قادة الفكر
3 طرق لجعل الحقائق القديمة طازجة في نماذج اللغة الكبيرة
نماذج اللغة الكبيرة (LLM) مثل GPT3 و ChatGPT و BARD هي كل العاصفة اليوم. كل شخص لديه رأي حول كيفية أن تكون هذه الأدوات جيدة أو سيئة للمجتمع وماذا تعني لمستقبل الذكاء الاصطناعي. تلقى جوجل الكثير من الانتقادات لخطأ نموذجها الجديد BARD في سؤال معقد (قليلا). عندما سئل “ما هي الاكتشافات الجديدة التي يمكنني إخبار ابني البالغ من العمر 9 سنوات عنها من تلسكوب جيمس ويب الفضائي؟” – قدم الدردشة ثلاثة إجابات ، من بينها إجابتان صحيحتان وإجابة خاطئة. الإجابة الخاطئة هي أن أول صورة “للكوكب الخارجي” تم التقاطها بواسطة JWST ، وهو خطأ. لذلك ، كان النموذج يحتوي على حقيقة خاطئة مخزنة في قاعدة معرفته. من أجل أن تكون نماذج اللغة الكبيرة فعالة ، نحن بحاجة إلى طريقة لتحديث هذه الحقائق أو تعزيز الحقائق بمعرفة جديدة.
لننظر أولاً إلى كيفية تخزين الحقائق داخل نموذج اللغة الكبير (LLM). لا تخزن نماذج اللغة الكبيرة المعلومات والحقائق بطريقة تقليدية مثل القواعد البيانية أو الملفات. بدلاً من ذلك ، تم تدريبها على كميات هائلة من بيانات النص وتعلمت الأنماط والعلاقات في تلك البيانات. هذا يسمح لها بإنتاج استجابات تشبه الإنسان للاستفسارات ، ولكنها لا تحتوي على موقع تخزين محدد لمعلوماتها المكتسبة. عند الإجابة على سؤال ، يستخدم النموذج تدريبه لإنشاء استجابة بناءً على الإدخال الذي يتلقاه. المعلومات والمعرفة التي يمتلكها نموذج اللغة هي نتيجة الأنماط التي تعلمها في البيانات التي تم تدريبه عليها ، وليس نتيجة تخزينها явًا في ذاكرة النموذج. لديها معمارية الترانسفورمر التي تقوم على معظم نماذج LLM الحديثة ، وهناك ترميز داخلي للحوادث يستخدم للاستجابة على السؤال المطروح في التحفيز.

