
Kunsmatige Intelligensie
YOLOv7: Die mees gevorderde objekopsporingsalgoritme?

6 Julie 2022 sal as 'n landmerk in KI-geskiedenis afgemerk word, want dit was op hierdie dag toe YOLOv7 vrygestel is. Sedert sy bekendstelling was die YOLOv7 die warmste onderwerp in die Computer Vision-ontwikkelaargemeenskap, en om die regte redes. YOLOv7 word reeds as 'n mylpaal in die objekbespeuringsbedryf beskou.
Kort na die YOLOv7 vraestel is gepubliseer, dit het opgedaag as die vinnigste en mees akkurate model vir beswaaropsporing in reële tyd. Maar hoe kompeteer YOLOv7 sy voorgangers? Wat maak YOLOv7 so doeltreffend om rekenaarvisietake uit te voer?
In hierdie artikel sal ons probeer om die YOLOv7-model te ontleed, en probeer om die antwoord te vind waarom YOLOv7 nou industriestandaard word? Maar voordat ons dit kan beantwoord, sal ons eers na die kort geskiedenis van voorwerpopsporing moet kyk.
Wat is voorwerpopsporing?
Voorwerpopsporing is 'n tak in rekenaarvisie wat voorwerpe in 'n prent of 'n videolêer identifiseer en opspoor. Voorwerpopsporing is die bousteen van talle toepassings, insluitend selfbesturende motors, gemonitorde toesig en selfs robotika.
'n Voorwerpopsporingsmodel kan in twee verskillende kategorieë geklassifiseer word, enkelskoot detektors, en multi-skoot detektors.
Intydse voorwerpopsporing
Om werklik te verstaan hoe YOLOv7 werk, is dit noodsaaklik dat ons YOLOv7 se hoofdoelwit verstaan, "Intydse voorwerpopsporing". Real Time Object Detection is 'n sleutelkomponent van moderne rekenaarvisie. Die Real Time Object Detection-modelle probeer om voorwerpe van belang in reële tyd te identifiseer en op te spoor. Real Time Object Detection-modelle het dit baie doeltreffend gemaak vir ontwikkelaars om voorwerpe van belang op te spoor in 'n bewegende raam soos 'n video, of 'n lewendige toesiginvoer.

Real Time Object Detection-modelle is in wese 'n stap vorentoe van die konvensionele beeldopsporingsmodelle. Terwyl eersgenoemde gebruik word om voorwerpe in videolêers op te spoor, vind en identifiseer laasgenoemde voorwerpe binne 'n stilstaande raam soos 'n beeld.
Gevolglik is Real Time Object Detection-modelle werklik doeltreffend vir video-analise, outonome voertuie, objektelling, multi-voorwerpopsporing, en nog baie meer.
Wat is YOLO?
YOLO of "Jy kyk net een keer” is 'n familie van intydse objekbespeuringsmodelle. Die YOLO-konsep is vir die eerste keer in 2016 deur Joseph Redmon bekendgestel, en dit was byna onmiddellik die gesprek van die dorp, want dit was baie vinniger en baie meer akkuraat as die bestaande objekbespeuringsalgoritmes. Dit was nie lank voordat die YOLO-algoritme 'n standaard in die rekenaarvisiebedryf geword het nie.

