
Intel·ligència Artificial
Devaluació de les accions amb retuits creats de manera adversària

Una col·laboració d'investigació conjunta entre universitats nord-americanes i IBM ha formulat un atac contradictori de prova de concepte que teòricament és capaç de causar pèrdues en borsa, simplement canviant una paraula en un retuit d'una publicació de Twitter.

En un experiment, els investigadors van poder aturar el model de predicció Stocknet amb dos mètodes: un atac de manipulació i un atac de concatenació. Font: https://arxiv.org/pdf/2205.01094.pdf
La superfície d'atac per a un atac adversari a sistemes de predicció d'estocs automatitzats i d'aprenentatge automàtic és que a nombre creixent d'ells confien en les xarxes socials orgàniques com a predictors del rendiment; i que manipular aquestes dades "en estat salvatge" és un procés que, potencialment, es pot formular de manera fiable.
A més de Twitter, sistemes d'aquesta naturalesa ingereixen dades de Reddit, StockTwits i Yahoo News, entre d'altres. La diferència entre Twitter i les altres fonts és que els retuits són editables, fins i tot si els tuits originals no ho són. D'altra banda, només és possible fer publicacions addicionals (és a dir, comentaris o relacionades) a Reddit, o comentar i puntuar, accions que són tractades correctament com a partidistes i d'autoservei per les rutines i pràctiques de sanejament de dades de les accions basades en ML. sistemes de predicció.
En un experiment, al Stocknet predicció model, els investigadors van ser capaços de provocar caigudes notables en la predicció del valor de les accions mitjançant dos mètodes, el més eficaç dels quals, l'atac de manipulació (és a dir, retuits editats), va ser capaç de provocar les caigudes més greus.
Això es va fer, segons els investigadors, simulant una única substitució en un retuit d'una font financera "respectada" de Twitter:
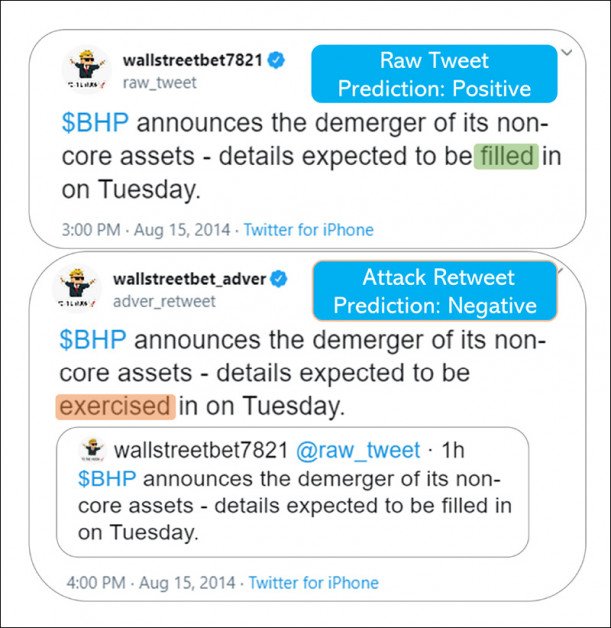
Les paraules importen. Aquí, la diferència entre "omplert" i "exercit" (no una paraula obertament maliciosa o enganyosa, sinó gairebé categoritzada com a sinònim) teòricament ha costat milers a un inversor en devaluació de les accions.
El document diu:
"Els nostres resultats mostren que el mètode d'atac proposat pot assolir taxes d'èxit consistents i causar pèrdues monetàries importants en la simulació comercial simplement concatenant un tuit pertorbat però semànticament similar".
Els investigadors conclouen:
"Aquest treball demostra que el nostre mètode d'atac adversari enganya constantment diversos models de previsió financera, fins i tot amb limitacions físiques que el tuit en brut no es pot modificar. Si afegim un retuit amb només una paraula substituïda, l'atac pot provocar una pèrdua addicional del 32% a la nostra cartera d'inversió simulada.
"Mitjançant l'estudi de la vulnerabilitat del model financer, el nostre objectiu és augmentar la consciència de la comunitat financera sobre els riscos del model d'IA, de manera que en el futur puguem desenvolupar una arquitectura d'IA humana en el bucle més robusta".
El paper es titula Una paraula val mil dòlars: un atac adversari als piulats Predicció d'accions dels ximples, i prové de sis investigadors, provinents de la Universitat d'Illinois Urbana-Champaign, la Universitat Estatal de Nova York a Buffalo i la Universitat Estatal de Michigan, amb tres dels investigadors afiliats a IBM.
Paraules desafortunades
El document examina si el camp ben estudiat dels atacs adversaris als models d'aprenentatge profund basats en text és aplicable als models de predicció del mercat de valors, la capacitat de previsió dels quals depèn d'uns factors molt "humans" que només es poden inferir aproximadament de les fonts de les xarxes socials.
Com assenyalen els investigadors, el potencial de la manipulació de les xarxes socials per afectar els preus de les accions ha estat ben demostrat, tot i que encara no pels mètodes proposats en el treball; el 2013 a tuit maliciós reclamat per Síria al compte de Twitter piratejat de l'Associated Press va esborrar 136 milions de dòlars de valor de mercat de valors en uns tres minuts.
El mètode proposat en el nou treball implementa un atac de concatenació, que deixa intac el tuit original, tot i que el cita malament:

