
Intel·ligència Artificial
RigNeRF: un nou mètode Deepfakes que utilitza camps de radiació neuronal

La nova investigació desenvolupada a Adobe ofereix el primer mètode deepfakes viable i eficaç basat en Camps de radiació neuronal (NeRF): potser la primera innovació real en arquitectura o enfocament en els cinc anys des de l'aparició dels deepfakes el 2017.
El mètode, titulat RigNeRF, usos Models de cares morfables en 3D (3DMMs) com a capa intersticial d'instrumentalitat entre l'entrada desitjada (és a dir, la identitat que s'ha d'imposar al render de NeRF) i l'espai neuronal, un mètode que s'ha àmpliament adoptat en els darrers anys per enfocaments de síntesi facial de Generative Adversarial Network (GAN), cap dels quals encara ha produït marcs de substitució de cares funcionals i útils per al vídeo.

A diferència dels vídeos deepfake tradicionals, absolutament cap del contingut en moviment que es mostra aquí és "real", sinó que és un espai neuronal explorable que es va entrenar amb imatges breus. A la dreta veiem el model de cara morphable 3D (3DMM) actuant com a interfície entre les manipulacions desitjades ('somriu', 'mirar a l'esquerra', 'mirar amunt', etc.) i els paràmetres habitualment intractables d'un camp de radiació neuronal. visualització. Per obtenir una versió d'alta resolució d'aquest clip, juntament amb altres exemples, vegeu pàgina del projecte, o els vídeos incrustats al final d'aquest article. Font: https://shahrukhathar.github.io/2022/06/06/RigNeRF.html
Els 3DMM són efectivament models CGI de cares, els paràmetres dels quals es poden adaptar a sistemes de síntesi d'imatges més abstractes, com NeRF i GAN, que d'altra manera són difícils de controlar.
El que esteu veient a la imatge de dalt (imatge del mig, home amb camisa blava), així com la imatge directament a sota (imatge esquerra, home amb camisa blava), no és un vídeo "real" en el qual hi ha un petit pegat de " La cara falsa s'ha superposat, però una escena completament sintetitzada que existeix únicament com una representació neuronal volumètrica, inclòs el cos i el fons:

