الذكاء الاصطناعي
كيف يمكن أن يتطور الانتشار المستقر كمنتج استهلاكي رئيسي

بسخرية، انتشار مستقرإن إطار عمل تركيب الصور بالذكاء الاصطناعي الجديد الذي اجتاح العالم ليس مستقرًا ولا "منتشرًا" حقًا - على الأقل ليس بعد.
تنتشر المجموعة الكاملة من قدرات النظام عبر مجموعة متنوعة من العروض المتغيرة باستمرار من مجموعة قليلة من المطورين الذين يتبادلون بشكل محموم أحدث المعلومات والنظريات في ندوات متنوعة على Discord - والغالبية العظمى من إجراءات التثبيت للحزم التي يقومون بإنشائها أو تعديلها بعيدة كل البعد عن "التوصيل والتشغيل".
بدلاً من ذلك ، فإنها تميل إلى طلب سطر أوامر أو يحركها BAT التثبيت عبر GIT و Conda و Python و Miniconda وأطر تطوير متطورة أخرى - حزم البرامج نادرة جدًا بين التشغيل العام للمستهلكين لدرجة أن التثبيت الخاص بهم كثيرًا ما يتم وضع علامة عليها بواسطة بائعي برامج مكافحة الفيروسات والبرامج الضارة كدليل على نظام مضيف مخترق.

لا توجد سوى مجموعة محدودة من المراحل في عملية التثبيت القياسية لتوزيعة Stable Diffusion حاليًا. تتطلب العديد من التوزيعات أيضًا إصدارات محددة من Python، والتي قد تتعارض مع الإصدارات الحالية المثبتة على جهاز المستخدم - مع أنه يمكن تجنب ذلك من خلال عمليات التثبيت القائمة على Docker، وإلى حد ما، من خلال استخدام بيئات Conda.
تمتلئ سلاسل الرسائل في كل من مجتمعات SFW و NSFW Stable Diffusion بالنصائح والحيل المتعلقة باختراق نصوص Python النصية والتثبيتات القياسية ، من أجل تمكين الوظائف المحسنة ، أو لحل أخطاء التبعية المتكررة ، ومجموعة من المشكلات الأخرى.
هذا يترك المستهلك العادي مهتمًا بـ خلق صور مذهلة من المطالبات النصية ، إلى حد كبير تحت رحمة العدد المتزايد من واجهات الويب API التي يتم تحقيق الدخل منها ، والتي يقدم معظمها عددًا قليلاً من أجيال الصور المجانية قبل طلب شراء الرموز المميزة.
بالإضافة إلى ذلك، ترفض جميع هذه العروض المستندة إلى الويب تقريبًا إخراج محتوى NSFW (قد يتعلق الكثير منه بموضوعات غير إباحية تهم المصلحة العامة، مثل "الحرب") والذي يميز Stable Diffusion عن الخدمات المعدلة من DALL-E 2 من OpenAI.
"فوتوشوب للانتشار المستقر"
إن ما ينتظره العالم الأوسع هو الصور الرائعة أو الجريئة أو غير الدنيوية التي تملأ وسم #stablediffusion على تويتر يوميًا. "فوتوشوب للانتشار المستقر" - تطبيق قابل للتثبيت عبر الأنظمة الأساسية يجمع بين أفضل وأقوى وظائف بنية Stability.ai، بالإضافة إلى الابتكارات المبتكرة المختلفة لمجتمع تطوير SD الناشئ، دون أي نوافذ CLI عائمة، أو إجراءات تثبيت وتحديث غامضة ومتغيرة باستمرار، أو ميزات مفقودة.
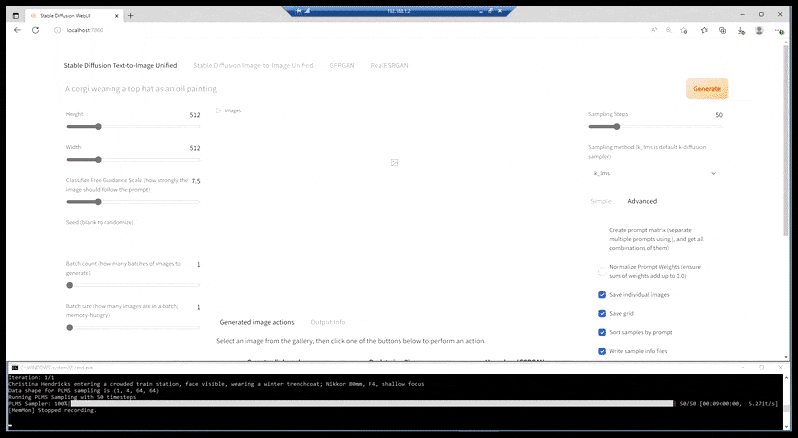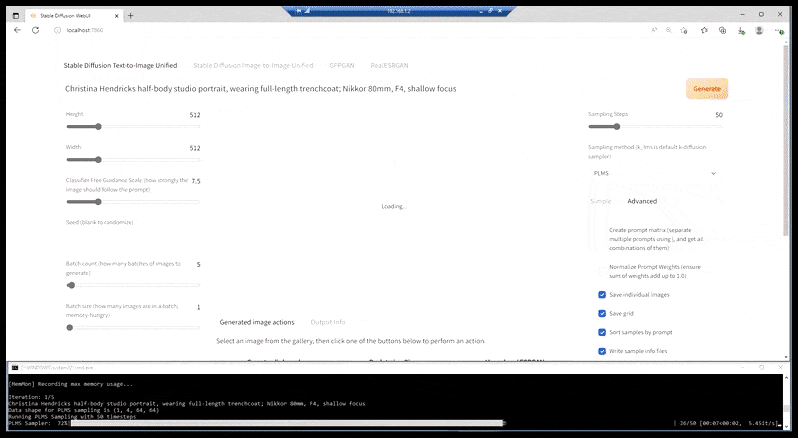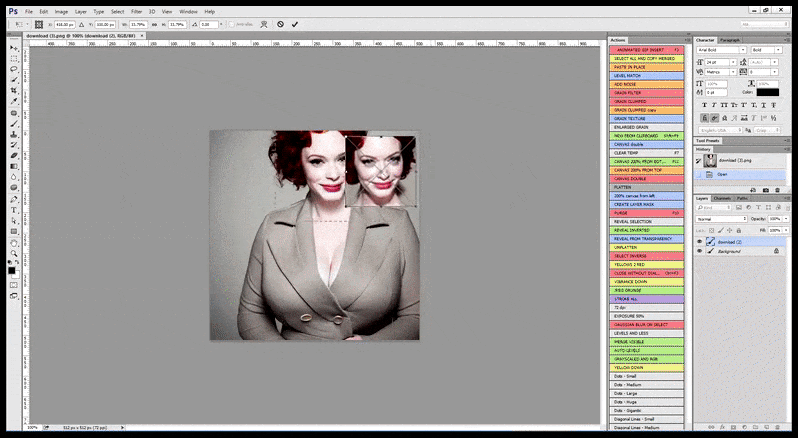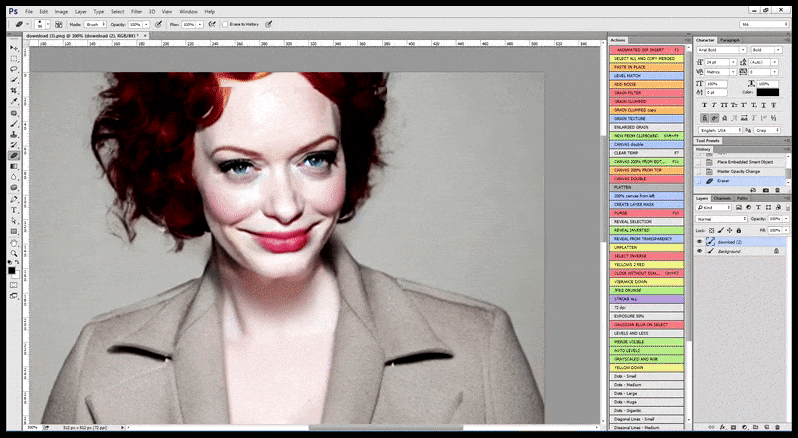
ما لدينا حاليًا ، في معظم التركيبات الأكثر قدرة ، هو صفحة ويب متنوعة أنيقة تتخللها نافذة سطر أوامر غير مجسدة ، وعنوان URL الخاص بها هو منفذ مضيف محلي:

على غرار تطبيقات التوليف التي تعتمد على CLI مثل FaceSwap، و DeepFaceLab المرتكز على BAT، يُظهر تثبيت "prepack" لـ Stable Diffusion جذور سطر الأوامر، مع إمكانية الوصول إلى الواجهة عبر منفذ localhost (انظر أعلى الصورة أعلاه) والذي يتواصل مع وظيفة Stable Diffusion المستندة إلى CLI.
لا شك أن هناك تطبيقًا أكثر بساطة قادمًا. يوجد بالفعل العديد من التطبيقات المتكاملة المستندة إلى Patreon والتي يمكن تنزيلها ، مثل غريسك و نمكد (انظر الصورة أدناه) - ولكن لا شيء حتى الآن يدمج النطاق الكامل من الميزات التي يمكن أن تقدمها بعض التطبيقات الأكثر تقدمًا والتي يصعب الوصول إليها من Stable Diffusion.

حزم Stable Diffusion المبكرة، المستندة على Patreon، والمُدمجة بشكل طفيف مع التطبيقات. NMKD هي أول حزمة تُدمج مخرجات واجهة سطر الأوامر مباشرةً في واجهة المستخدم الرسومية.
دعونا نلقي نظرة على الشكل الذي قد يبدو عليه في نهاية المطاف تنفيذ أكثر دقة وتكاملاً لهذه الأعجوبة المفتوحة المصدر المذهلة - وما هي التحديات التي قد تواجهها.
الاعتبارات القانونية لتطبيق نشر مستقر تجاري ممول بالكامل
عامل NSFW
تم إصدار الكود المصدري للانتشار المستقر تحت ملف رخصة متساهلة للغاية التي لا تحظر عمليات إعادة التنفيذ التجارية والأعمال المشتقة التي يتم إنشاؤها على نطاق واسع من الكود المصدري.
إلى جانب العدد المذكور أعلاه والمتزايد من إنشاءات Stable Diffusion المستندة إلى Patreon ، بالإضافة إلى العدد الكبير من المكونات الإضافية للتطبيق التي يتم تطويرها من أجل FIGMA, كريتا, فوتوشوب, GIMPو خلاط (من بين أمور أخرى) ، لا يوجد عملي سبب عدم تمكن دار تطوير برمجيات ممولة تمويلًا جيدًا من تطوير تطبيق Stable Diffusion أكثر تطوراً وقدرة. من منظور السوق ، هناك كل الأسباب للاعتقاد بأن العديد من هذه المبادرات جارية بالفعل.
هنا، تواجه مثل هذه الجهود على الفور معضلة حول ما إذا كان التطبيق، مثل غالبية واجهات برمجة تطبيقات الويب لـ Stable Diffusion، سيسمح بمرشح NSFW الأصلي لـ Stable Diffusion (أ) أم لا. جزء من الكود) ، ليتم إيقاف تشغيله.
'دفن' مفتاح NSFW
على الرغم من أن ترخيص المصدر المفتوح لـ Stability.ai لـ Stable Diffusion يتضمن قائمة قابلة للتفسير على نطاق واسع من التطبيقات التي قد لست يمكن استخدامها (يمكن القول بما في ذلك محتوى إباحي و deepfakes) ، الطريقة الوحيدة التي يمكن للبائع من خلالها حظر مثل هذا الاستخدام بشكل فعال هي تجميع مرشح NSFW في ملف قابل للتنفيذ معتم بدلاً من معلمة في ملف Python ، أو فرض مقارنة المجموع الاختباري على ملف Python أو DLL الذي يحتوي على توجيه NSFW ، بحيث لا يمكن أن يحدث العرض إذا قام المستخدمون بتغيير هذا الإعداد.
سيؤدي هذا إلى ترك التطبيق المفترض "محايدًا" بنفس الطريقة التي DALL-E 2 حاليًامما يُضعف جاذبيتها التجارية. كما أنه من المحتمل، لا محالة، أن تظهر في مجتمع التورنت/القرصنة نسخ مُفككة "مُعدّلة" من هذه المكونات (سواءً عناصر تشغيل بايثون الأصلية أو ملفات DLL مُجمّعة، كما هو مُستخدم الآن في سلسلة أدوات تحسين صور الذكاء الاصطناعي Topaz) لفك هذه القيود، ببساطة عن طريق استبدال العناصر المُعيقة، وإلغاء أي متطلبات لمجموع الاختبار.
في النهاية، قد يختار البائع ببساطة تكرار تحذير Stability.ai ضد سوء الاستخدام الذي يميز التشغيل الأول للعديد من توزيعات Stable Diffusion الحالية.
