
Изкуствен интелект
Андрю Нг критикува културата на пренастройване в машинното обучение
Андрю Нг, един от най-влиятелните гласове в областта на машинното обучение през последното десетилетие, в момента изразява загриженост относно степента, в която секторът набляга на иновациите в архитектурата на модела пред данните – и по-конкретно, степента, в която позволява „прекомерно оборудвани“ резултати да бъдат изобразени като обобщени решения или напредък.
Това са широкообхватни критики към настоящата култура на машинно обучение, произтичащи от един от нейните най-високи авторитети, и имат последици за доверието в сектор, обзет от страхове за трети колапс на доверието на бизнеса в развитието на ИИ в рамките на шестдесет години.
Нг, професор в Станфордския университет, също е един от основателите на deeplearning.ai и през март публикува послание на сайта на организацията, която дестилира a скорошна реч от него до няколко основни препоръки:
Първо, че изследователската общност трябва да спре да се оплаква, че почистването на данни представлява 80% от предизвикателствата в машинното обучение и да се заеме с работата по разработването на стабилни MLOps методологии и практики.
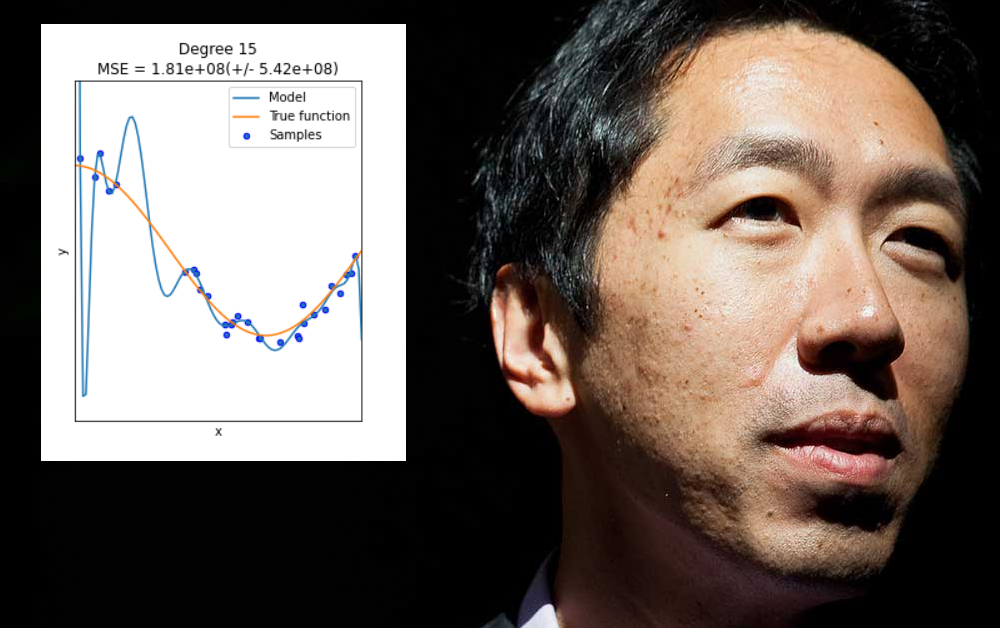
Второ, че трябва да се отдалечи от „лесните печалби“, които могат да бъдат получени чрез прекомерно приспособяване на данни към модел за машинно обучение, така че да се представя добре на този модел, но да не успява да обобщи или да произведе модел за широко разгръщане.
Приемане на предизвикателството на архитектурата и управлението на данни
„Моето виждане“, написа Нг. „е, че ако 80 процента от нашата работа е подготовка на данни, тогава осигуряването на качеството на данните е важната работа на екип за машинно обучение.“
Той продължи:
„Вместо да разчитам на инженерите да намерят най-добрия начин за подобряване на набор от данни, надявам се, че можем да разработим MLOps инструменти, които помагат да се направи изграждането на AI системи, включително изграждането на висококачествени набори от данни, по-повтаряеми и систематични.
