الذكاء الاصطناعي
ثورة MoE: كيف يغير التوجيه المتقدم والتخصص النماذج اللغة الكبيرة
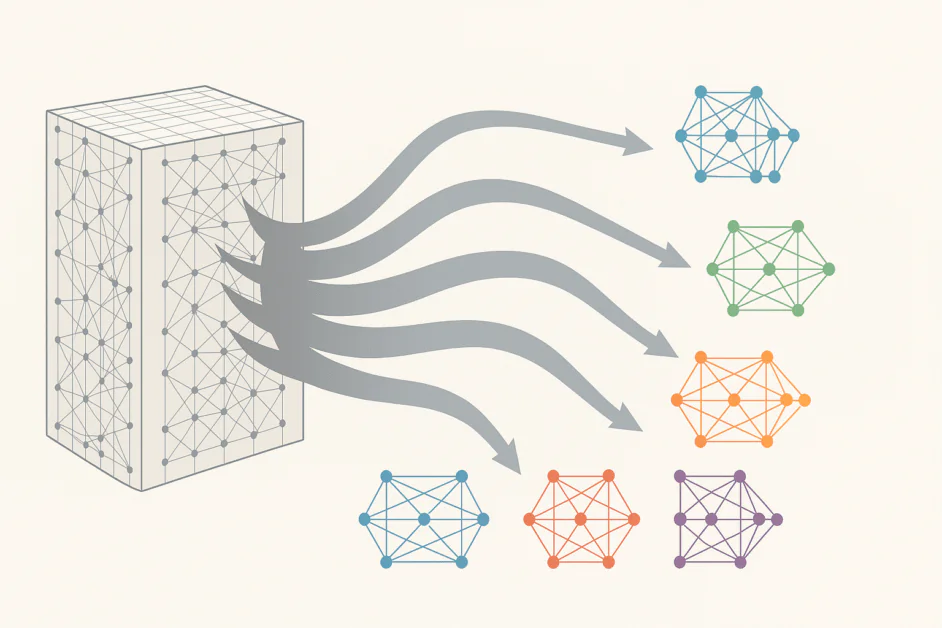
في غضون بضع سنوات ، توسعت نماذج اللغة الكبيرة (LLMs) من ملايين إلى مئات البلايين من المعلمات ، مما يظهر التقدم المذهل في khảية هندسة ونطاق النظامين الكبيرين. وقد قدمت هذه الأنظمة الكبيرة قدرات مذهلة مثل كتابة النص السلس ، وتوليد الشفرة ، والتفكير في المشكلات المعقدة ، والمشاركة في الحوار البشري. ولكن هذا التوسع السريع يأتي مع تكلفة كبيرة. يستهلك تدريب وتشغيل مثل هذه النماذج الهائلة كميات غير عادية من القوة الحاسوبية والطاقة والرأس المال. استراتيجية “الأكبر هو أفضل” التي كانت تؤدي إلى التقدم في الماضي ، بدأت تظهر حدودها. في الاستجابة للقيود المتزايدة ، تتطور معمارية الذكاء الاصطناعي المعروفة باسم مزيج من الخبراء (MoE) لتقديم طريق أكثر ذكاء وفعالية لتحسين نماذج اللغة الكبيرة. بدلاً من الاعتماد على شبكة واحدة كبيرة ومفعلة دائمًا ، يقسم MoE النموذج إلى مجموعة من الشبكات الفرعية المتخصصة أو “الخبراء” ، كل منها مدرب على التعامل مع أنواع معينة من البيانات أو المهام. من خلال التوجيه الذكي ، يفعّل النموذج فقط الخبراء الأكثر صلة لكل إدخال لتقليل العبء الحاسوبي مع الحفاظ على الأداء أو تحسينه. هذه القدرة على مزج القابلية للتوسيع مع الفعالية تجعل MoE واحدة من أبرز المفاهيم الناشئة في مجال الذكاء الاصطناعي. يبحث هذا المقال في كيفية قيادة التوجيه المتقدم والتخصص هذه التحولات وما يعنيه ذلك لمستقبل الأنظمة الذكية.
فهم الهندسة الأساسية
فكرة مزيج من الخبراء (MoE) ليست جديدة. تعود إلى أساليب التعلم المتعاون في التسعينيات. ما تغير هو التكنولوجيا التي تجعلها تعمل. فقط في السنوات الأخيرة ، أصبحت التطورات في الأجهزة والتوجيه الخوارزمي تجعل من الممكن إحضار هذا المفهوم إلى نماذج اللغة الحديثة القائمة على النماذج المحولة.
