الذكاء الاصطناعي
SofGAN: نظام توليد وجوه قائم على GAN يوفر سيطرة أكبر
قام باحثون في شنغهاي والولايات المتحدة بتطوير نظام توليد صور بورتريه قائم على GAN يسمح للمستخدمين بإنشاء وجوه جديدة بمستوى من السيطرة غير المتاحة من قبل على الجوانب الفردية مثل الشعر والعين والنظارات والقوام واللون.
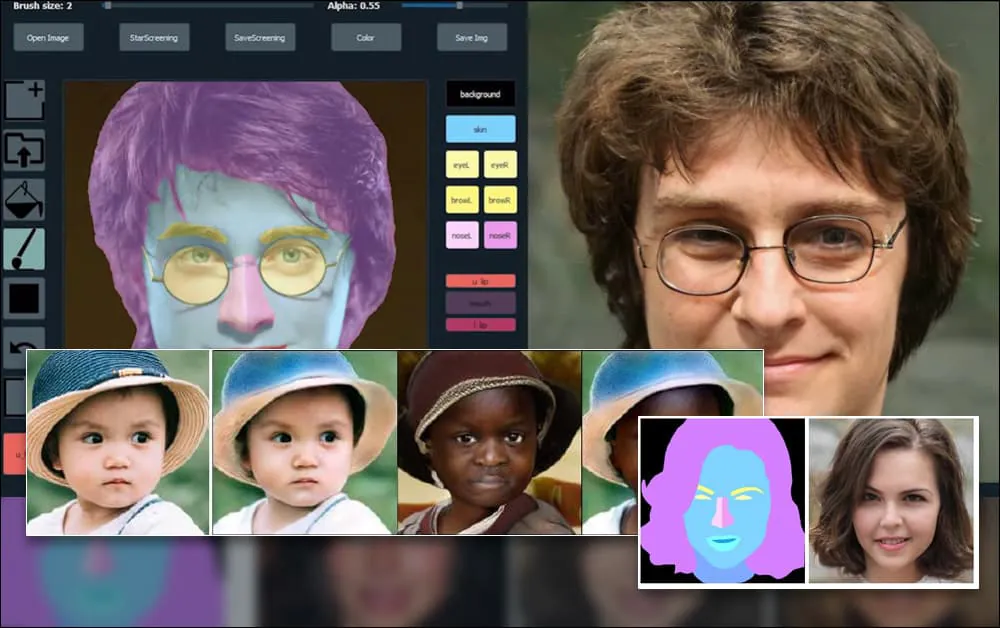
لإظهار مرونة النظام، قدمت المبتكرون واجهة شبيهة ببرنامج Photoshop حيث يمكن للمستخدم رسم عناصر التجزئة الدلالية مباشرة والتي ستفسر على أنها صور واقعية، ويمكن حتى الحصول عليها عن طريق الرسم مباشرة على الصور الموجودة.
في المثال أدناه، يتم استخدام صورة الممثل دانيال رادكليف كقالب تتبع (والهدف ليس إنتاج شبه له، ولكن صورة واقعية بشكل عام). عند ملء المستخدم للعديد من العناصر، بما في ذلك الجوانب المنفصلة مثل النظارات، يتم تحديدها وتفسيرها في صورة الإخراج:
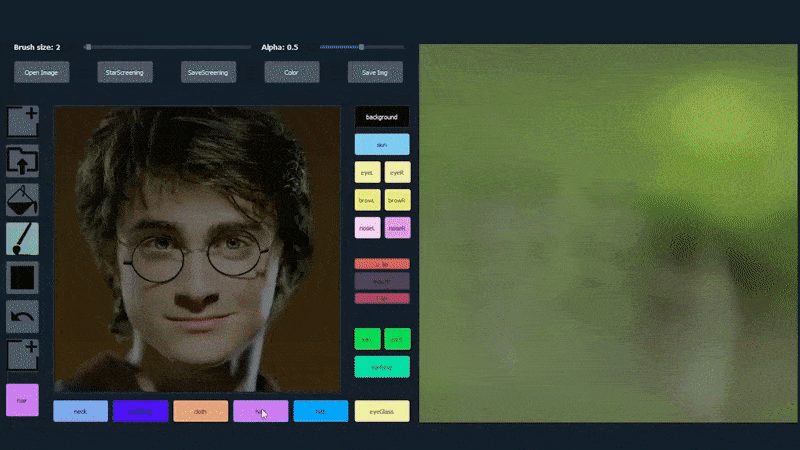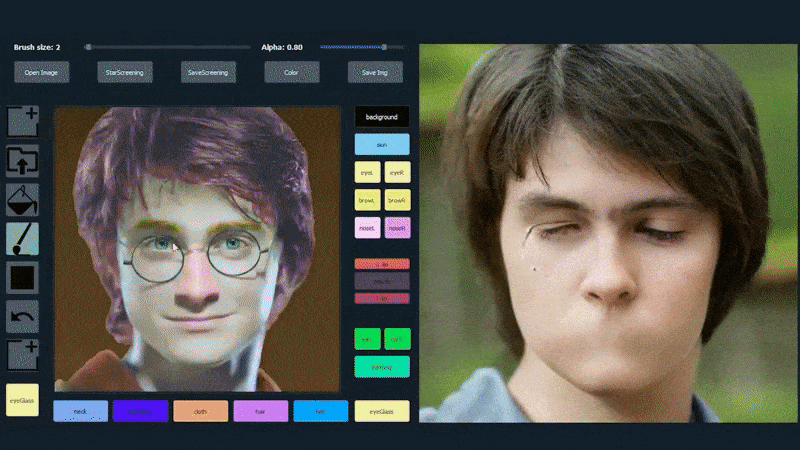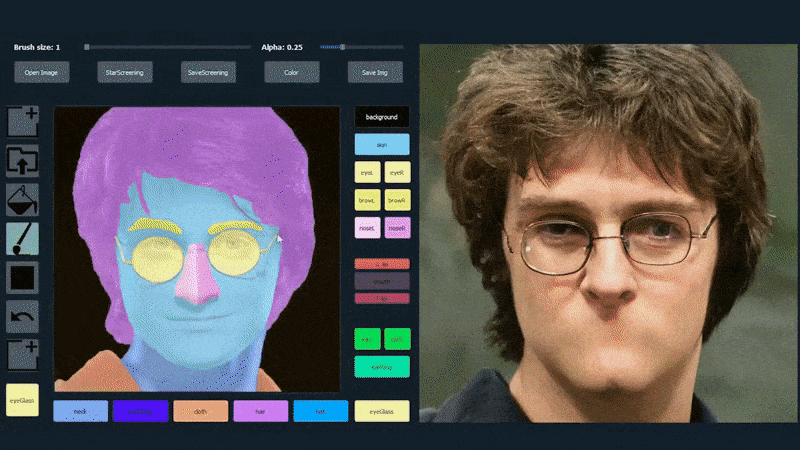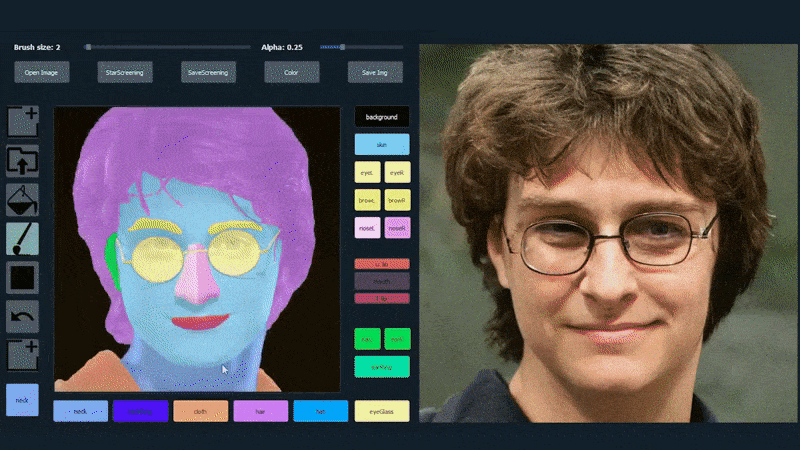
استخدام صورة واحدة كمواد تتبع ل بورتريه تم إنشاؤه بواسطة SofGAN مصدر: https://www.youtube.com/watch?v=xig8ZA3DVZ8
المقالة المقالة بعنوان SofGAN: نظام توليد صور بورتريه مع أسلوب ديناميكي، ويقودها Anpei Chen و Ruiyang Liu، إلى جانب باحثين آخرين من جامعة ShanghaiTech وواحد من جامعة كاليفورنيا في سان دييغو.
فك الخصائص
المساهمة الرئيسية للعمل ليست في توفير واجهة مستخدم友ية، ولكن في “فك” الخصائص مثل وضع و قوام الوجه، مما يسمح ل SofGAN أيضًا بإنشاء وجوه في زوايا غير مباشرة للكاميرا.