„MLOps е зараждаща се област и различните хора я определят по различен начин. Но мисля, че най-важният организационен принцип на екипите и инструментите на MLOps трябва да бъде осигуряването на последователен и висококачествен поток от данни през всички етапи на проекта. Това ще помогне на много проекти да вървят по-гладко.“
Говорейки в Zoom при предаване на живо Въпроси и отговори в края на април Ng обърна внимание на липсата на приложимост в системите за анализ на машинно обучение за радиология:
„Оказва се, че когато събираме данни от болница Станфорд, след това обучаваме и тестваме върху данни от същата болница, наистина можем да публикуваме статии, показващи, че [алгоритмите] са сравними с хора радиолози при откриване на определени състояния.
„…[Когато] занесете същия модел, същата AI система, в по-стара болница надолу по улицата, с по-стара машина, и техникът използва малко по-различен протокол за изображения, тези данни се отклоняват, за да причинят производителността на AI системата разграждат значително. За разлика от това, всеки рентгенолог може да се разходи по улицата до по-старата болница и да се справи добре.
Недостатъчната спецификация не е решение
Пренастройването възниква, когато моделът на машинно обучение е специално проектиран да приспособява ексцентрицитетите на конкретен набор от данни (или на начина, по който данните са форматирани). Това може да включва, например, определяне на тегла, които ще дадат добри резултати от този набор от данни, но няма да „обобщават“ други данни.
В много случаи такива параметри се дефинират върху аспекти, които не са свързани с данни, на набора за обучение, като конкретната разделителна способност на събраната информация или други особености, за които не е гарантирано, че ще се появят отново в други последващи набори от данни.
Въпреки че би било хубаво, пренастройването не е проблем, който може да бъде решен чрез сляпо разширяване на обхвата или гъвкавостта на архитектурата на данните или дизайна на модела, когато това, което всъщност е необходимо, са широко приложими и силно забележими функции, които ще се представят добре в набор от данни среда – по-трудно предизвикателство.
Като цяло този тип „недостатъчна спецификация“ води само до същите проблеми, които Ng очерта напоследък, при които моделът на машинно обучение се проваля при невидими данни. Разликата в този случай е, че моделът се проваля не защото данните или форматирането на данните са различни от прекомерно оборудвания оригинален комплект за обучение, а защото моделът е твърде гъвкав, а не твърде чуплив.
В края на 2020 г хартия Недостатъчната спецификация представлява предизвикателство за надеждността в съвременното машинно обучение отправя остри критики срещу тази практика и носи имената на не по-малко от четиридесет изследователи и учени в областта на машинното обучение от Google и MIT, наред с други институции.
Документът критикува „бързото обучение“ и наблюдава начина, по който недостатъчно определени модели могат да излетят при диви допирателни въз основа на произволната начална точка, в която започва обучението на модела. Сътрудниците отбелязват:
„Видяхме, че недостатъчната спецификация е повсеместна в практическите тръбопроводи за машинно обучение в много области. В действителност, благодарение на недостатъчната спецификация, съществено важните аспекти на решенията се определят от произволни избори, като например произволно начално число, използвано за инициализация на параметър.'
Икономически последици от промяната на културата
Въпреки научните си пълномощия, Нг не е ефирен академик, но има задълбочен опит в индустрията на високо ниво като съосновател на Google Brain и Coursera, като бивш главен учен за Big Data и AI в Baidu и като основател на Landing AI, който администрира 175 милиона щатски долара за нови стартиращи компании в сектора.
Когато той казва „Цялото ИИ, не само здравеопазването, има пропуск от доказване на концепцията до производство“, това е предназначено като сигнал за събуждане към сектор, чието сегашно ниво на реклама и забелязана история все повече го характеризира като несигурна дългосрочна бизнес инвестиция, засегнат по проблеми на дефиницията и обхвата.
Независимо от това, собствените системи за машинно обучение, които работят добре на място и се провалят в други среди, представляват вид завладяване на пазара, който може да възнагради инвестициите в индустрията. Представянето на „проблема с прекомерното оборудване“ в контекста на професионален риск предлага неискрен начин за осигуряване на приходи от корпоративни инвестиции в изследвания с отворен код и за създаване на (ефективно) патентовани системи, където копирането от конкуренти е възможно, но проблематично.
Дали този подход ще работи или не в дългосрочен план зависи от степента, в която продължават да се изискват истински пробиви в машинното обучение все по-високи нива на инвестициии дали всички продуктивни инициативи неизбежно ще мигрират към FAANG до известна степен, поради колосалните ресурси, необходими за хостинг и операции.















