الذكاء الاصطناعي
نحو إنشاء أشخاص ذكاء اصطناعي في الوقت الفعلي باستخدام تقنية Neural Lumigraph Rendering

على الرغم من الموجة الحالية من الاهتمام بتقنية Neural Radiance Fields (NeRF)، وهي تقنية قادرة على إنشاء بيئات وكيانات ثلاثية الأبعاد بواسطة الذكاء الاصطناعي، فإن هذه النهج الجديد لتقنية 합성 الصور لا تزال تتطلب وقتًا طويلاً للتدريب، وتنقصها تنفيذًا يسمح بالواجهات عالية الاستجابة في الوقت الفعلي.
然而، يُقدم تعاون بين بعض الأسماء المثيرة في الصناعة والأكاديمية نهجًا جديدًا لهذه التحدي (المعروف بشكل عام باسم Novel View Synthesis، أو NVS).
يُدعي البحث الورقة، المعنونة Neural Lumigraph Rendering، تحسينًا على الحالة الحالية بمقدار تقريبًا من أمرين من حيث الحجم، مما يمثل خطوات عديدة نحو تقديم رسومات حاسوبية في الوقت الفعلي عبر أنابيب الذكاء الاصطناعي.

Neural Lumigraph Rendering (right) offers better resolution of blending artifacts, and improved handling of occlusion over previous methods. Source.
على الرغم من أن الائتمانات للورقة تشير فقط إلى جامعة ستانفورد وشركة Raxium للعرض الهولوجرافي (التي تعمل حاليًا في وضع السرية)، فإن المساهمين يشملون مهندسًا رئيسيًا للتعلم الآلي في جوجل، وعالِم كمبيوتر في أدوبي، والمدير التقني في StoryFile (الذي أثار ضجة إعلامية مؤخرًا بإنشاء نسخة ذكاء اصطناعي من ويليام شاتنر).
فيما يتعلق بالحملة الإعلامية الأخيرة لشاتنر، يبدو أن StoryFile يستخدم NLR في عملية جديدة لإنشاء كيانات تفاعلية محددة بالذكاء الاصطناعي بناءً على سمات وقصص الأفراد.
تتخيل StoryFile استخدام هذه التقنية في عروض المتاحف، والروايات التفاعلية عبر الإنترنت، وعروض الهولوجرافيا، والواقع المعزز (AR)، ووثائق التراث – ويبدو أيضًا أنها تهدف إلى تطبيقات جديدة لـ NLR في مقابلات التوظيف والتطبيقات العاطفية الافتراضية:

الاستخدامات المقترحة من فيديو عبر الإنترنت بواسطة StoryFile. Source: https://www.youtube.com/watch?v=2K9J6q5DqRc
التقاط الحجمي ل_interfaces و Novel View Synthesis و الفيديو
مبدأ التقاط الحجمي، عبر مجموعة من الأوراق التي تتراكم على هذا الموضوع، هو فكرة أخذ صور ثابتة أو فيديوهات لموضوع، واستخدام التعلم الآلي لملء وجهات النظر التي لم تغطها مصفوفة الكاميرات الأصلية.

Source: https://research.fb.com/wp-content/uploads/2019/06/Neural-Volumes-Learning-Dynamic-Renderable-Volumes-from-Images.pdf
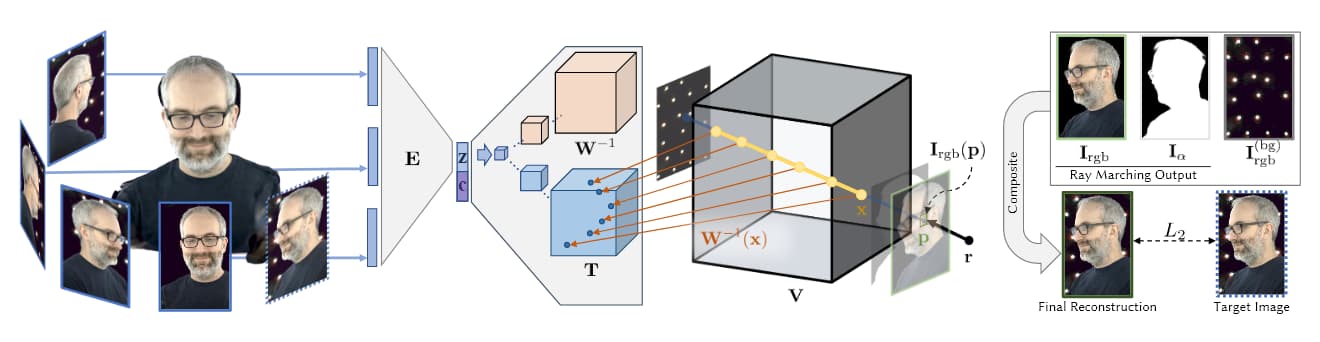
في الصورة أعلاه، التي تم أخذها من بحث Facebook AI في عام 2019 (انظر أدناه)، نرى المراحل الأربع لالتقاط الحجمي: الحصول على صور أو لقطات من عدة كاميرات؛ بنية التشفير / فك التشفير (أو بنى أخرى) لحساب ودمج العلاقات بين وجهات النظر؛ خوارزميات المسار لحساب وحدات XYZ الجغرافية المكانية لكل نقطة في الفضاء الحجمي؛ والتدريب (في معظم الأوراق الحديثة) ل 合نثيس entity كاملة يمكن تعاملها في الوقت الفعلي.
هذه المرحلة الشاملة والثقيلة من التدريب هي التي أبقت حتى الآن Novel View Synthesis خارج نطاق التقاط أو الاستجابة في الوقت الفعلي.
الواقع أن Novel View Synthesis يخلق خريطة ثلاثية الأبعاد كاملة للمكان الحجمي، مما يجعل من السهل نسبيًا خياطة هذه النقاط معًا في شبكة حاسوبية تقليدية، مما يسمح بالتقاط وتوضيح كيان CGI بشري (أو أي كيان محدد آخر) على الفور.
المناهج التي تستخدم NeRF تعتمد على سحابة النقاط وخرائط العمق لتوليد الاستيفاءات بين وجهات النظر النادرة لأجهزة التقاط:

NeRF can generate volumetric depth through calculation of depth maps, rather than generation of CG meshes. Source: https://www.youtube.com/watch?v=JuH79E8rdKc
على الرغم من أن NeRF قادر على حساب الشبكات، إلا أن معظم التنفيذات لا تستخدم هذا لإنشاء مشاهد حجمية.
في المقابل، تعتمد نهج Implicit Differentiable Renderer (IDR)، المنشور من قبل معهد Weizmann للعلوم في أكتوبر 2020، على استغلال معلومات الشبكة ثلاثية الأبعاد التي تم إنشاؤها تلقائيًا من مصفوفات التقاط:

Examples of IDR captures turned into interactive CGI meshes. Source: https://www.youtube.com/watch?v=C55y7RhJ1fE
في حين أن NeRF يفتقر إلى قدرة IDR على تقدير الشكل، إلا أن IDR لا يمكنه مطابقة جودة الصورة التي توفرها NeRF، ويتطلب كلاهما موارد مكثفة للتدريب والتحليل (على الرغم من أن الابتكارات الحديثة في NeRF بدأت معالجة هذا).

NLR’s Custom camera rig featuring 16 GoPro HERO7 and 6 central Back-Bone H7PRO cameras. For ‘real time’ rendering, these operate at a minimum of 60fps. Source: https://arxiv.org/pdf/2103.11571.pdf
بدلاً من ذلك، يستخدم Neural Lumigraph Rendering SIREN (Sinusoidal Representation Networks) لدمج نقاط القوة من كل نهج في إطار العمل الخاص به، والذي يهدف إلى توليد مخرجات يمكن استخدامها مباشرة في أنابيب الرسومات الحاسوبية في الوقت الفعلي.
تم استخدام SIREN لتنفيذات م tương tự خلال العام الماضي، و现在 يمثل呼び出し API شائعًا للمجتمعات التفاعلية ل合نثيس الصور؛ ومع ذلك، فإن الابتكار في NLR يتمثل في تطبيق SIRENs على إشراف الصور ثنائية الأبعاد متعددة وجهات النظر، وهو ما يثير مشكلة بسبب مدى تأثير SIREN على الإنتاج المفرط بدلاً من الإنتاج المتعمق.
بعد استخراج الشبكة ثلاثية الأبعاد من صور المصفوفة، يتم تحويل الشبكة إلى صورة ثنائية الأبعاد عبر OpenGL، وتمثل مواقع الرأس في الشبكة إلى البكسل المناسب، وبعد ذلك يتم حساب التمازج للخرائط المساهمة المختلفة.
الشبكة الناتجة أكثر تعميمًا وتمثيلًا من تلك التي توفرها NeRF (انظر الصورة أدناه)، وتتطلب حسابات أقل، ولا تطبق تفاصيل زائدة في المناطق (مثل البشرة الناعمة للوجه) التي لا يمكن أن تستفيد منها:

Source: https://arxiv.org/pdf/2103.11571.pdf
من الجانب السلبي، لا يزال NLR يفتقر إلى القدرة على الإضاءة الديناميكية أو إعادة الإضاءة، ويتحدد الإخراج بخرائط الظلال والاعتبارات الإضاءية الأخرى التي تم الحصول عليها في وقت التقاط. يعتزم الباحثون معالجة هذا في الأعمال المستقبلية.
بالإضافة إلى ذلك، يقر الورقة بأن الأشكال التي تم إنشاؤها بواسطة NLR ليست دقيقة مثل بعض النهج البديلة، مثل Pixelwise View Selection for Unstructured Multi-View Stereo، أو البحث في معهد Weizmann المذكور أعلاه.
صعود合نثيس الصور الحجمية
فكرة إنشاء كيانات ثلاثية الأبعاد من سلسلة محدودة من الصور باستخدام الشبكات العصبية تسبق NeRF، مع أوراق رؤية تعود إلى عام 2007 أو قبل ذلك. في عام 2019، أنتج قسم البحث في شركة Facebook ورقة بحثية رائدة، Neural Volumes: Learning Dynamic Renderable Volumes from Images، والتي أتاحت للمرة الأولى واجهات استجابة لكيانات اصطناعية تم إنشاؤها بواسطة تقنية التقاط الحجمي بالذكاء الاصطناعي.

Facebook’s 2019 research enabled the creation of a responsive user interface for a volumetric person. Source: https://research.fb.com/publications/neural-volumes-learning-dynamic-renderable-volumes-from-images/













{kind=link}