ومع ذلك ، فإن مطوري البرامج مفتوحة المصدر الصغيرة الذين يستخدمون حاليًا إخلاء المسئولية غير الرسمي بهذه الطريقة ليس لديهم الكثير ليخسروه مقارنة بشركة برمجيات استثمرت قدرًا كبيرًا من الوقت والمال في جعل Stable Diffusion كامل الميزات ويمكن الوصول إليه - الأمر الذي يدعو إلى دراسة أعمق.
مسؤولية التزييف العميق
كما لدينا وأشار مؤخراتحتوي قاعدة بيانات LAION-aesthetics، وهي جزء من 4.2 مليار صورة تم تدريب نماذج Stable Diffusion المستمرة عليها، على عدد كبير من صور المشاهير، مما يتيح للمستخدمين إنشاء صور مزيفة عميقة بشكل فعال، بما في ذلك صور إباحية مزيفة للمشاهير.

من مقالنا الأخير ، أربع مراحل من جينيفر كونيلي على مدى أربعة عقود من حياتها المهنية ، مستدل عليها من Stable Diffusion.
وهذه قضية منفصلة وأكثر إثارة للجدل من قضية إنتاج المواد الإباحية "المجردة" القانونية (عادةً)، والتي لا تصور أشخاصًا "حقيقيين" (على الرغم من استنتاج مثل هذه الصور من صور حقيقية متعددة في مواد التدريب).
وبما أن عددًا متزايدًا من الولايات والبلدان الأمريكية تعمل على تطوير أو سن قوانين ضد المواد الإباحية المزيفة، فإن قدرة Stable Diffusion على إنشاء مواد إباحية للمشاهير قد تعني أن التطبيق التجاري الذي لا يخضع للرقابة الكاملة (أي الذي يمكنه إنشاء مواد إباحية) قد لا يزال بحاجة إلى بعض القدرة على تصفية وجوه المشاهير المتصورة.
إحدى الطرق تتمثل في توفير "قائمة سوداء" مدمجة بالمصطلحات التي لن تُقبل في طلبات المستخدم، والمتعلقة بأسماء المشاهير والشخصيات الخيالية التي قد ترتبط بهم. يُفترض أن هذه الإعدادات يجب أن تُطبّق بلغات أخرى غير الإنجليزية، لأن البيانات الأصلية تتضمن لغات أخرى. ومن الطرق الأخرى دمج أنظمة التعرف على المشاهير، مثل تلك التي طورتها شركة Clarifai.
قد يكون من الضروري لمنتجي البرامج دمج مثل هذه الأساليب ، ربما تم إيقاف تشغيلها في البداية ، حيث قد يساعد ذلك في منع تطبيق Stable Diffusion قائم بذاته ومستقل من توليد وجوه المشاهير ، في انتظار تشريعات جديدة قد تجعل هذه الوظيفة غير قانونية.
مرة أخرى ، ومع ذلك ، يمكن حتما حل هذه الوظيفة وعكسها من قبل الأطراف المهتمة ؛ ومع ذلك ، يمكن لمنتج البرمجيات ، في هذا الاحتمال ، أن يدعي أن هذا هو تخريب غير مصرح به فعليًا - طالما أن هذا النوع من الهندسة العكسية لم يتم تسهيله بشكل مفرط.
الميزات التي يمكن تضمينها
من المتوقع أن تكون الوظيفة الأساسية في أي توزيع للانتشار المستقر من أي تطبيق تجاري جيد التمويل. يتضمن ذلك القدرة على استخدام المطالبات النصية لإنشاء صور مناسبة (نص إلى صورة) ؛ القدرة على استخدام الرسومات أو الصور الأخرى كإرشادات للصور التي تم إنشاؤها حديثًا (من صورة إلى صورة); الوسائل لضبط مدى "الخيال" الذي يُطلب من النظام أن يكون عليه؛ وطريقة لموازنة وقت العرض مع الجودة؛ و"الأساسيات" الأخرى، مثل الأرشفة التلقائية الاختيارية للصور/المطالبات، والترقية الاختيارية الروتينية عبر ريالESRGAN، وعلى الأقل "إصلاح الوجه" الأساسي مع جفبجان or كودفورمر.
هذا تثبيت عادي جدًا. لنلقِ نظرة على بعض الميزات المتقدمة التي يجري تطويرها أو توسيعها حاليًا، والتي يمكن دمجها في تطبيق Stable Diffusion "التقليدي" الكامل.
التجميد العشوائي
حتى لو كنت إعادة استخدام بذرة من تصيير سابق ناجح ، من الصعب للغاية الحصول على Stable Diffusion لتكرار التحول بدقة إذا أي جزء من الموجه أو صورة المصدر (أو كليهما) للعرض اللاحق.
هذه مشكلة إذا كنت تريد استخدام إبسينث لفرض تحويلات الانتشار المستقر على الفيديو الحقيقي بطريقة متماسكة زمنياً - على الرغم من أن هذه التقنية يمكن أن تكون فعالة للغاية في لقطات الرأس والكتفين البسيطة:

يمكن للحركة المحدودة أن تجعل من EbSynth وسيطًا فعالاً لتحويل تحولات الانتشار المستقر إلى فيديو واقعي. المصدر: https://streamable.com/u0pgzd
تعمل EbSynth عن طريق استقراء مجموعة صغيرة من الإطارات الرئيسية "المعدلة" في مقطع فيديو تم تقديمه في سلسلة من ملفات الصور (والتي يمكن إعادة تجميعها لاحقًا في مقطع فيديو).

في هذا المثال من موقع EbSynth ، تم رسم مجموعة صغيرة من الإطارات من مقطع فيديو بطريقة فنية. يستخدم EbSynth هذه الإطارات كدليل نمط لتغيير الفيديو بأكمله بشكل مشابه بحيث يتطابق مع النمط المطلي. المصدر: https://www.youtube.com/embed/eghGQtQhY38
في المثال أدناه، والذي لا يتضمن أي حركة تقريبًا من مدرب اليوجا الأشقر (الحقيقي) على اليسار، لا يزال Stable Diffusion يواجه صعوبة في الحفاظ على وجه متناسق، لأن الصور الثلاث التي يتم تحويلها إلى "إطارات رئيسية" ليست متطابقة تمامًا، على الرغم من أنها جميعًا تشترك في نفس البذرة الرقمية.

هنا ، حتى مع نفس الموجه والبذرة عبر جميع التحولات الثلاثة ، وتغييرات قليلة جدًا بين الإطارات المصدر ، تختلف عضلات الجسم في الحجم والشكل ، ولكن الأهم من ذلك أن الوجه غير متناسق ، مما يعيق الاتساق الزمني في عرض EbSynth المحتمل.
على الرغم من أن مقطع الفيديو SD/EbSynth أدناه مبتكر للغاية، حيث تم تحويل أصابع المستخدم إلى (على التوالي) زوج من الأرجل التي ترتدي بنطالًا وبطة، فإن عدم تناسق البنطال يجسد المشكلة التي تواجهها تقنية Stable Diffusion في الحفاظ على التناسق عبر الإطارات الرئيسية المختلفة، حتى عندما تكون إطارات المصدر متشابهة مع بعضها البعض والبذرة متسقة.

تصبح أصابع الرجل رجلاً يمشي وبطة، من خلال Stable Diffusion وEbSynth. المصدر: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
المستخدم الذي أنشأ هذا الفيديو علق أن تحويل البطة ، الذي يمكن القول أنه الأكثر فعالية من الاثنين ، إذا كان أقل لفتًا للانتباه والأصالة ، يتطلب فقط إطارًا رئيسيًا محوّلًا واحدًا ، في حين كان من الضروري تقديم 50 صورة انتشار مستقر من أجل إنشاء سراويل المشي ، والتي تظهر بشكل زمني أكثر تناقض. لاحظ المستخدم أيضًا أن الأمر استغرق خمس محاولات لتحقيق الاتساق لكل من الإطارات الرئيسية الخمسين.
لذلك سيكون من المفيد جدًا تطبيق Stable Diffusion الشامل حقًا توفير وظائف تحافظ على الخصائص إلى أقصى حد عبر الإطارات الرئيسية.
أحد الاحتمالات هو أن يسمح التطبيق للمستخدم بتجميد الترميز العشوائي للتحويل في كل إطار، وهو ما لا يمكن تحقيقه حاليًا إلا بتعديل الكود المصدري يدويًا. وكما يوضح المثال أدناه، يُساعد هذا على تحقيق الاتساق الزمني، ولكنه لا يحل المشكلة بالتأكيد.