Die fundamentele konsep wat die YOLO-algoritme voorstel, is om 'n end-tot-end neurale netwerk te gebruik deur grenskasies en klaswaarskynlikhede te gebruik om voorspellings in reële tyd te maak. YOLO was anders as die vorige objekbespeuringsmodel in die sin dat dit 'n ander benadering voorgestel het om voorwerpopsporing uit te voer deur klassifiseerders te hergebruik.
Die verandering in benadering het gewerk aangesien YOLO gou die industriestandaard geword het, aangesien die prestasiegaping tussen homself en ander intydse objekbespeuringsalgoritmes beduidend was. Maar wat was die rede waarom YOLO so doeltreffend was?
In vergelyking met YOLO, het voorwerpopsporingsalgoritmes destyds Streekvoorstelnetwerke gebruik om moontlike streke van belang op te spoor. Die erkenningsproses is dan op elke streek afsonderlik uitgevoer. As gevolg hiervan het hierdie modelle dikwels verskeie iterasies op dieselfde beeld uitgevoer, en vandaar die gebrek aan akkuraatheid en hoër uitvoeringstyd. Aan die ander kant gebruik die YOLO-algoritme 'n enkele volledig gekoppelde laag om die voorspelling gelyktydig uit te voer.
Hoe werk YOLO?
Daar is drie stappe wat verduidelik hoe 'n YOLO-algoritme werk.
Herraam voorwerpopsporing as 'n enkele regressieprobleem
Die YOLO-algoritme probeer om voorwerpopsporing te herraam as 'n enkele regressieprobleem, insluitend beeldpiksels, tot klaswaarskynlikhede, en grenskaskoördinate. Daarom moet die algoritme net een keer na die beeld kyk om die teikenvoorwerpe in die beelde te voorspel en op te spoor.
Redes die beeld wêreldwyd
Verder, wanneer die YOLO-algoritme voorspellings maak, redeneer dit die beeld wêreldwyd. Dit verskil van streekvoorstel-gebaseerde en gly-tegnieke, aangesien die YOLO-algoritme die volledige beeld sien tydens opleiding en toetsing op die datastel, en in staat is om kontekstuele inligting oor die klasse en hoe dit voorkom te enkodeer.
Voor YOLO was Fast R-CNN een van die gewildste objekbespeuringsalgoritmes wat nie die groter konteks in die prent kon sien nie omdat dit vroeër agtergrondkolle in 'n prent vir 'n voorwerp verwar het. In vergelyking met die Fast R-CNN-algoritme, is YOLO 50% meer akkuraat wanneer dit by agtergrondfoute kom.
Veralgemeen voorstelling van voorwerpe
Laastens het die YOLO-algoritme ook ten doel om die voorstellings van voorwerpe in 'n beeld te veralgemeen. As gevolg hiervan, toe 'n YOLO-algoritme op 'n datastel met natuurlike beelde uitgevoer is en vir die resultate getoets is, het YOLO 'n wye marge beter as bestaande R-CNN-modelle gevaar. Dit is omdat YOLO hoogs veralgemeenbaar is, die kanse dat dit breek wanneer dit op onverwagte insette of nuwe domeine geïmplementeer word, was skraal.
YOLOv7: Wat is nuut?
Noudat ons 'n basiese begrip het van wat intydse voorwerpopsporingsmodelle is, en wat die YOLO-algoritme is, is dit tyd om die YOLOv7-algoritme te bespreek.
Optimalisering van die opleidingsproses
Die YOLOv7-algoritme probeer nie net om die modelargitektuur te optimaliseer nie, maar dit poog ook om die opleidingsproses te optimaliseer. Dit is daarop gemik om optimaliseringsmodules en -metodes te gebruik om die akkuraatheid van voorwerpopsporing te verbeter, die koste vir opleiding te versterk, terwyl die interferensiekoste gehandhaaf word. Daar kan na hierdie optimaliseringsmodules verwys word as 'n opleibare sak gratis.
Grof tot fyn loodgeleide etikettoewysing
Die YOLOv7-algoritme beplan om 'n nuwe grof tot fyn loodgeleide etikettoewysing in plaas van die konvensionele Dinamiese etikettoewysing. Dit is so omdat met dinamiese etikettoewysing, die opleiding van 'n model met veelvuldige uitsetlae 'n paar probleme veroorsaak, waarvan die mees algemene een daarvan is hoe om dinamiese teikens vir verskillende takke en hul uitsette toe te ken.
Model Herparameterisering
Modelherparametrisering is 'n belangrike konsep in objekopsporing, en die gebruik daarvan word oor die algemeen gevolg met 'n paar probleme tydens opleiding. Die YOLOv7-algoritme beplan om die konsep van gradiëntvoortplantingspad om die modelherparametriseringsbeleide te ontleed van toepassing op verskillende lae in die netwerk.
Verleng en saamgestelde skaal
Die YOLOv7-algoritme stel ook die uitgebreide en saamgestelde skaalmetodes om die parameters en berekeninge te gebruik en effektief te gebruik vir intydse objekopsporing.