A partir del material complementari del treball, exemples de retuits que contenen sinònims substituïts que canvien la intenció i la significació del missatge original, sense distorsionar-lo de manera que els humans o els filtres simples puguin captar, però que poden explotar els algorismes en sistemes de predicció de la borsa.
Els investigadors s'han plantejat la creació de retuits adversaris com optimització combinatòria problema: l'elaboració d'exemples adversaris capaços d'enganyar un model de víctima, fins i tot amb un vocabulari molt limitat.
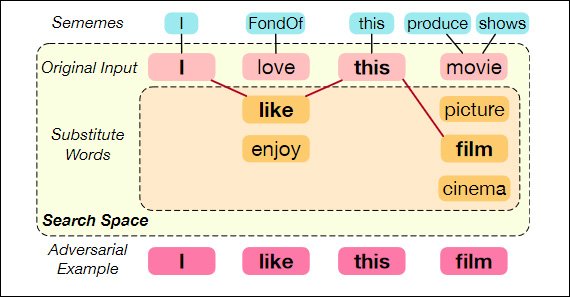
Substitució de paraules utilitzant sememes – la "unitat semàntica mínima de les llengües humanes". Font: https://aclanthology.org/2020.acl-main.540.pdf
El document observa:
"En el cas de Twitter, els adversaris poden publicar tuits maliciosos que estan dissenyats per manipular models aigües avall que els prenen com a entrada.
"Proposem atacar mitjançant la publicació de tuits adversaris semànticament similars com a retuits a Twitter, de manera que es puguin identificar com a informació rellevant i recopilar-los com a entrada del model".
Per a cada piulada d'un grup especialment seleccionat, els investigadors van resoldre el problema de selecció de paraules sota les limitacions dels pressupostos de paraules i tweets, que posen restriccions severes en termes de divergència semàntica de la paraula original i la substitució d'una paraula "maliciosa/benigne". .
Els tuits adversaris es formulen a partir de tuits pertinents que probablement es permetran als sistemes de predicció d'estocs aigües avall. El tuit també ha de passar sense obstacles pel sistema de moderació de contingut de Twitter i no ha de semblar contrafactual per a l'observador humà casual.
Següent treball previ (de la Michigan State University, juntament amb CSAIL, MIT i el MIT-IBM Watson AI Lab), les paraules seleccionades al tuit objectiu se substitueixen per sinònims d'un conjunt limitat de possibilitats de sinònims, tots els quals han d'estar semànticament molt a prop de l'original. paraula, tot mantenint la seva "influència corruptora", basada en el comportament inferit dels sistemes de predicció de la borsa.
Els algorismes utilitzats en els experiments posteriors van ser el solucionador Joint Optimization (JO) i el solucionador Alternating Greedy Optimization (AGO).
Conjunts de dades i experiments
Aquest enfocament es va provar en un conjunt de dades de predicció d'accions que inclou 10,824 exemples de tuits pertinents i informació sobre el rendiment del mercat en 88 accions entre 2014-2016.
Es van triar tres models de "víctimes": Stocknet; FinGRU (un derivat de GRU); i FinLSTM (un derivat de LSTM).
Les mètriques d'avaluació consistien en la taxa d'èxit d'atac (ASR) i una caiguda en el model de víctimes. Puntuació F1 després de l'atac adversari. Els investigadors van simular a Compra-Retenció-Venda només a llarg termini estratègia per a les proves. Els guanys i pèrdues (PnL) també es van calcular en les simulacions.

Resultats dels experiments. Vegeu també el primer gràfic a la part superior d'aquest article.
Sota JO i AGO, l'ASR augmenta un 10% i la puntuació F1 del model baixa un 0.1 de mitjana, en comparació amb un atac aleatori. Els investigadors assenyalen:
"Aquesta caiguda del rendiment es considera significativa en el context de la predicció d'accions, atès que la precisió de predicció d'última generació del rendiment entre dies és només d'un 60%.'
En el tram de pèrdues i guanys de l'atac (virtual) a Stocknet, els resultats dels retuits adversaris també van ser destacables:
'Per a cada simulació, l'inversor té 10 dòlars (100%) per invertir; els resultats mostren que el mètode d'atac proposat amb un retuit amb només una paraula de substitució pot causar a l'inversor una pèrdua addicional de 3.2 mil dòlars (75%-43%) a la seva cartera després d'uns 2 anys".
Publicat per primera vegada el 4 de maig de 2022.