قام أحد مستخدمي Reddit بتحويل لقطات كاميرا الويب الخاصة به إلى أشخاص مشهورين مختلفين ليس فقط من خلال الاستمرار في البذرة (وهو ما يمكن أن يفعله أي تنفيذ لـ Stable Diffusion) ، ولكن من خلال التأكد من أن معلمة stochastic_encode () كانت متطابقة في كل تحويل. تم تحقيق ذلك عن طريق تعديل الرمز ، ولكن يمكن أن يصبح بسهولة مفتاحًا يمكن للمستخدم الوصول إليه. من الواضح ، مع ذلك ، أنه لا يحل جميع القضايا الزمنية. المصدر: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
انعكاس نصي قائم على السحابة
الحل الأفضل لاستحضار شخصيات وأشياء متسقة زمنيًا هو "خبزها" في انعكاس نصي - ملف بحجم 5 كيلوبايت يمكن تدريبه في غضون ساعات قليلة بناءً على خمس صور مشروحة فقط ، والتي يمكن بعد ذلك استنباطها بواسطة شخص خاص '*' سريع ، يمكّن ، على سبيل المثال ، من الظهور المستمر لشخصيات جديدة لإدراجها في سرد ما.

يمكن تحويل الصور المرتبطة بالعلامات المناسبة إلى كيانات منفصلة عبر Textual Inversion ، واستدعاءها دون غموض ، وفي السياق والأسلوب الصحيحين ، بواسطة كلمات رمزية خاصة. المصدر: https://huggingface.co/docs/diffusers/training/text_inversion
إن الانعكاسات النصية هي ملفات إضافية للنموذج الكبير جدًا والمدرب بالكامل الذي يستخدمه Stable Diffusion، ويتم "دمجها" بشكل فعال في عملية الاستنباط/التحفيز، بحيث يمكنها شارك في المشاهد المستمدة من النموذج، والاستفادة من قاعدة البيانات الضخمة للنموذج من المعرفة حول الكائنات والأساليب والبيئات والتفاعلات.
ومع ذلك ، على الرغم من أن الانعكاس النصي لا يستغرق وقتًا طويلاً للتدريب ، إلا أنه يتطلب قدرًا كبيرًا من VRAM ؛ وفقًا للإرشادات الحالية المختلفة ، في مكان ما بين 12 و 20 وحتى 40 جيجابايت.
نظرًا لأنه من غير المرجح أن يكون لدى معظم المستخدمين العاديين هذا النوع من ثقل GPU تحت تصرفهم ، فإن الخدمات السحابية تظهر بالفعل والتي ستتعامل مع العملية ، بما في ذلك إصدار Hugging Face. رغم أن هناك تطبيقات جوجل كولاب التي يمكن أن تخلق انعكاسات نصية للانتشار المستقر ، فإن متطلبات VRAM والوقت المطلوبة قد تجعل هذه التحديات صعبة لمستخدمي Colab ذوي المستوى المجاني.
بالنسبة لتطبيق Stable Diffusion (المثبت) المحتمل الكامل والمستثمر جيدًا، يبدو أن تمرير هذه المهمة الثقيلة إلى خوادم السحابة الخاصة بالشركة هو استراتيجية واضحة لتحقيق الربح (على افتراض أن تطبيق Stable Diffusion منخفض التكلفة أو بدون تكلفة يتخلله مثل هذه الوظائف غير المجانية، وهو ما يبدو محتملاً في العديد من التطبيقات المحتملة التي ستظهر من هذه التكنولوجيا في الأشهر الستة إلى التسعة المقبلة).
بالإضافة إلى ذلك، يمكن الاستفادة من الأتمتة في بيئة متكاملة، وهي عملية معقدة نوعًا ما، تتمثل في إضافة التعليقات التوضيحية وتنسيق الصور والنصوص المُرسلة. ويبدو أن عامل الإدمان المحتمل المتمثل في إنشاء عناصر فريدة قادرة على استكشاف عوالم "الانتشار المستقر" الشاسعة والتفاعل معها، قد يكون إدمانًا، سواءً لعشاق هذا المجال أو للمستخدمين الأصغر سنًا.
ترجيح سريع متعدد الاستخدامات
هناك العديد من التطبيقات الحالية التي تسمح للمستخدم بتعيين تركيز أكبر على قسم من موجه نص طويل ، ولكن الأداة تختلف كثيرًا بين هذه ، وغالبًا ما تكون ثقيلة أو غير بديهية.
شوكة الانتشار المستقر المشهورة جدًا بواسطة AUTOMATIC1111، على سبيل المثال ، يمكن خفض قيمة كلمة سريعة أو رفعها عن طريق وضعها بين قوسين مفرد أو عدة أقواس (لإلغاء التركيز) أو أقواس مربعة لمزيد من التأكيد.