إذا كانت الحقائق داخل الذاكرة الداخلية للنموذج LLM خاطئة أو قديمة ، فيجب تقديم معلومات جديدة عبر تحفيز. التحفيز هو النص المرسل إلى LLM مع الاستفسار والبيانات الداعمة التي يمكن أن تكون بعض الحقائق الجديدة أو المصححة. هنا ثلاث طرق للقيام بذلك.
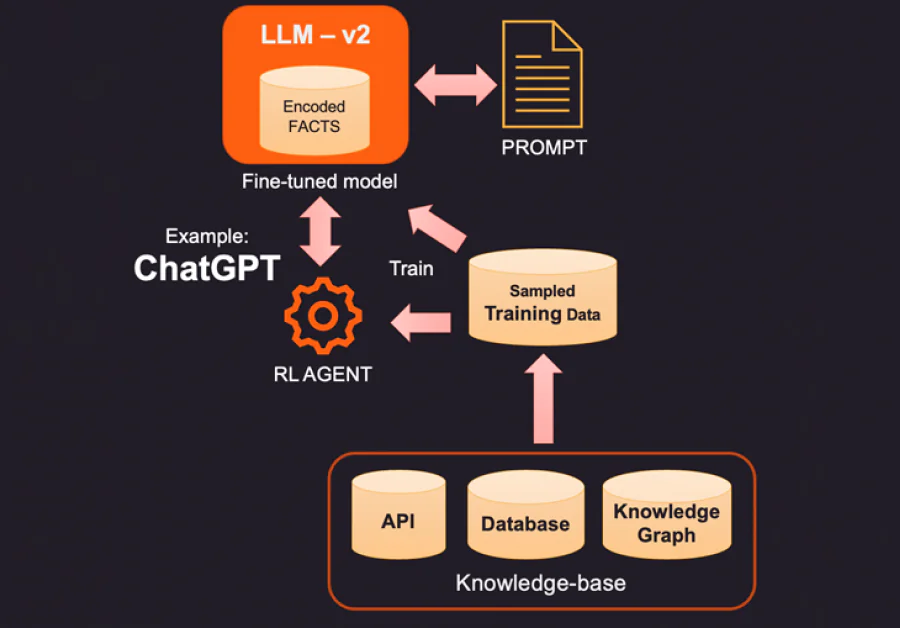
1. طريقة واحدة لتصحيح الحقائق المضفرة في نموذج LLM هي تقديم حقائق جديدة ذات صلة بالسياق باستخدام قاعدة معرفة خارجية. قد تكون هذه القاعدة البيانية مكالمات API للحصول على معلومات ذات صلة أو بحث في قاعدة بيانات SQL أو No-SQL أو Vector. يمكن استخراج معرفة أكثر تقدمًا من مخطط معرفي يخزن كيانات البيانات والعلاقات بينها. اعتمادًا على المعلومات التي يطلبها المستخدم ، يمكن استرجاع المعلومات السياقية ذات الصلة وتقديمها كحقائق إضافية إلى نموذج LLM. يمكن أيضًا تنسيق هذه الحقائق لتبدو مثل أمثلة التدريب لتحسين عملية التعلم. على سبيل المثال ، يمكنك تمرير مجموعة من أزواج الأسئلة والإجابات لتعليم النموذج كيفية تقديم الإجابات.

2. طريقة أكثر إبداعًا (ومكلفة) لتعزيز نموذج LLM هي التعديل الفعلي باستخدام بيانات التدريب. بدلاً من استفسار قاعدة المعرفة للحصول على حقائق محددة لإضافتها ، ننشئ مجموعة بيانات تدريبية عن طريق أخذ عينات من قاعدة المعرفة. باستخدام تقنيات التعلم الإشرافي مثل التعديل الدقيق ، يمكننا إنشاء إصدارًا جديدًا من نموذج LLM مدرب على هذه المعرفة الإضافية. هذا العملية غالبًا ما تكون مكلفة ويمكن أن تكلّف بضعة آلاف من الدولارات لإنشاء نموذج مدرب دقيق في OpenAI. بالطبع ، من المتوقع أن ينخفض التكلفة مع مرور الوقت.
3. خيار آخر هو استخدام طرق مثل التعلم التعزيزي (RL) لتدريب وكيل مع تعليقات بشرية وتعلم سياسة على كيفية الإجابة على الأسئلة. كانت هذه الطريقة فعالة للغاية في بناء نماذج صغيرة ذات بصمة جيدة تتميز بمهام محددة. على سبيل المثال ، تم إصدار ChatGPT الشهير من OpenAI بتدريب على مزيج من التعلم الإشرافي والتعلم التعزيزي مع تعليقات بشرية.

في الخلاصة ، هذا هو مجال يتطور بسرعة ، حيث يريد كل شركة كبرى أن تدخل فيه وإظهار تميّزها. سنرى قريباً أدوات LLM الرئيسية في معظم المجالات مثل التجزئة والرعاية الصحية والخدمات المصرفية التي يمكنها الاستجابة بطريقة تشبه الإنسان وفهم دقائق اللغة. يمكن أن تسهل أدوات LLM هذه المتكاملة مع بيانات الشركات الوصول إلى المعلومات الصحيحة للأشخاص المناسبين في الوقت المناسب.












