
Intel·ligència Artificial
Andrew Ng critica la cultura del sobreajust en l'aprenentatge automàtic
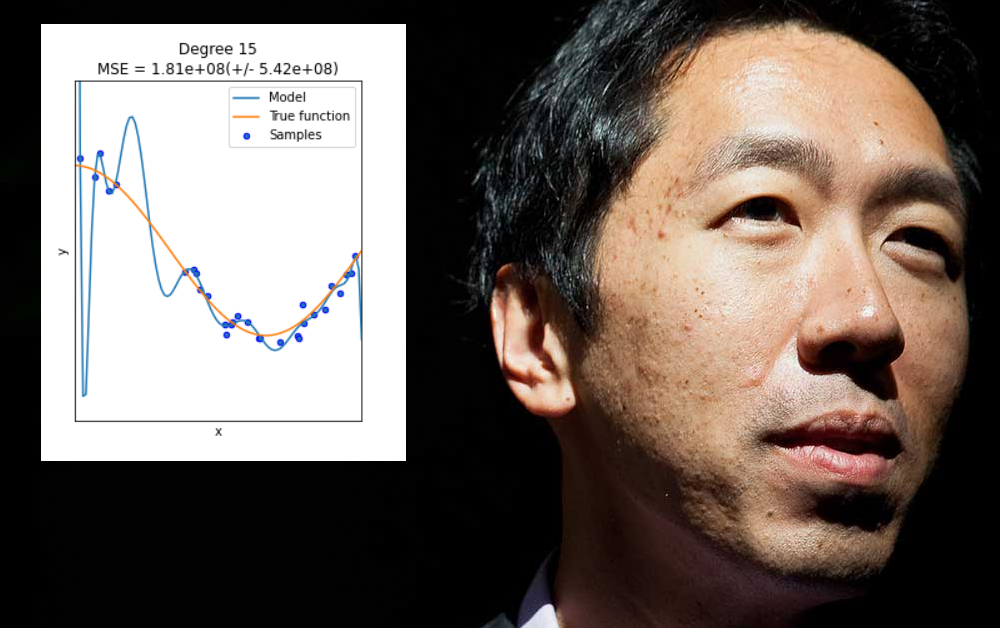
Andrew Ng, una de les veus més influents en l'aprenentatge automàtic durant l'última dècada, actualment està expressant la seva preocupació sobre fins a quin punt el sector posa èmfasi en les innovacions en l'arquitectura de models per sobre de les dades, i específicament, fins a quin punt permet que els resultats "sobreajustats" es descriuen com a solucions o avenços generalitzats.
Aquestes són crítiques contundents a la cultura actual de l'aprenentatge automàtic, que emanen d'una de les seves màximes autoritats, i tenen implicacions per a la confiança en un sector assetjat per pors sobre un tercer col·lapse de la confiança empresarial en el desenvolupament de la IA en un espai de seixanta anys.
Ng, professor de la Universitat de Stanford, també és un dels fundadors de deeplearning.ai, i al març va publicar un missiva al lloc de l'organització que va destil·lar a discurs recent del seu es redueix a un parell de recomanacions bàsiques:
En primer lloc, que la comunitat investigadora s'hauria de deixar de queixar-se que la neteja de dades representa el 80% dels reptes de l'aprenentatge automàtic i continuar amb la feina de desenvolupar metodologies i pràctiques MLOps sòlides.
En segon lloc, que s'hauria d'allunyar dels "guanys fàcils" que es poden obtenir mitjançant l'ajustament excessiu de dades a un model d'aprenentatge automàtic, de manera que funcioni bé en aquest model, però no aconsegueixi generalitzar o produir un model àmpliament desplegable.
Acceptant el repte de l'arquitectura i la curació de dades
"La meva opinió", va escriure Ng. "és que si el 80 per cent del nostre treball és la preparació de dades, aleshores garantir la qualitat de les dades és la tasca important d'un equip d'aprenentatge automàtic".
I va continuar:
"En lloc de comptar amb els enginyers per trobar la millor manera de millorar un conjunt de dades, espero que puguem desenvolupar eines MLOps que ajudin a crear sistemes d'IA, inclosa la creació de conjunts de dades d'alta qualitat, més repetibles i sistemàtics.
'MLOps és un camp naixent i diferents persones el defineixen de manera diferent. Però crec que el principi organitzatiu més important dels equips i les eines MLOps hauria de ser garantir el flux de dades coherent i d'alta qualitat en totes les etapes d'un projecte. Això ajudarà a que molts projectes surtin millor".
