
Изкуствен интелект
Google предвижда система за заявки, подобна на GPT-3, без резултати от търсенето

Нова статия от четирима изследователи на Google предлага „експертна“ система, способна да отговаря авторитетно на въпросите на потребителите, без да представя списък с възможни резултати от търсенето, подобно на парадигмата за въпроси и отговори, която привлече общественото внимание чрез появата на GPT-3 в миналото година.
- хартия, озаглавена Преосмисляне на търсенето: създаване на експерти от дилетантите, предполага, че настоящият стандарт за представяне на потребителя със списък с резултати от търсене в отговор на запитване е „когнитивна тежест“ и предлага подобрения в способността на система за обработка на естествен език (NLP) да предоставя авторитетен и окончателен отговор .
Съгласно предложения модел на „експертен“, междудомейнен оракул, хилядите възможни източници на резултати от търсенето ще бъдат изпечени в езиков модел, вместо да бъдат изрично достъпни като проучвателен ресурс, за да могат потребителите да оценяват и навигират сами. Източник: https://arxiv.org/pdf/2105.02274.pdf
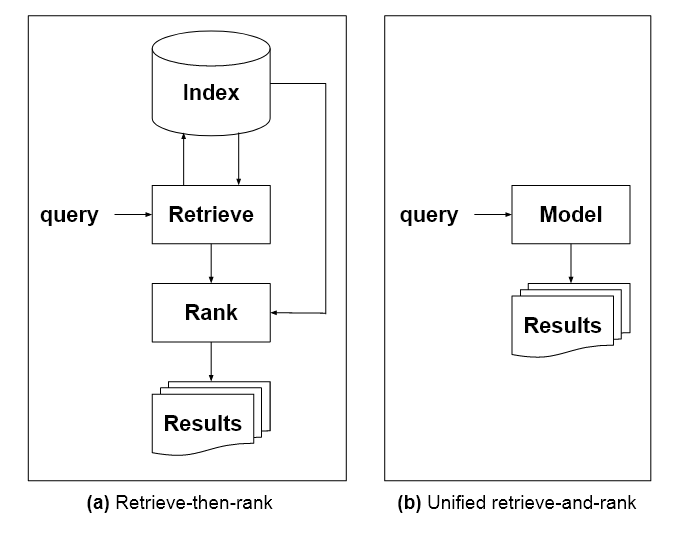
Докладът, ръководен от Доналд Мецлър от Google Research, предлага подобрения в типа отговори на оракули с много домейни, които в момента могат да бъдат получени от авторегресивни езикови модели за дълбоко обучение като GPT-3. Основните предвидени подобрения са: а) че моделът ще може да цитира точно източниците, които са информирали отговора, и б) че моделът ще бъде предотвратен от 'халюциниращ' отговори или измисляне на несъществуващ изходен материал, което в момента е проблем с такива архитектури.
Мултидомейн обучение и възможности
Освен това предложеният езиков модел, характеризиран в документа като „Единен модел за всички задачи за извличане на информация“, ще бъде обучен в различни области, включително изображения и текст. Също така ще се нуждае от разбиране за произхода на знанието, което липсва в архитектурите в стил GPT-3.
„За да се заменят индексите с единичен унифициран модел, трябва да е възможно самият модел да има знания за вселената от идентификатори на документи, по същия начин, по който го правят традиционните индекси. Един от начините да постигнете това е да се отдалечите от традиционните LM и да се насочите към корпусни модели, които съвместно моделират връзките термин-термин, термин-документ и документ-документ.'

На изображението по-горе, от статията, три подхода в отговор на потребителско запитване: отляво, езиковите модели, имплицитни в резултатите от алгоритмичното търсене на Google, са избрали и приоритизирали „най-добрия отговор“, но са го оставили като най-добрия резултат от много. Център, разговорен отговор в стил GPT-3, който говори авторитетно, но не обосновава своите твърдения или цитира източници. Точно така, предложената експертна система включва „най-добрия отговор“ от класираните резултати от търсенето директно в дидактически отговор, с цитати под линия в академичен стил (които не са изобразени в оригиналното изображение), указващи източниците, които информират отговора.
Премахване на отровни и неточни резултати
Изследователите отбелязват, че динамичният и постоянно актуализиран характер на индексите за търсене е предизвикателство за пълно копиране в модел на машинно обучение от този характер. Например, когато някога доверен източник е бил обучен директно в разбирането на света от модела, премахването на влиянието му (например, след като е дискредитиран) може да бъде по-трудно, отколкото просто премахване на URL от SERP, тъй като концепциите за данни могат да станат абстрактни и широко представени по време на асимилация в обучението.