YOLOv7 : Verwante werk
Intydse voorwerpopsporing
YOLO is tans die industriestandaard, en die meeste van die intydse objekverklikkers ontplooi YOLO-algoritmes, en FCOS (Fully Convolutional One-Stage Object-Detection). 'n Moderne intydse voorwerpdetektor het gewoonlik die volgende kenmerke
- Sterker en vinniger netwerkargitektuur.
- 'N Effektiewe kenmerk-integrasiemetode.
- 'n Akkurate objek-opsporingsmetode.
- 'n Sterk verliesfunksie.
- 'n Doeltreffende etikettoewysingsmetode.
- 'n Doeltreffende opleidingsmetode.
Die YOLOv7-algoritme gebruik nie selftoesig-leer- en distillasiemetodes wat dikwels groot hoeveelhede data benodig nie. Omgekeerd gebruik die YOLOv7-algoritme 'n opleibare sak-van-gratis-metode.
Model Herparameterisering
Modelherparameteriseringstegnieke word beskou as 'n ensembletegniek wat verskeie berekeningsmodules in 'n interferensiestadium saamsmelt. Die tegniek kan verder in twee kategorieë verdeel word, model-vlak ensemble, en module-vlak ensemble.
Nou, om die finale interferensiemodel te verkry, gebruik die modelvlak herparameteriseringstegniek twee praktyke. Die eerste oefening gebruik verskillende opleidingsdata om talle identiese modelle op te lei, en dan gemiddeld die gewigte van die opgeleide modelle. Alternatiewelik bereken die ander praktyk die gewigte van modelle tydens verskillende iterasies.
Modulevlakherparameterisering is onlangs besig om groot gewildheid te wen omdat dit 'n module in verskillende modulevertakkings, of verskillende identiese takke tydens die opleidingsfase verdeel, en dan voortgaan om hierdie verskillende takke in 'n ekwivalente module te integreer terwyl dit inmenging.
Herparameteriseringstegnieke kan egter nie op alle soorte argitektuur toegepas word nie. Dit is die rede waarom die YOLOv7-algoritme gebruik nuwe modelherparameteriseringstegnieke om verwante strategieë te ontwerp geskik vir verskillende argitekture.
Model skaal
Modelskaal is die proses om 'n bestaande model op of af te skaal sodat dit oor verskillende rekenaartoestelle pas. Modelskaal gebruik gewoonlik 'n verskeidenheid faktore soos aantal lae (diepte), grootte van invoer beelde (resolusie), aantal kenmerkpiramides(stadium), en aantal kanale (wydte). Hierdie faktore speel 'n deurslaggewende rol om 'n gebalanseerde afweging vir netwerkparameters, interferensiespoed, berekening en akkuraatheid van die model te verseker.
Een van die mees gebruikte skaalmetodes is NAS- of netwerkargitektuursoektog wat outomaties soek vir geskikte skaalfaktore van soekenjins sonder enige ingewikkelde reëls. Die grootste nadeel van die gebruik van die NAS is dat dit 'n duur benadering is om geskikte skaalfaktore te soek.
Byna elke modelherparameteriseringsmodel ontleed individuele en unieke skaalfaktore onafhanklik, en optimaliseer selfs hierdie faktore onafhanklik. Dit is omdat die NAS-argitektuur met nie-gekorreleerde skaalfaktore werk.
Dit is opmerklik dat aaneenskakelingsgebaseerde modelle soos VoVNet or DigNet verander die invoerwydte van 'n paar lae wanneer die diepte van die modelle geskaal word. YOLOv7 werk op 'n voorgestelde samevoeging-gebaseerde argitektuur, en gebruik dus 'n saamgestelde skaalmetode.