في جوهره ، يعيد MoE تعريف الشبكة العصبية الكبيرة كمجموعة من الشبكات الفرعية الصغيرة المتخصصة ، كل منها مدرب على التعامل مع نوع معين من البيانات أو المهام. بدلاً من تفعيل كل معامل لكل إدخال ، يقدم MoE آلية توجيه تقرر أي خبراء هي الأكثر صلة لإدخال معين أو تسلسل. النتيجة هي نموذج يستخدم فقط جزءًا صغيرًا من معاملاته في أي وقت معين ، مما يقلل بشكل كبير من الطلب الحاسوبي مع الحفاظ على الأداء أو تحسينه.
في الممارسة ، يسمح هذا التحول الهندسي للباحثين بتحسين النماذج إلى تريليونات المعلمات دون الحاجة إلى زيادة متناسبة في الموارد الحاسوبية. إنه يُستبدل الطبقات الكثيفة الأمامية بالشبكات الثابتة بأسلوب أكثر ذكاء وديناميكية. تحتوي كل طبقة MoE على خبراء متعددين ، وعادةً شبكات أمامية صغيرة ، وشبكة توجيه أو شبكة تحكم تقرر أي خبراء يجب أن يعالجوا كل إدخال. تعمل شبكة التوجيه مثل مدير مشروع ، ترسل الأسئلة ذات الصلة إلى كل خبير. مع مرور الوقت ، يتعلم النظام أي الخبراء يؤدون بشكل أفضل لمختلف أنواع المشكلات ، مما يُحسن استراتيجية التوجيه أثناء التدريب.
يوفر هذا التصميم مزيجًا مذهلاً من النطاق والفعالية. على سبيل المثال ، DeepSeek V3 ، واحدة من نماذج MoE الأكثر تقدمًا ، تستخدم 685 مليار معامل ، لكنها تفعّل فقط جزءًا صغيرًا منها أثناء الاستدلال. تقدم أداء نموذج كبير مع متطلبات حاسوبية وطاقة أقل بشكل كبير.
تطور آليات التوجيه
المرشح هو قلب MoE ، حيث يحدد أي خبراء يعالجون كل إدخال. استخدمت النماذج المبكرة استراتيجيات بسيطة ، حيث تُختار الخبراء الأفضل بناءً على الأوزان المكتسبة. النظم الحديثة أكثر تعقيدًا.
اليوم ، تُعد آليات التوجيه الديناميكية أكثر تطورًا ، حيث تُعدل عدد الخبراء النشطين بناءً على تعقيد الإدخال. قد تحتاج السؤال البسيط إلى خبير واحد فقط ، بينما قد تحتاج المهام الصعبة إلى تفعيل عدة خبراء.implemented DeepSeek-V2 توجيهًا محدودًا بالأجهزة لتحكم تكاليف الاتصال عبر الأجهزة الموزعة. DeepSeek-V3 رائدة استراتيجيات خالية من الخسارة المساعدة التي تسمح بتخصص خبراء أكثر ثراء دون تدهور الأداء.
المرشحات المتقدمة تعمل الآن كمسؤولين ذكيين للموارد ، حيث تُعدل استراتيجيات الاختيار بناءً على خصائص الإدخال أو عمق الشبكة أو ملاحظات الأداء في الوقت الفعلي. يبحث بعض الباحثين في تعلم التعزيز لتحسين الأداء طويل الأمد. تقنيات مثل التوجيه الناعم تمكن من اختيار خبراء أكثر سلاسة ، بينما يستخدم التوجيه الاحتمالي الأساليب الإحصائية لتحسين المهام.
التخصص ي驱ّن الأداء
الوعد الأساسي لمزيج الخبراء (MoE) هو أن التخصص العميق يفوق التعميم الواسع. يركز كل خبير على إتقان مجالات معينة بدلاً من أن يكون متواضعًا في كل شيء. خلال التدريب ، توجيه آليات دائمًا أنواع معينة من الإدخال نحو خبراء معينين ، مما يخلق حلقة تغذية راجعة قوية. بعض الخبراء يمتازون في البرمجة ، بينما يمتاز آخرون في المصطلحات الطبية أو الكتابة الإبداعية.
然而 ، تحقيق هذا الهدف يقدم تحديات. يمكن أن تعيق استراتيجيات التوزع التقليدية بشكلironic تخصص الخبراء عن طريق إجبار استخدام الخبراء بشكل موحد. ومع ذلك ، يتطور المجال بسرعة. الدراسات تُظهر أن نماذج MoE المتقنة تُظهر تخصصًا واضحًا ، حيث يهيمن خبراء مختلفون في مجالاتهم الخاصة. الدراسات تؤكد أن آليات التوجيه تلعب دورًا فعالًا في تشكيل هذا التقسيم الهندسي للعمل.