Освен това, такъв модел ще трябва да бъде непрекъснато обучаван, за да осигури същото ниво на отзивчивост към нови статии и публикации, както в момента се осигурява от постоянното търсене на източници от Google. На практика това означава непрекъснато и автоматизирано внедряване, за разлика от сегашния режим, при който се правят незначителни промени в теглата и настройките на алгоритъма за търсене в свободна форма, но самият алгоритъм обикновено се актуализира само рядко.
Повърхности за атака за централизиран експертен оракул
Централизиран модел, който постоянно асимилира и обобщава нови данни, може да трансформира повърхността на атаката за запитвания за търсене.
Понастоящем атакуващият може да извлече полза чрез постигане на високо класиране за домейни или страници, които съдържат дезинформация или злонамерен код. Под егидата на по-непрозрачен „експертен“ оракул, възможността за пренасочване на потребителите към атакуващи домейни е значително намалена, но възможността за инжектиране на отровни атаки с данни е значително увеличена.
Това е така, защото предложената система не елиминира алгоритъма за класиране при търсене, но го скрива от потребителя, като ефективно автоматизира приоритета на най-добрия резултат/и и го (или тях) изпича в дидактическо изявление. Злонамерените потребители отдавна са в състояние да организират атаки срещу алгоритъма за търсене на Google, за да продават фалшиви продукти, директни потребители към домейни, разпространяващи зловреден софтуер, или за целите на политическа манипулация, сред много други случаи на употреба.
Не AGI
Изследователите подчертават, че е малко вероятно подобна система да се квалифицира като Изкуствен общ интелект (AGI) и поставят перспективата за универсален експертен отговор в контекста на обработката на естествения език, предмет на всички предизвикателства, пред които са изправени подобни модели в момента.
Документът очертава пет изисквания за „висококачествен“ отговор:
1: Авторитет
Както при настоящите алгоритми за класиране, „авторитетът“ изглежда се извлича от цитиране от висококачествени домейни, които се считат за авторитетни сами по себе си. Изследователите отбелязват:
„Отговорите трябва да генерират съдържание чрез извличане от високо авторитетни източници. Това е друга причина, поради която установяването на по-ясни връзки между поредици от термини и метаданни на документа е толкова важно. Ако всички документи в даден корпус са анотирани с оценка за авторитетност, тази оценка трябва да се вземе предвид при обучение на модела, генериране на отговори или и двете.'
Въпреки че изследователите не предполагат, че резултатите от традиционните SERPs биха станали недостъпни, ако се установи, че експертен оракул от този тип е ефективен и популярен, цялата статия представя традиционната система за класиране и списъците с резултати от търсенето в светлината на десетилетия стара“ и остаряла система за извличане на информация.
„Самият факт, че класирането е критичен компонент на тази парадигма, е симптом на системата за извличане, предоставяща на потребителите селекция от потенциални отговори, което предизвиква доста значителна когнитивна тежест върху потребителя. Желанието да се върнат отговори вместо класирани списъци с резултати беше един от мотивиращите фактори за разработването на системи за отговори на въпроси. '
2: Прозрачност
Изследователите коментират:
„Когато е възможно, произходът на информацията, която се представя на потребителя, трябва да му бъде предоставен. Това ли е основният източник на информация? Ако не, какъв е основният източник?'
3: Справяне с пристрастия
Документът отбелязва, че предварително обучените езикови модели са предназначени не да оценяват емпиричната истина, а да обобщават и дават приоритет на доминиращите тенденции в данните. Той признава, че тази директива отваря модела за атака (както се случи с Microsoft неволно расистки чатбот през 2016 г.) и че ще са необходими спомагателни системи за защита срещу подобни предубедени реакции на системата.
4: Разрешаване на различни гледни точки
Документът също така предлага механизми за осигуряване на множество гледни точки:
„Генерираните отговори трябва да представляват набор от различни гледни точки, но не трябва да поляризират. Например, за запитвания относно спорни теми и двете страни на темата трябва да бъдат обхванати по справедлив и балансиран начин. Това очевидно има тясна връзка с пристрастията към модела.
5: Достъпен език
Освен предоставянето на точни преводи в случаите, когато смятаният за авторитетен отговор е на различен език, документът предполага, че капсулираните отговори трябва да бъдат „написани с възможно най-ясни думи“.