Die figuur hierbo genoem vergelyk die uitgebreide doeltreffende laag-aggregasienetwerke (E-ELAN) van verskillende modelle. Die voorgestelde E-ELAN-metode handhaaf die gradiënt-oordragpad van die oorspronklike argitektuur, maar het ten doel om die kardinaliteit van die bygevoegde kenmerke te verhoog deur gebruik te maak van groepkonvolusie. Die proses kan die kenmerke wat deur verskillende kaarte geleer word verbeter, en kan die gebruik van berekeninge en parameters verder doeltreffender maak.
YOLOv7 Argitektuur
Die YOLOv7-model gebruik die YOLOv4-, YOLO-R- en die Scaled YOLOv4-modelle as basis. Die YOLOv7 is 'n resultaat van die eksperimente wat op hierdie modelle uitgevoer is om die resultate te verbeter en die model meer akkuraat te maak.
Uitgebreide Doeltreffende Laag Aggregasie Netwerk of E-ELAN
E-ELAN is die fundamentele bousteen van die YOLOv7-model, en dit is afgelei van reeds bestaande modelle oor netwerkdoeltreffendheid, hoofsaaklik die ELAN.
Die hoofoorwegings by die ontwerp van 'n doeltreffende argitektuur is die aantal parameters, berekeningsdigtheid en die hoeveelheid berekening. Ander modelle neem ook faktore in ag soos die invloed van inset/uitsetkanaalverhouding, takke in die argitektuurnetwerk, netwerkinterferensiespoed, aantal elemente in die tensors van konvolusienetwerk, en meer.
Die CSPVoNet model oorweeg nie net die bogenoemde parameters nie, maar dit ontleed ook die gradiëntpad om meer diverse kenmerke te leer deur die gewigte van verskillende lae moontlik te maak. Die benadering laat die steurings baie vinniger en akkuraat wees. Die ELAN argitektuur het ten doel om 'n doeltreffende netwerk te ontwerp om die kortste langste gradiëntpad te beheer sodat die netwerk meer effektief kan wees in leer, en konvergeer.
ELAN het reeds 'n stabiele stadium bereik ongeag die stapelgetal berekeningsblokke en gradiëntpadlengte. Die stabiele toestand kan vernietig word as berekeningsblokke onbeperk gestapel word, en die parameterbenuttingskoers sal afneem. Die voorgestelde E-ELAN-argitektuur kan die probleem oplos, aangesien dit uitbreiding, skuifel en saamsmeltkardinaliteit gebruik om voortdurend die netwerk se leervermoë te verbeter terwyl die oorspronklike gradiëntpad behou word.
Verder, wanneer die argitektuur van E-ELAN met ELAN vergelyk word, die enigste verskil is in die berekeningsblok, terwyl die oorgangslaag se argitektuur onveranderd is.
E-ELAN stel voor om die kardinaliteit van die berekeningsblokke uit te brei, en die kanaal uit te brei deur te gebruik groep konvolusie. Die kenmerkkaart sal dan bereken word, en in groepe geskuif word volgens die groepparameter, en sal dan saamgevoeg word. Die aantal kanale in elke groep sal dieselfde bly as in die oorspronklike argitektuur. Laastens sal die groepe kenmerkkaarte bygevoeg word om kardinaliteit te verrig.
Modelskaal vir samevoeginggebaseerde modelle
Modelskaal help in eienskappe van die modelle aan te pas wat help met die generering van modelle volgens die vereistes, en van verskillende skale om aan die verskillende interferensiespoed te voldoen.

Die figuur praat oor modelskaal vir verskillende aaneenskakelingsgebaseerde modelle. Soos jy kan in figuur (a) en (b), neem die uitsetwydte van die berekeningsblok toe met 'n toename in die diepteskaal van die modelle. Gevolglik word die insetwydte van die transmissielae vergroot. As hierdie metodes op samevoeginggebaseerde argitektuur geïmplementeer word, word die skaalproses in diepte uitgevoer, en dit word in figuur (c) uitgebeeld.
Daar kan dus tot die gevolgtrekking gekom word dat dit nie moontlik is om die skaalfaktore onafhanklik te ontleed vir aaneenskakelingsgebaseerde modelle nie, en eerder saam oorweeg of ontleed moet word. Daarom, vir 'n aaneenskakelingsgebaseerde model, dit is geskik om die ooreenstemmende saamgestelde model-skaalmetode te gebruik. Daarbenewens, wanneer die dieptefaktor geskaal word, moet die uitsetkanaal van die blok ook geskaal word.
Opleibare sak gratis
'n Sakkie gratis items is 'n term wat ontwikkelaars gebruik om te beskryf 'n stel metodes of tegnieke wat die opleidingstrategie of -koste kan verander in 'n poging om model akkuraatheid 'n hupstoot te gee. So, wat is hierdie opleibare sakke gratis in YOLOv7? Kom ons kyk.
Beplande hergeparameteriseerde konvolusie
Die YOLOv7-algoritme gebruik gradiëntvloeivoortplantingspaaie om te bepaal hoe om 'n netwerk ideaal te kombineer met die hergeparameteriseerde konvolusie. Hierdie benadering deur YOLov7 is 'n poging om teë te werk RepConv algoritme dat hoewel dit rustig op die VGG-model gevaar het, swak presteer wanneer dit direk op die DenseNet- en ResNet-modelle toegepas word.
Om die verbindings in 'n konvolusielaag te identifiseer, is die RepConv-algoritme kombineer 3×3-konvolusie en 1×1-konvolusie. As ons die algoritme, sy werkverrigting en die argitektuur ontleed, sal ons waarneem dat RepConv die aaneenskakeling in DenseNet, en die res in ResNet.