يمكن للأقواس المربعة و/أو الأقواس أن تحول وجبة الإفطار الخاصة بك في هذا الإصدار من أوزان موجهة الانتشار المستقر، ولكنها كابوس الكوليسترول في كلتا الحالتين.
تستخدم التكرارات الأخرى لـ Stable Diffusion علامات التعجب للتأكيد ، في حين أن الأكثر تنوعًا يسمح للمستخدمين بتعيين أوزان لكل كلمة في الموجه من خلال واجهة المستخدم الرسومية.
يجب أن يسمح النظام أيضًا بـ أوزان موجزة سلبية - ليس فقط من أجل عشاق الرعبولكن لأن هناك أسرارًا أقل إثارة للقلق وأكثر إفادة في الفضاء الكامن للانتشار المستقر مما يمكن أن يستحضره استخدامنا المحدود للغة.
الزائدة
بعد وقت قصير من فتح المصدر المثير للانتشار المستقر ، حاولت شركة OpenAI - عبثًا إلى حد كبير - استعادة بعض من رعد DALL-E 2 من خلال أعلن "التوسع في الرسم"، والذي يسمح للمستخدم بتوسيع الصورة إلى ما هو أبعد من حدودها باستخدام المنطق الدلالي والترابط البصري.
وبطبيعة الحال ، كان هذا منذ ذلك الحين نفذت في أشكال مختلفة للانتشار المستقر ، وكذلك في كريتا، ويجب بالتأكيد تضمينه في إصدار شامل بنمط Photoshop من Stable Diffusion.
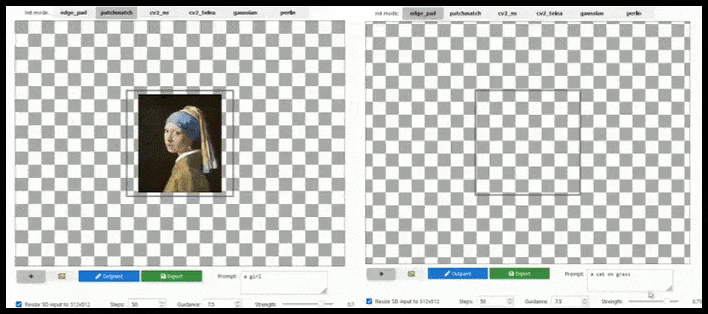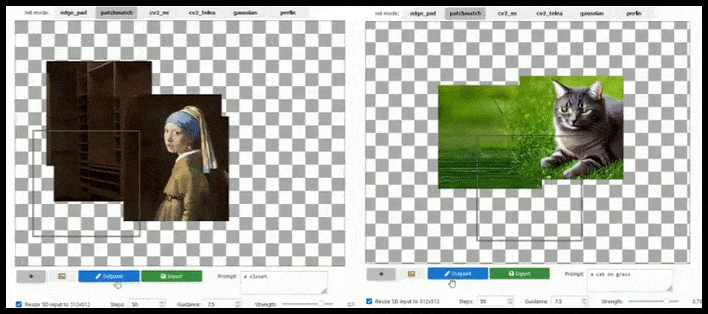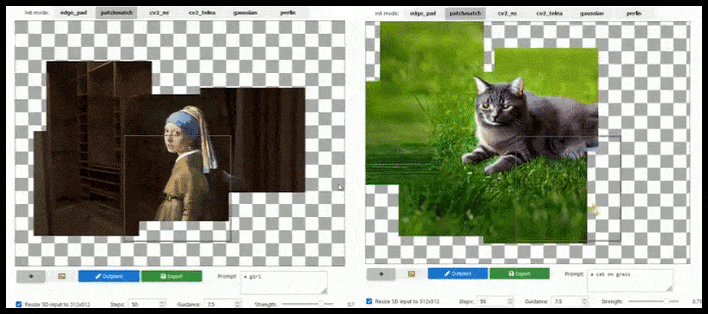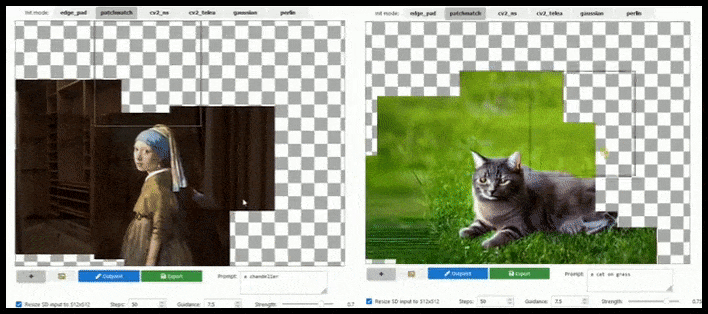
يمكن أن تؤدي الزيادة القائمة على التجانب إلى تمديد عرض قياسي 512 × 512 إلى ما لا نهاية تقريبًا ، طالما أن المطالبات والصورة الحالية والمنطق الدلالي تسمح بذلك. المصدر: https://github.com/lkwq007/stablediffusion-infinity
نظرًا لأن Stable Diffusion مدرب على صور بحجم 512 × 512 بكسل (ولعدة أسباب أخرى)، فإنه غالبًا ما يقطع الرؤوس (أو أجزاء الجسم الأساسية الأخرى) عن الكائنات البشرية، حتى عندما يشير المطالبة بوضوح إلى "التركيز على الرأس"، وما إلى ذلك.

