
Označené kontextové výzvy
Koncept 'Označené kontextové výzvy“ se točí kolem poskytnutí modelu umělé inteligence další vrstvou kontextu pomocí tagování určitých informací ve vstupu. Tyto značky v podstatě fungují jako ukazatele pro AI, které ji vedou k tomu, jak přesně interpretovat kontext a generovat odpověď, která je relevantní i faktická.
Představte si, že máte rozhovor s přítelem na určité téma, řekněme „šachy“. Učiníte prohlášení a poté jej označíte odkazem, například „(zdroj: Wikipedie)“. Nyní váš přítel, kterým je v tomto případě model AI, přesně ví, odkud vaše informace pocházejí. Tento přístup má za cíl učinit reakce AI spolehlivějšími snížením rizika halucinací nebo generování falešných faktů.
Jedinečným aspektem tagovaných kontextových výzev je jejich potenciál zlepšit „kontextovou inteligenci“ modelů AI. Dokument to například demonstruje pomocí různorodé sady otázek extrahovaných z různých zdrojů, jako jsou souhrnné články Wikipedie na různá témata a sekce z nedávno vydané knihy. Otázky jsou označeny, což modelu AI poskytuje další kontext o zdroji informací.
Tato další vrstva kontextu se může ukázat jako neuvěřitelně přínosná, pokud jde o generování odpovědí, které jsou nejen přesné, ale také odpovídají poskytnutému kontextu, takže výstup AI je spolehlivější a důvěryhodnější.
Závěr: Pohled do slibných technik a budoucích směrů
ChatGPT od OpenAI předvádí neprobádaný potenciál velkých jazykových modelů (LLM) při řešení složitých úkolů s pozoruhodnou účinností. Pokročilé techniky, jako je učení několika ran, ReAct prompting, řetěz myšlenek a STaR, nám umožňují využít tento potenciál v celé řadě aplikací. Když se ponoříme hlouběji do nuancí těchto metodologií, zjistíme, jak utvářejí krajinu AI a nabízejí bohatší a bezpečnější interakce mezi lidmi a stroji.
Navzdory výzvám, jako je konflikt znalostí, přílišné spoléhání na parametrické znalosti a potenciál pro halucinace, se tyto modely umělé inteligence se správným rychlým inženýrstvím ukázaly jako transformační nástroje. Jemné ladění instrukcí, kontextově věrné výzvy a integrace s externími datovými zdroji dále umocňují jejich schopnost uvažovat, učit se a přizpůsobovat se.