Die prent hierbo beeld 'n beplande herparametriseerde model uit. Dit kan gesien word dat die YOLov7-algoritme gevind het dat 'n laag in die netwerk met aaneenskakeling of residuele verbindings nie 'n identiteitsverbinding in die RepConv-algoritme behoort te hê nie. Gevolglik is dit aanvaarbaar om met RepConvN oor te skakel sonder identiteitsverbindings.
Grof vir Hulp en Boet vir Loodverlies
Diep toesig is 'n tak in rekenaarwetenskap wat dikwels sy gebruik vind in die opleidingsproses van diep netwerke. Die fundamentele beginsel van diep toesig is dat dit voeg 'n bykomende hulpkop in die middelste lae van die netwerk by saam met die vlak netwerkgewigte met assistentverlies as sy gids. Die YOLOv7-algoritme verwys na die kop wat verantwoordelik is vir die finale uitset as die hoofkop, en die hulpkop is die kop wat met opleiding help.
Deur voort te beweeg, gebruik YOLOv7 'n ander metode vir etikettoewysing. Konvensioneel is etikettoewysing gebruik om etikette te genereer deur direk na die grondwaarheid te verwys, en op grond van 'n gegewe stel reëls. In onlangse jare speel die verspreiding en kwaliteit van die voorspellingsinsette egter 'n belangrike rol om 'n betroubare etiket te genereer. YOLOv7 genereer 'n sagte etiket van die voorwerp deur die voorspellings van grenskas en grondwaarheid te gebruik.
Verder gebruik die nuwe etikettoewysingsmetode van die YOLOv7-algoritme die hoofkop se voorspellings om beide die voorsprong en die hulpkop te lei. Die etikettoewysingsmetode het twee voorgestelde strategieë.
Hoofbegeleide etikettoewyser
Die strategie maak berekeninge op grond van die hoofhoof se voorspellingsresultate, en die grondwaarheid, en gebruik dan optimalisering om sagte etikette te genereer. Hierdie sagte etikette word dan gebruik as die opleidingsmodel vir beide die loodkop en die hulpkop.
Die strategie werk op die aanname dat omdat die hoofhoof 'n groter leervermoë het, die etikette wat dit genereer meer verteenwoordigend moet wees, en moet korreleer tussen die bron en die teiken.
Grof-tot-fyn Loodkop Begeleide Etikettoewyser
Hierdie strategie maak ook berekeninge op grond van die hoofhoof se voorspellingsresultate, en die grondwaarheid, en gebruik dan optimering om sagte etikette te genereer. Daar is egter 'n sleutelverskil. In hierdie strategie is daar twee stelle sagte etikette, growwe vlak, en fyn etiket.
Die growwe etiket word gegenereer deur die beperkings van die positiewe monster te verslap
opdragproses wat meer roosters as positiewe teikens behandel. Dit word gedoen om die risiko te vermy om inligting te verloor as gevolg van die hulphoof se swakker leerkrag.