أمثلة نموذجية على "قطع الرأس" الناتج عن الانتشار المستقر؛ ولكن الطلاء الزائد قد يعيد جورج إلى الصورة.
يجب أيضًا استخدام أي تطبيق خارجي من النوع الموضح في الصورة المتحركة أعلاه (والذي يعتمد حصريًا على مكتبات Unix ، ولكن يجب أن يكون قابلاً للنسخ المتماثل على Windows) كعلاج بنقرة واحدة / سريع لذلك.
في الوقت الحالي، يقوم عدد من المستخدمين بتوسيع لوحة التصوير "المقطوع الرأس" إلى الأعلى، وملء منطقة الرأس تقريبًا، واستخدام img2img لإكمال العرض الفاشل.
إخفاء فعال يفهم السياق
اخفاء قد يكون الأمر متذبذبًا للغاية في Stable Diffusion، وذلك حسب النسخة أو الشق المعني. في كثير من الأحيان، عند إمكانية رسم قناع متماسك، ينتهي الأمر برسم المنطقة المحددة بمحتوى لا يأخذ سياق الصورة بالكامل في الاعتبار.
في إحدى المرات ، قمت بإخفاء قرنيات صورة للوجه ، وأعطيت الأمر 'عيون زرقاء' كقناع مُلوَّن - لأجد أنني كنتُ أنظر من خلال عينين بشريتين مقطوعتين إلى صورة بعيدة لذئب ذي مظهرٍ غريب. أعتقد أنني محظوظٌ أنه لم يكن فرانك سيناترا.
التحرير الدلالي ممكن أيضا عن طريق تحديد الضوضاء الذي أنشأ الصورة في المقام الأول ، مما يسمح للمستخدم بمعالجة عناصر هيكلية محددة في العرض دون التداخل مع بقية الصورة:

تغيير عنصر واحد في صورة بدون إخفاء تقليدي وبدون تغيير المحتوى المجاور ، من خلال تحديد الضوضاء التي نشأت الصورة أولاً ومعالجة الأجزاء التي ساهمت في المنطقة المستهدفة. المصدر: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
تعتمد هذه الطريقة على جهاز أخذ العينات K-Diffusion.
المرشحات الدلالية للأحمق الفسيولوجية
كما ذكرنا من قبل، يمكن لـ Stable Diffusion أن يضيف أو يطرح أطرافًا بشكل متكرر، ويرجع ذلك إلى حد كبير إلى مشكلات البيانات والنواقص في التعليقات التوضيحية التي تصاحب الصور التي درّبتها.

تمامًا مثل ذلك الطفل الضال الذي أخرج لسانه في صورة جماعية بالمدرسة، فإن الفظائع البيولوجية التي تسببها تقنية Stable Diffusion ليست واضحة دائمًا على الفور، وربما تكون قد نشرت أحدث تحفة فنية في مجال الذكاء الاصطناعي على موقع إنستغرام قبل أن تلاحظ الأيدي الإضافية أو الأطراف المذابة.
من الصعب جدًا إصلاح هذه الأنواع من الأخطاء بحيث يكون من المفيد إذا احتوى تطبيق Stable Diffusion كامل الحجم على نوع من نظام التعرف التشريحي الذي استخدم التجزئة الدلالية لحساب ما إذا كانت الصورة الواردة تحتوي على عيوب تشريحية شديدة (كما في الصورة أعلاه ) ، ويتجاهلها لصالح تصيير جديد قبل تقديمه للمستخدم.

بالطبع ، قد ترغب في تقديم الإلهة كالي ، أو دكتور الأخطبوط ، أو حتى إنقاذ جزء غير متأثر من الصورة المصابة بأطراف ، لذلك يجب أن تكون هذه الميزة تبديلًا اختياريًا.
إذا كان بإمكان المستخدمين تحمل جانب القياس عن بُعد ، فيمكن حتى نقل هذه الأخطاء بشكل مجهول في جهد جماعي للتعلم الاتحادي الذي قد يساعد النماذج المستقبلية على تحسين فهمهم للمنطق التشريحي.
تحسين الوجه التلقائي القائم على LAION
كما أشرت في بلدي النظرة السابقة في حين أن هناك ثلاثة أشياء يمكن لـ Stable Diffusion معالجتها في المستقبل، فلا ينبغي أن يُترك الأمر لأي إصدار من GFPGAN لمحاولة "تحسين" الوجوه المقدمة في عمليات العرض الأولية.
إن "تحسينات" GFPGAN عامة للغاية، وتعمل في كثير من الأحيان على تقويض هوية الفرد المصور، وتعمل فقط على وجه تم تقديمه بشكل سيئ عادةً، حيث لم يتلق أي وقت معالجة أو اهتمام أكثر من أي جزء آخر من الصورة.
لذلك، يجب أن يكون برنامج Stable Diffusion، المتوافق مع المعايير الاحترافية، قادرًا على التعرف على الوجه (باستخدام مكتبة قياسية وخفيفة الوزن نسبيًا مثل YOLO)، واستخدام كامل طاقة وحدة معالجة الرسومات المتاحة لإعادة عرضه، ثم دمج الوجه المُحسّن في العرض الأصلي ذي السياق الكامل، أو حفظه منفصلًا لإعادة تركيبه يدويًا. حاليًا، تُعتبر هذه العملية عملية عملية إلى حد ما.
في الحالات التي تم فيها تدريب Stable Diffusion على عدد كافٍ من صور المشاهير، من الممكن التركيز على سعة وحدة معالجة الرسوميات بالكامل على عرض لاحق لوجه الصورة المقدمة فقط، وهو ما يمثل عادةً تحسنًا ملحوظًا - وعلى عكس GFPGAN، فإنه يعتمد على المعلومات من البيانات المدربة بواسطة LAION، بدلاً من مجرد تعديل وحدات البكسل المقدمة.
عمليات البحث داخل التطبيق LAION
منذ أن بدأ المستخدمون يدركون أن البحث في قاعدة بيانات LAION عن المفاهيم والأشخاص والموضوعات يمكن أن يكون بمثابة مساعد لاستخدام Stable Diffusion بشكل أفضل، تم إنشاء العديد من مستكشفات LAION عبر الإنترنت، بما في ذلك haveibeentrained.com.