الاستراتيجيات التي تستخدم خبراء مفتاح المجال أظهرت تحسينات ملحوظة في الأداء. على سبيل المثال ، أفاد الباحثون بزيادة دقة بنسبة 3.33٪ في الأساس المعياري AIME2024. عندما يعمل التخصص ، تكون النتائج مذهلة. DeepSeek V3 يتفوق على GPT-4o في معظم معايير اللغة الطبيعية ويقود في جميع مهام البرمجة والاستدلال الرياضي ، وهو إنجاز مثير للإعجاب لنظام مفتوح المصدر.
التأثير العملي على قدرات النموذج
ثورة MoE قد قدمت تحسينات ملموسة في قدرات النموذج الأساسية. يمكن للنماذج الآن التعامل مع سياقات أطول بكفاءة أكبر؛ يمكن لكل من DeepSeek V3 و GPT-4o معالجة 128K رمز في إدخال واحد ، مع تحسين هندسة MoE الأداء ، خاصة في المجالات الفنية. هذا أمر حاسم للتطبيقات مثل تحليل قواعد بيانات كاملة أو معالجة وثائق قانونية طويلة.
المكاسب في الكفاءة التكلفة أكثر دراماتيكية. التحليل يُظهر أن DeepSeek-V3 هو تقريبًا 29.8 مرة أقل تكلفة لكل رمز مقارنةً بـ GPT-4o. هذا الفرق في السعر يجعل الذكاء الاصطناعي متاحًا لمستخدمين وتطبيقات أوسع. إنه يسرع بشكل كبير من تعميم الذكاء الاصطناعي.
علاوة على ذلك ، فإن الهندسة تمكن من نشر أكثر استدامة. لا يزال تدريب نموذج MoE يتطلب موارد كبيرة ، لكن التكلفة المنخفضة بشكل كبير للاستدلال تفتح الطريق لنظام أكثر كفاءة واقتصاديًا للشركات والعملاء على حد سواء.
التحديات والطريق إلى الأمام
尽管 هناك مزايا كبيرة ، MoE ليست خالية من التحديات. يمكن أن يكون التدريب غير مستقر ، حيث يفشل الخبراء أحيانًا في التخصص كما هو موصوف. عانت النماذج المبكرة من “انهيار التوجيه ،” حيث يهيمن خبير واحد. يجب ضمان حصول جميع الخبراء على بيانات تدريب كافية أثناء تفعيل جزء فقط منهم ، مما يتطلب توازن دقيقًا.
أهم عائق هو عبء الاتصال. في إعدادات GPU الموزعة ، يمكن أن تستهلك تكاليف الاتصال ما يصل إلى 77٪ من وقت المعالجة. يتعاون العديد من الخبراء بشكل مفرط ، ويتفاعلون بشكل متكرر ويتطلبون نقل البيانات المتكرر عبر معززات الأجهزة. هذا يدفع إلى إعادة تقييم أساسية لتصميم الأجهزة الذكية.
تُشكل متطلبات الذاكرة تحديًا كبيرًا آخر. بينما تقلل MoE من التكاليف الحاسوبية أثناء الاستدلال ، يجب تحميل جميع الخبراء في الذاكرة ، مما يضغط على الأجهزة الحوافز أو البيئات المحدودة الموارد. لا يزال تفسير النتائج أيضًا تحديًا رئيسيًا ، حيث يضيف تحديد الخبير الذي ساهم في إخراج معين طبقة أخرى من التعقيد إلى الهندسة. يبحث الباحثون الآن في طرق لتتبع تفعيل الخبراء وتصور مسارات اتخاذ القرار ، بهدف جعل أنظمة MoE أكثر شفافية وسهولة في المراجعة.
الخلاصة
مزيج الخبراء (MoE) ليس مجرد معمارية جديدة ، بل فلسفة جديدة لإنشاء نماذج الذكاء الاصطناعي. من خلال الجمع بين التوجيه الذكي والتخصص على مستوى المجال ، يتحقق MoE ما يبدو متناقضًا في السابق: نطاق أكبر مع حساب أقل. بينما تستمر التحديات في الاستقرار والاتصال والتفسير ، فإن توازنها من الكفاءة والتنوع والدقة يشير إلى مستقبل أنظمة الذكاء الاصطناعي التي ليست أكبر فقط ، بل أكثر ذكاءً أيضًا.