Parlant a Zoom en una transmissió en directe Sessió de preguntes i respostes a finals d'abril, Ng va abordar el dèficit d'aplicabilitat en els sistemes d'anàlisi d'aprenentatge automàtic per a radiologia:
"Resulta que quan recollim dades de l'Hospital de Stanford, entrenem i provem amb dades del mateix hospital, de fet, podem publicar articles que demostrin que [els algorismes] són comparables als radiòlegs humans en detectar determinades condicions.
"...[Quan] portes el mateix model, el mateix sistema d'IA, a un hospital més antic al carrer, amb una màquina més antiga, i el tècnic utilitza un protocol d'imatge lleugerament diferent, les dades es desvien per provocar que el rendiment del sistema d'IA degradar significativament. En canvi, qualsevol radiòleg humà pot caminar pel carrer fins a l'hospital més antic i fer-ho bé".
La subespecificació no és una solució
El sobreajust es produeix quan un model d'aprenentatge automàtic està dissenyat específicament per adaptar-se a les excentricitats d'un conjunt de dades particular (o de la forma en què es formen les dades). Això pot implicar, per exemple, especificar ponderacions que produiran bons resultats a partir d'aquest conjunt de dades, però no "generalitzen" en altres dades.
En molts casos, aquests paràmetres es defineixen en aspectes "no de dades" del conjunt d'entrenament, com ara la resolució específica de la informació recopilada o altres idiosincràsies que no es garanteix que es tornin a produir en altres conjunts de dades posteriors.
Tot i que estaria bé, l'excés d'adaptació no és un problema que es pugui resoldre ampliant cegament l'abast o la flexibilitat de l'arquitectura de dades o el disseny del model, quan el que realment es necessita són característiques d'aplicació àmplia i molt destacades que funcionen bé en una sèrie de dades. entorns: un repte més espinós.
En general, aquest tipus de "subespecificació" només condueix als mateixos problemes que Ng ha esbossat darrerament, on un model d'aprenentatge automàtic falla en dades no vistes. La diferència en aquest cas és que el model falla no perquè les dades o el format de les dades siguin diferents del conjunt d'entrenament original sobreajustat, sinó perquè el model és massa flexible i no massa trencadís.
A finals del 2020 el paper La subespecificació presenta reptes per a la credibilitat en l'aprenentatge automàtic modern va fer crítiques intenses contra aquesta pràctica i va portar els noms de no menys de quaranta investigadors i científics d'aprenentatge automàtic de Google i el MIT, entre altres institucions.
El document critica l'"aprenentatge de drecera" i observa la forma en què els models poc especificats poden enlairar-se a les tangents salvatges en funció del punt de llavor aleatori en què comença l'entrenament del model. Els col·laboradors observen:
"Hem vist que la subespecificació és omnipresent en canalitzacions pràctiques d'aprenentatge automàtic a molts dominis. De fet, gràcies a la subespecificació, aspectes substancialment importants de les decisions estan determinats per eleccions arbitràries, com ara la llavor aleatòria utilitzada per a la inicialització de paràmetres.'
Ramificacions econòmiques del canvi de cultura
Malgrat les seves credencials erudites, Ng no és un acadèmic clar, però té una experiència profunda i d'alt nivell en la indústria com a cofundador de Google Brain i Coursera, com a antic científic en cap de Big Data i IA a Baidu, i com a fundador de Landing AI, que administra 175 milions de dòlars per a noves startups del sector.
Quan diu "Tota l'IA, no només l'assistència sanitària, té una bretxa entre la prova de concepte i la producció", es pretén com una trucada d'atenció a un sector el nivell actual de bombo i història l'han caracteritzat cada cop més com a una inversió empresarial incerta a llarg termini, assetjat per problemes de definició i abast.
No obstant això, els sistemes propietaris d'aprenentatge automàtic que funcionen bé in situ i fallen en altres entorns representen el tipus de captura de mercat que podria recompensar la inversió de la indústria. Presentar el "problema de sobreadaptació" en el context d'un risc laboral ofereix una manera falsa de Monetitzar inversió corporativa en investigació de codi obert i per produir sistemes propietaris (eficaçment) on la replicació per part dels competidors sigui possible, però problemàtica.
El fet que aquest enfocament funcioni o no a llarg termini depèn de la mesura en què els avenços reals en l'aprenentatge automàtic continuïn requerint. nivells d'inversió cada cop més grans, i si totes les iniciatives productives migraran inevitablement a FAANG fins a cert punt, a causa dels recursos colossals necessaris per a l'allotjament i les operacions.