تتيح وظيفة البحث في موقع haveibeentrained.com للمستخدمين استكشاف الصور التي تُشغّل الانتشار المستقر، ومعرفة ما إذا كانت الأشياء أو الأشخاص أو الأفكار التي قد يرغبون في استخلاصها من النظام قد تم تدريبها عليه. كما تُفيد هذه الأنظمة في اكتشاف الكيانات المتجاورة، مثل طريقة تجميع المشاهير، أو "الفكرة التالية" التي تُمهد الطريق للفكرة الحالية. المصدر: https://haveibeentrained.com/؟search_text=bowl٪20of٪20fruit
على الرغم من أن قواعد البيانات المستندة إلى الويب غالبًا ما تكشف عن بعض العلامات المصاحبة للصور ، فإن عملية تعميم التي تحدث أثناء تدريب النموذج يعني أنه من غير المحتمل أن يتم استدعاء أي صورة معينة باستخدام علامتها كموجه.
بالإضافة إلى ذلك ، فإن إزالة 'كلمات التوقف' وممارسة الاشتقاق والترجمة في معالجة اللغات الطبيعية تعني أن العديد من العبارات المعروضة تم تقسيمها أو حذفها قبل تدريبها على الانتشار المستقر.
ومع ذلك، فإن الطريقة التي تترابط بها التجمعات الجمالية مع بعضها البعض في هذه الواجهات يمكن أن تعلم المستخدم النهائي الكثير عن منطق (أو ربما "شخصية") الانتشار المستقر، وتثبت أنها تساعد في إنتاج صور أفضل.
خاتمة
هناك العديد من الميزات الأخرى التي أود رؤيتها في تنفيذ سطح مكتب أصلي كامل لـ Stable Diffusion، مثل تحليل الصور الأصلي المستند إلى CLIP، والذي يعكس عملية Stable Diffusion القياسية ويسمح للمستخدم باستنتاج العبارات والكلمات التي يربطها النظام بشكل طبيعي بالصورة المصدر أو العرض.
بالإضافة إلى ذلك ، سيكون القياس الحقيقي القائم على التجانب إضافة مرحب بها ، نظرًا لأن ESRGAN تقريبًا أداة حادة مثل GFPGAN. لحسن الحظ ، خطط لدمج com.txt2imghd يؤدي تطبيق GOBIG إلى جعل هذا الأمر حقيقة واقعة عبر التوزيعات ، ويبدو أنه خيار واضح لتكرار سطح المكتب.
لا تهمني بعض الطلبات الشائعة الأخرى من مجتمعات Discord ، مثل القواميس السريعة المتكاملة والقوائم القابلة للتطبيق للفنانين والأنماط ، على الرغم من أن دفتر الملاحظات داخل التطبيق أو معجم العبارات القابل للتخصيص قد يبدو إضافة منطقية.
وبالمثل ، فإن القيود الحالية للرسوم المتحركة التي تتمحور حول الإنسان في Stable Diffusion ، على الرغم من أنها بدأت من قبل CogVideo ومشاريع أخرى مختلفة ، لا تزال وليدة بشكل لا يصدق ، وتحت رحمة البحث الأولي في السوابق الزمنية المتعلقة بالحركة البشرية الأصيلة.
في الوقت الحالي ، يتم استخدام فيديو Stable Diffusion بدقة مخدرعلى الرغم من أنه قد يكون له مستقبل قريب أكثر إشراقًا في مجال العرائس المزيفة، من خلال EbSynth ومبادرات أخرى ناشئة نسبيًا لتحويل النصوص إلى مقاطع فيديو (ومن الجدير بالذكر عدم وجود أشخاص مُصنّعين أو "مُعدّلين" في Runway) أحدث فيديو ترويجي).
من الوظائف القيّمة الأخرى ميزة التمرير الشفاف في فوتوشوب، وهي ميزة مُستخدمة منذ زمن طويل في محرر الملمس Cinema4D، بالإضافة إلى تطبيقات أخرى مشابهة. بفضل هذه الميزة، يُمكن نقل الصور بين التطبيقات بسهولة، واستخدام كل تطبيق لإجراء التحويلات التي يُتقنها.
أخيرًا ، وربما الأهم من ذلك ، يجب ألا يكون برنامج Stable Diffusion الكامل لسطح المكتب قادرًا على التبديل بسهولة بين نقاط التفتيش (أي إصدارات النموذج الأساسي الذي يشغل النظام) فحسب ، بل يجب أن يكون قادرًا أيضًا على تحديث الانعكاسات النصية المصممة خصيصًا والتي نجحت مع إصدارات النموذج الرسمية السابقة ، ولكن قد يتم كسرها من خلال الإصدارات اللاحقة من النموذج (كما أشار المطورون في Discord الرسمي إلى أنه قد يكون هذا هو الحال).
ومن المفارقات ، أن المنظمة في أفضل وضع لإنشاء مثل هذه المصفوفة القوية والمتكاملة من الأدوات لـ Stable Diffusion ، Adobe ، قد تحالفت بقوة مع مبادرة أصالة المحتوى قد يبدو هذا بمثابة خطوة خاطئة في العلاقات العامة للشركة - ما لم يكن من شأنه أن يعيق القدرات التوليدية لـ Stable Diffusion تمامًا كما فعلت OpenAI مع DALL-E 2، ووضعها بدلاً من ذلك كتطور طبيعي لممتلكاتها الكبيرة في التصوير الفوتوغرافي.
نُشر لأول مرة في 15 سبتمبر 2022.