A l'exemple anterior, el vídeo de la vida real de la dreta (dona amb vestit vermell) s'utilitza per "titella" la identitat capturada (home amb camisa blava) a l'esquerra a través de RigNeRF, que (els autors afirmen) és el primer Sistema basat en NeRF per aconseguir la separació de la postura i l'expressió alhora que és capaç de realitzar síntesis de visualitzacions noves.
La figura masculina de l'esquerra de la imatge superior es va "capturar" a partir d'un vídeo de 70 segons de telèfon intel·ligent, i les dades d'entrada (inclosa tota la informació de l'escena) es van entrenar posteriorment a través de 4 GPU V100 per obtenir l'escena.
Atès que els equips paramètrics d'estil 3DMM també estan disponibles com a proxis CGI paramètrics de cos sencer (en lloc de només equips facials), RigNeRF obre potencialment la possibilitat de falsificacions profundes de cos sencer on el moviment humà real, la textura i l'expressió es transmeten a la capa paramètrica basada en CGI, que després traduiria l'acció i l'expressió en entorns i vídeos NeRF renderitzats. .
Pel que fa a RigNeRF, es qualifica com un mètode deepfake en el sentit actual que els titulars entenen el terme? O és només un altre semi-coblat que també va anar a DeepFaceLab i a altres sistemes de deepfake de codificació automàtica de l'era 2017 que requereixen mà d'obra?
Els investigadors del nou article no són ambigus en aquest punt:
"En ser un mètode capaç de reanimar cares, RigNeRF és propens a un mal ús per part dels actors dolents per generar falsificacions profundes".
El nou paper es titula RigNeRF: Retrats 3D neuronals totalment controlables, i prové de ShahRukh Atha de la Universitat de Stonybrook, becari a Adobe durant el desenvolupament de RigNeRF, i quatre autors més d'Adobe Research.
Més enllà dels Deepfakes basats en codificadors automàtics
La majoria dels deepfakes virals que han capturat titulars durant els últims anys són produïts per codificador automàticsistemes basats en -, derivats del codi que es va publicar al subreddit r/deepfakes que va ser immediatament prohibit el 2017, encara que no abans de ser copiat a GitHub, on actualment s'ha bifurcat més de mil vegades, sobretot en el popular (si polèmic) DeepFaceLab distribució, i també la Canvi de cara projecte.
A més de GAN i NeRF, els marcs de codificació automàtica també han experimentat amb 3DMM com a "directrius" per millorar els marcs de síntesi facial. Un exemple d'això és el Projecte HifiFace a partir de juliol de 2021. No obstant això, no sembla que fins ara s'hagi desenvolupat cap iniciativa utilitzable o popular a partir d'aquest enfocament.
Les dades de les escenes RigNeRF s'obtenen capturant vídeos curts de telèfon intel·ligent. Per al projecte, els investigadors de RigNeRF van utilitzar un iPhone XR o un iPhone 12 per a tots els experiments. Durant la primera meitat de la captura, se li demana al subjecte que realitzi una àmplia gamma d'expressions facials i de parla mentre manté el cap immòbil mentre la càmera es mou al seu voltant.
Durant la segona meitat de la captura, la càmera manté una posició fixa mentre el subjecte ha de moure el cap mentre mostra una àmplia gamma d'expressions. Els 40-70 segons de metratge resultants (uns 1200-2100 fotogrames) representen tot el conjunt de dades que s'utilitzarà per entrenar el model.
Reducció de la recollida de dades
Per contra, els sistemes de codificació automàtica com DeepFaceLab requereixen la recopilació i curació relativament laboriosa de milers de fotografies diverses, sovint extretes de vídeos de YouTube i altres canals de xarxes socials, així com de pel·lícules (en el cas de deepfakes de celebritats).
Els models d'autocodificador entrenats resultants solen utilitzar-se en una varietat de situacions. Tanmateix, els deepfakers "celebritats" més exigents poden entrenar models sencers des de zero per a un sol vídeo, malgrat que l'entrenament pot trigar una setmana o més.
Malgrat la nota d'advertència dels investigadors del nou document, sembla poc probable que el "patchwork" i els conjunts de dades àmpliament reunits que alimenten la pornografia amb intel·ligència artificial i les populars "refunds deepfake" de YouTube/TikTok produeixin resultats acceptables i coherents en un sistema deepfake com RigNeRF. que té una metodologia específica de l'escenari. Tenint en compte les restriccions a la captura de dades descrites en el nou treball, això podria demostrar, fins a cert punt, una salvaguarda addicional contra l'apropiació indeguda de la identitat per part de deepfakers maliciosos.
Adaptació de NeRF al vídeo Deepfake
NeRF és un mètode basat en fotogrametria en què un petit nombre d'imatges font preses des de diversos punts de vista s'ajunten en un espai neuronal 3D explorable. Aquest enfocament va cobrar protagonisme a principis d'aquest any quan NVIDIA va presentar el seu NeRF instantani sistema, capaç de reduir els temps d'entrenament exorbitants per a NeRF a minuts o fins i tot segons:

NeRF instantani. Font: https://www.youtube.com/watch?v=DJ2hcC1orc4
L'escena del camp de radiació neuronal resultant és essencialment un entorn estàtic que es pot explorar, però que sí difícil d'editar. Els investigadors assenyalen que dues iniciatives prèvies basades en NeRF: HyperNeRF + E/P i NerFACE - han fet una punyalada a la síntesi de vídeo facial i (aparentment per raó de la integritat i la diligència) han posat RigNeRF contra aquests dos marcs en una ronda de proves:


Una comparació qualitativa entre RigNeRF, HyperNeRF i NerFACE. Consulteu els vídeos d'origen enllaçats i el PDF per obtenir versions de més qualitat. Font de la imatge estàtica: https://arxiv.org/pdf/2012.03065.pdf
No obstant això, en aquest cas els resultats, que afavoreixen RigNeRF, són força anòmals, per dos motius: en primer lloc, els autors observen que "no existeix cap treball per a una comparació poma amb poma"; en segon lloc, això ha requerit la limitació de les capacitats de RigNeRF per coincidir almenys parcialment amb la funcionalitat més restringida dels sistemes anteriors.
Com que els resultats no són una millora incremental del treball anterior, sinó que representen un "avenç" en l'editabilitat i la utilitat de NeRF, deixarem de banda la ronda de proves i veurem què està fent RigNeRF de manera diferent als seus predecessors.
Fortaleses combinades
La principal limitació de NerFACE, que pot crear un control de pose/expressió en un entorn NeRF, és que suposa que el metratge d'origen es capturarà amb una càmera estàtica. Això significa efectivament que no pot produir visions noves que s'estengui més enllà de les seves limitacions de captura. Això produeix un sistema que pot crear "retrats en moviment", però que no és adequat per a vídeos d'estil deepfake.
HyperNeRF, d'altra banda, tot i que és capaç de generar visions noves i hiperreals, no té cap instrument que li permeti canviar les posicions del cap o les expressions facials, cosa que de nou no es tradueix en cap tipus de competidor per als deepfakes basats en codificadors automàtics.
RigNeRF és capaç de combinar aquestes dues funcionalitats aïllades creant un "espai canònic", una línia de base predeterminada a partir de la qual es poden activar desviacions i deformacions mitjançant l'entrada del mòdul 3DMM.
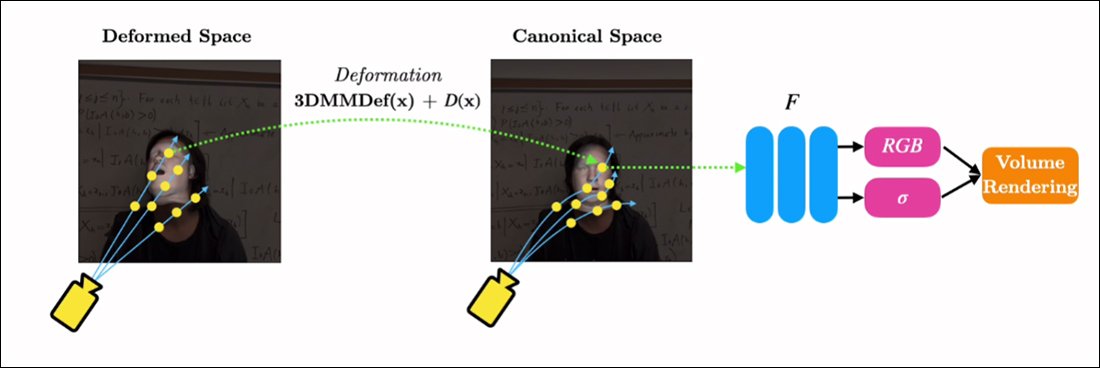
Creació d'un 'espai canònic' (sense pose, sense expressió), sobre el qual poden actuar les deformacions (és a dir, posicions i expressions) produïdes a través del 3DMM.
Com que el sistema 3DMM no coincidirà exactament amb el subjecte capturat, és important compensar-ho en el procés. RigNeRF ho aconsegueix amb un camp de deformació anterior que es calcula a partir de a Perceptron multicapa (MLP) derivat del material d'origen.

Els paràmetres de la càmera necessaris per calcular les deformacions s'obtenen mitjançant COLMAP, mentre que s'obtenen els paràmetres d'expressió i forma de cada fotograma DECA.
El posicionament s'optimitza encara més ajust de referència i els paràmetres de la càmera de COLMAP i, a causa de les restriccions de recursos informàtics, la sortida de vídeo es redueix a una resolució de 256 × 256 per a l'entrenament (un procés de reducció restringit pel maquinari que també afecta l'escena de deepfaking del codificador automàtic).
Després d'això, la xarxa de deformació s'entrena als quatre V100: un maquinari formidable que probablement no estigui a l'abast dels entusiastes ocasionals (no obstant això, pel que fa a l'entrenament d'aprenentatge automàtic, sovint és possible canviar molt per temps i acceptar simplement aquest model). l'entrenament serà qüestió de dies o fins i tot setmanes).
En conclusió, els investigadors afirmen:
"A diferència d'altres mètodes, RigNeRF, gràcies a l'ús d'un mòdul de deformació guiat per 3DMM, és capaç de modelar la postura del cap, les expressions facials i l'escena completa del retrat en 3D amb alta fidelitat, donant així millors reconstruccions amb detalls nítids".
Vegeu els vídeos incrustats a continuació per obtenir més detalls i imatges de resultats.


Publicat per primera vegada el 15 de juny de 2022.