Die figuur hierbo verduidelik die gebruik van 'n opleibare sak gratis in die YOLOv7-algoritme. Dit beeld grof uit vir die hulpkop, en fyn vir die loodkop. Wanneer ons 'n Model met Hulpkop(b) met die Normale Model (a) vergelyk, sal ons sien dat die skema in (b) 'n hulpkop het, terwyl dit nie in (a) is nie.
Figuur (c) beeld die algemene onafhanklike etikettoewyser uit, terwyl figuur (d) en figuur (e) onderskeidelik die Lead Guided Assigner verteenwoordig, en die Coarse-toFine Lead Guided Assigner wat deur YOLOv7 gebruik word.
Ander opleibare sak gratis
Benewens dié wat hierbo genoem is, gebruik die YOLOv7-algoritme bykomende sakke gratis, hoewel dit nie oorspronklik deur hulle voorgestel is nie. Hulle is
- Batch Normalization in Conv-Bn-Activation Technology: Hierdie strategie word gebruik om 'n konvolusielaag direk aan die bondelnormaliseringslaag te koppel.
- Implisiete kennis in YOLOR: Die YOLOv7 kombineer die strategie met die Convolutional-kenmerkkaart.
- EMA Model: Die EMA-model word as 'n finale verwysingsmodel in YOLOv7 gebruik, alhoewel die primêre gebruik daarvan in die gemiddelde onderwyser-metode gebruik moet word.
YOLOv7 : Eksperimente
Eksperimentele opstelling
Die YOLOv7-algoritme gebruik die Microsoft COCO-datastel vir opleiding en validering hul objek-opsporingsmodel, en nie al hierdie eksperimente gebruik 'n vooraf-opgeleide model nie. Die ontwikkelaars het die 2017-treindatastel vir opleiding gebruik en die 2017-valideringsdatastel gebruik om die hiperparameters te kies. Laastens word die prestasie van die YOLOv7-objekopsporingsresultate vergelyk met die nuutste algoritmes vir objekopsporing.
Ontwikkelaars het 'n basiese model ontwerp vir rand GPU (YOLOv7-klein), normale GPU (YOLOv7), en wolk GPU (YOLOv7-W6). Verder gebruik die YOLOv7-algoritme ook 'n basiese model vir modelskaal volgens verskillende diensvereistes, en kry verskillende modelle. Vir die YOLOv7-algoritme word die stapelskaal op die nek gedoen, en voorgestelde verbindings word gebruik om die diepte en breedte van die model op te skaal.
Basislyne
Die YOLOv7-algoritme gebruik vorige YOLO-modelle, en die YOLOR-objekbespeuringsalgoritme as sy basislyn.

Die figuur hierbo vergelyk die basislyn van die YOLOv7-model met ander objekbespeuringsmodelle, en die resultate is redelik duidelik. In vergelyking met die YOLOv4-algoritme, YOLOv7 gebruik nie net 75% minder parameters nie, maar dit gebruik ook 15% minder berekening, en het 0.4% hoër akkuraatheid.
Vergelyking met moderne voorwerpdetektormodelle

Die bostaande figuur toon die resultate wanneer YOLOv7 vergelyk word met die nuutste voorwerpopsporingsmodelle vir mobiele en algemene GPU's. Daar kan waargeneem word dat die metode wat deur die YOLOv7-algoritme voorgestel word, die beste spoed-akkuraatheid-afruiltelling het.
Ablasiestudie: Voorgestelde saamgestelde skaalmetode

