
Изкуствен интелект
Управлявана от изкуствен интелект проверка на пристрастия за новинарски статии, налична в Python

Изследователи от Канада, Индия, Китай и Австралия си сътрудничиха, за да създадат свободно достъпен пакет на Python, който може ефективно да се използва за откриване и заместване на „нечестния език“ в копие на новини.
Системата, озаглавена Dbias, използва различни технологии за машинно обучение и бази данни, за да разработи триетапен кръгов работен процес, който може да прецизира тенденциозен текст докато не върне непредубедена или поне по-неутрална версия.

Зареденият език в новинарски фрагмент, идентифициран като „предубеден“, се трансформира в по-малко възпламенителна версия от Dbias. Източник: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
Системата представлява многократно използваем и самостоятелен тръбопровод, който може да бъде инсталиран чрез Pip от Hugging Face и интегриран в съществуващи проекти като допълнителен етап, добавка или плъгин.
През април подобна функционалност е внедрена в Google Документи попадна под критика, не на последно място поради липсата на възможност за редактиране. Dbias, от друга страна, може да бъде по-селективно обучен върху всеки корпус от новини, който крайният потребител желае, запазвайки способността си да разработва индивидуални насоки за справедливост.
Критичната разлика е, че тръбопроводът Dbias е предназначен да трансформира автоматично „заредения език“ (думи, които добавят критичен слой към фактическата комуникация) в неутрален или прозаичен език, вместо да обучава потребителя непрекъснато. По същество крайният потребител ще дефинира етични филтри и съответно ще обучи системата; в подхода на Google Docs системата – вероятно – обучава потребителя по едностранен начин.
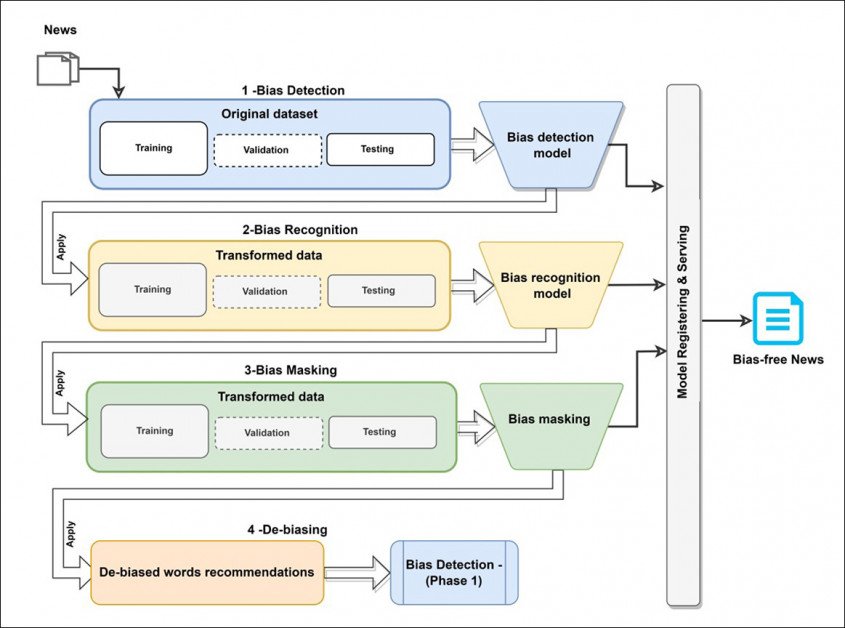
Концептуална архитектура за работния процес на Dbias.
Според изследователите Dbias е първият наистина конфигурируем пакет за откриване на пристрастия, за разлика от готовите проекти за сглобяване, които характеризират този подсектор на обработката на естествен език (NLP) до момента.
- нова хартия е озаглавен Подход за гарантиране на справедливост в новинарските статии, и идва от сътрудници в Университета на Торонто, Метрополитен университет в Торонто, Управление на екологичните ресурси в Бангалор, Академия на науките DeepBlue в Китай и Университета на Сидни.
Начин на доставка
Първият модул в Dbias е Откриване на пристрастия, който използва DistilBERT пакет – силно оптимизирана версия на доста машинно интензивния пакет на Google БЕРТ. За проекта DistilBERT беше прецизно настроен на анотацията за медийни пристрастия (MBIC) набор от данни.