غير عادي بين مولدات الوجه القائمة على Generative Adversarial Networks، SofGAN يمكن تغيير زاوية المشاهدة حسب الرغبة، في حدود مصفوفة الزوايا الموجودة في بيانات التدريب. مصدر: https://arxiv.org/pdf/2007.03780.pdf
منذ أن تم فك القوام من الهندسة، يمكن أيضًا تحرير شكل الوجه والقوام ككيانات منفصلة. في الواقع، هذا يسمح بتغيير العرق لوجه مصدر، ممارسة فاضحة لها تطبيق مفيد محتمل، لإنشاء مجموعات بيانات متوازنة للتعلم الآلي.

SofGAN يدعم أيضًا الشيخوخة الاصطناعية وتعديل الأسلوب المتسق مع السمات على مستوى غير مرئي في أنظمة التجزئة المماثلة مثل NVIDIA’s GauGAN و Intel’s نظام العرض العصبي.

SofGAN يمكن تنفيذ الشيخوخة كأسلوب متكرر.
إنجاز آخر لمنهجية SofGAN هو أن التدريب لا يتطلب صورًا متطابقة للتجزئة / الواقع، ولكن يمكن تدريبه مباشرة على صور العالم الحقيقي غير المطابقة.
يقول الباحثون أن هيكل “فك” SofGAN استوحى من أنظمة العرض التقليدية للصور، والتي تفكك العناصر الفردية للصورة. في تدفقات التأثيرات البصرية، يتم كسر عناصر التأليف إلى المكونات الأكثر دقة، مع اختصاصيين مخصصين لكل مكون.
حقل التجزئة الدلالية (SOF)
لتحقيق ذلك في إطار 합成 الصور القائم على التعلم الآلي، قام الباحثون بتطوير حقل التجزئة الدلالية (SOF)، وهو امتداد لحقل التواجد التقليدي الذي يفرق بين عناصر بورتريه الوجه. تم تدريب SOF على خرائط التجزئة الدلالية متعددة الآراء المحددة، دون أي إشراف حقيقي.

iterations متعددة من خريطة تجزئة واحدة (الأسفل اليسار).
بالإضافة إلى ذلك، يتم الحصول على خرائط التجزئة ثنائية الأبعاد عن طريق تتبع الإخراج من SOF، قبل أن يتم توجيهها بواسطة مولد GAN. يتم أيضًا ترميز الخرائط التجزئة الاصطناعية في مساحة منخفضة الأبعاد عبر ثلاثة طبقات من التشفير لضمان استمرارية الإخراج عند تغيير نقطة المشاهدة.
خطة التدريب تخلط مكانيًا بين نمطين عشوائيين لكل منطقة دلالية:

هيكل SofGAN.
يقول الباحثون أن SofGAN يحقق مسافة فريتش إنسيشن أقل (FID) من الطرق الحالية البديلة، بالإضافة إلى معامل تشابه الصورة المكتسبة (LPIPS) أعلى.
النهج السابقة ل StyleGAN كانت عادةً محظورة بسبب تشابك الخصائص، حيث يتم ربط العناصر التي تتكون منها الصورة ببعضها البعض بطريقة لا يمكن فكها، مما يؤدي إلى ظهور عناصر غير مرغوب فيها جنبًا إلى جنب مع عنصر مرغوب فيه (على سبيل المثال، قد تظهر الأقراط عند تحرير شكل الأذن الذي تم إعلامه في وقت التدريب بصور تحتوي على أقراط).

تتبع الأشعة يُستخدم لحساب حجم خرائط التجزئة الدلالية، مما يتيح عدة وجهات نظر.
مجموعات البيانات والتدريب
تم استخدام ثلاث مجموعات بيانات في تطوير تنفيذات مختلفة من SofGAN: CelebAMask-HQ، وهو مستودع يحتوي على 30,000 صورة بدقة عالية من مجموعة بيانات CelebA-HQ؛ NVIDIA’s Flickr-Faces-HQ (FFHQ)، الذي يحتوي على 70,000 صورة، حيث قام الباحثون بتسمية الصور بمتحليل وجه مُدرب مسبقًا؛ ومجموعة من 122 مسح بورتريه تم إنتاجها ذاتيًا مع مناطق دلالية تم تحديدها يدوياً.
يتكون SOF من ثلاث وحدات قابلة للتدريب – الشبكة العليا، تتبع الأشعة (انظر الصورة أعلاه)، والمنظم. يتم تكوين مولد StyleGAN للمشروع بشكل مشابه ل StyleGAN2 في بعض الجوانب. يتم تطبيق تعزيز البيانات من خلال التكبير والقص بشكل عشوائي، ويتضمن التدريب تنظيم المسار كل أربعة خطوات. استغرق إجراء التدريب 22 يومًا للوصول إلى 800,000 تكرار على أربعة RTX 2080 Ti GPUs عبر CUDA 10.1.
لا يذكر المقال تكوين بطاقات 2080، والتي يمكن أن تستوعب بين 11GB-22GB من ذاكرة الوصول العشوائي لكل بطاقة، مما يعني أن إجمالي ذاكرة الوصول العشوائي المستخدمة لأفضل جزء من شهر للتدريب على SofGAN يتراوح بين 44GB و 88GB.
يلاحظ الباحثون أن النتائج العامة المقبولة بدأت تظهر في وقت مبكر من التدريب، عند 1500 تكرار، ثلاثة أيام من التدريب. تم استغلال بقية التدريب في السير البطيء نحو الحصول على التفاصيل الدقيقة مثل ملامح الشعر والعين.
يحقق SofGAN بشكل عام نتائج أكثر واقعية من خريطة تجزئة واحدة مقارنة بالطرق المنافسة مثل NVIDIA’s SPADE و Pix2PixHD، و SEAN.

فيما يلي الفيديو الذي أصدره الباحثون. يمكن الوصول إلى مقاطع فيديو ذاتية الاستضافة إضافية على صفحة المشروع.













{kind=link}