MBIC се състои от новинарски статии от различни медийни източници, включително Huffington Post, USA Today и MSNBC. Изследователите са използвали разширената версия на набора от данни.
Въпреки че оригиналните данни бяха анотирани от краудсорсинг работници (метод, който пожар в края на 2021 г.), изследователите на новата статия успяха да идентифицират допълнителни немаркирани случаи на отклонение в набора от данни и ги добавиха ръчно. Идентифицираните случаи на пристрастие, свързани с раса, образование, етническа принадлежност, език, религия и пол.
Следващият модул, Разпознаване на пристрастия, използва Разпознаване на име на обект (NER), за да отделите предубедени думи от въведения текст. Документът гласи:
„Например, новината „Не вярвайте на псевдонаучната реклама за торнадо и изменението на климата“ е класифицирана като предубедена от предходния модул за откриване на отклонения, а модулът за предубедено разпознаване вече може да идентифицира термина „псевдонаучна реклама“ като пристрастна дума.'
NER не е специално проектиран за тази задача, но е използван преди за идентифициране на пристрастия, особено за a 2021 проект от университета Дърам във Великобритания.
За този етап изследователите са използвали RoBERTa комбиниран с тръбопровода SpaCy English Transformer NER.

Следващият етап, Маскиране на пристрастия, включва нова множествена маска на идентифицираните пристрастни думи, която работи последователно в случаи на множество идентифицирани пристрастни думи.

Зареденият език се заменя с прагматичен език в третия етап на Dbias. Имайте предвид, че „говорене с уста“ и „използване“ се равняват на едно и също действие, въпреки че първото се счита за подигравателно.
Ако е необходимо, обратната връзка от този етап ще бъде изпратена обратно в началото на процеса за по-нататъшна оценка, докато не бъдат генерирани редица подходящи алтернативни фрази или думи. Този етап използва моделиране на маскиран език (MLM) по линиите, установени от a 2021 сътрудничество водени от Facebook Research.
Обикновено задачата за MLM ще маскира 15% от думите на случаен принцип, но работният поток на Dbias вместо това казва на процеса да вземе идентифицираните предубедени думи като вход.
Архитектурата е внедрена и обучена в Google Colab Pro на NVIDIA P100 с 24 GB VRAM при партиден размер от 16, като се използват само два етикета (диагонален намлява безпристрастен).
Тестове
Изследователите тестваха Dbias срещу пет сравними подхода: LG-TFIDF с Логистична регресия намлява TfidfVectorizer (TFIDF) вграждане на думи; LG-ELMO; MLP-ELMO (изкуствена невронна мрежа с подаване напред, съдържаща ELMO вграждания); БЕРТ; и RoBERTa.
Метриките, използвани за тестовете, бяха точност (ACC), прецизност (PREC), припомняне (Rec) и F1 резултат. Тъй като изследователите не са знаели за съществуваща система, която може да изпълни и трите задачи в един конвейер, е направено освобождаване за конкуриращите се рамки, като се оценяват само основните задачи на Dbias – откриване и разпознаване на отклонения.

Резултати от изпитанията на Dbias.
Dbias успя да надмине резултатите от всички конкурентни рамки, включително тези с по-тежък процесорен отпечатък
В статията се посочва:
„Резултатът също така показва, че дълбоките невронни вграждания като цяло могат да надминат традиционните методи за вграждане (напр. TFIDF) в задачата за класифициране на отклонения. Това се вижда от по-добрата производителност на дълбоките вграждания на невронни мрежи (т.е. ELMO) в сравнение с TFIDF векторизацията, когато се използва с LG.
„Това вероятно е така, защото дълбоките невронни вграждания могат по-добре да уловят контекста на думите в текста в различни контексти. Дълбоките невронни вграждания и дълбоките невронни методи (MLP, BERT, RoBERTa) също се представят по-добре от традиционния ML метод (LG).'
Изследователите също така отбелязват, че методите, базирани на трансформатор, превъзхождат конкурентните методи при откриване на пристрастия.
Допълнителен тест включваше сравнение между Dbias и различни варианти на SpaCy Core Web, включително core-sm (малък), core-md (среден) и core-lg (голям). Dbias успя да ръководи борда и в тези изпитания:

Изследователите заключават, като отбелязват, че задачите за разпознаване на пристрастия обикновено показват по-добра точност в по-големи и по-скъпи модели, поради - те спекулират - на увеличения брой параметри и точки от данни. Те също така отбелязват, че ефикасността на бъдещата работа в тази област ще зависи от по-големите усилия за анотиране на висококачествени масиви от данни.
Гората и дърветата
Надяваме се, че този вид проект за фино разпознаване на пристрастия в крайна сметка ще бъде включен в рамки за търсене на пристрастия, които са в състояние да възприемат по-малко късогледство и да вземат под внимание, че изборът да се покрие всяка конкретна история само по себе си е акт на пристрастие, който потенциално е водени от повече от отчетени статистики за гледане.
Първо публикувано на 14 юли 2022 г.