Die figuur hierbo vergelyk die resultate van die gebruik van verskillende strategieë om die model op te skaal. Die skaalstrategie in die YOLOv7-model skaal die diepte van die berekeningsblok met 1.5 keer op, en skaal die breedte met 1.25 keer.
In vergelyking met 'n model wat net die diepte opskaal, presteer die YOLOv7-model beter met 0.5% terwyl minder parameters en rekenkrag gebruik word. Aan die ander kant, in vergelyking met modelle wat net die diepte opskaal, word YOLOv7 se akkuraatheid met 0.2% verbeter, maar die aantal parameters moet met 2.9% geskaal word, en berekening met 1.2%.
Voorgestelde beplande hergeparameteriseerde model
Om die algemeenheid van sy voorgestelde hergeparameteriseerde model te verifieer, die YOLOv7-algoritme gebruik dit op residu-gebaseerde en aaneenskakelingsgebaseerde modelle vir verifikasie. Vir die verifikasieproses gebruik die YOLOv7-algoritme 3-stapel ELAN vir die samevoeging-gebaseerde model, en CSPDarknet vir residu-gebaseerde model.
Vir die aaneenskakelingsgebaseerde model vervang die algoritme die 3 × 3 konvolusionele lae in die 3-gestapelde ELAN met RepConv. Die figuur hieronder toon die gedetailleerde konfigurasie van Planned RepConv, en 3-stapel ELAN.
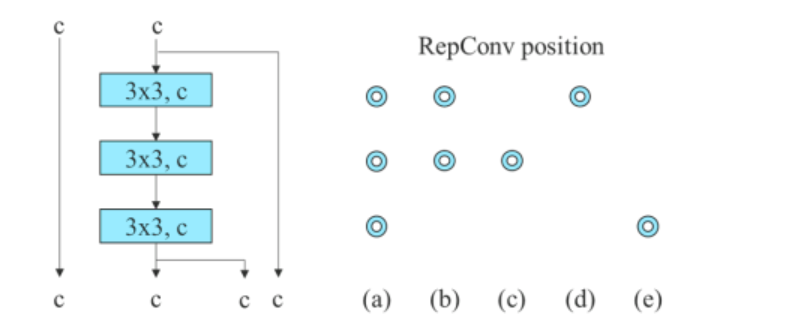
Verder, wanneer die oorblywende-gebaseerde model hanteer word, gebruik die YOLOv7-algoritme 'n omgekeerde donker blok omdat die oorspronklike donker blok nie 'n 3×3 konvolusieblok het nie. Die onderstaande figuur toon die argitektuur van die Omgekeerde CSPDarknet wat die posisies van die 3×3 en die 1×1 konvolusielaag omkeer. 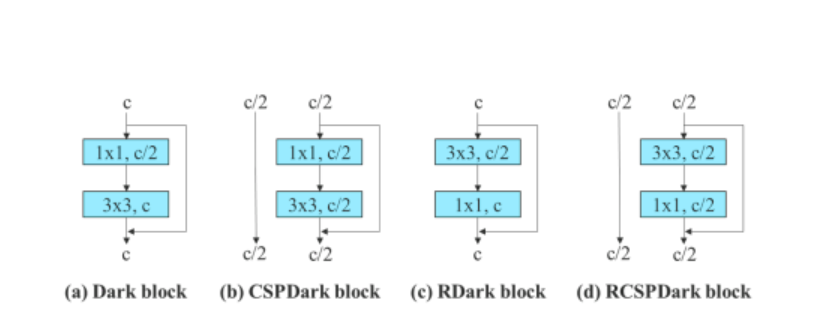
Voorgestelde assistentverlies vir hulphoof
Vir die assistentverlies vir hulpkop, vergelyk die YOLOv7-model die onafhanklike etikettoewysing vir die hulpkop- en loodkopmetodes.

Die figuur hierbo bevat die resultate van die studie oor die voorgestelde hulpkop. Dit kan gesien word dat die algehele prestasie van die model toeneem met 'n toename in die assistentverlies. Verder presteer die loodgeleide etikettoewysing wat deur die YOLOv7-model voorgestel word beter as onafhanklike loodtoewysingstrategieë.
YOLOv7 resultate
Gebaseer op die bogenoemde eksperimente, hier is die resultaat van YOLov7 se werkverrigting in vergelyking met ander voorwerpopsporingsalgoritmes.

Die bostaande figuur vergelyk die YOLOv7-model met ander objek-opsporingsalgoritmes, en dit kan duidelik waargeneem word dat die YOLOv7 ander beswaaropsporingsmodelle oortref t.o.v. Gemiddelde akkuraatheid (AP) v/s bondelinterferensie.
Verder vergelyk die onderstaande figuur die werkverrigting van YOLOv7 v/s ander intydse beswaaropsporingsalgoritmes. Weereens, YOLOv7 volg ander modelle op in terme van die algehele werkverrigting, akkuraatheid en doeltreffendheid.

Hier is 'n paar bykomende waarnemings van die YOLOv7 resultate en optredes.
- Die YOLOv7-Tiny is die kleinste model in die YOLO-familie, met meer as 6 miljoen parameters. Die YOLOv7-Tiny het 'n gemiddelde presisie van 35.2%, en dit vaar beter as die YOLOv4-Tiny-modelle met vergelykbare parameters.
- Die YOLOv7-model het meer as 37 miljoen parameters, en dit vaar beter as modelle met hoër parameters soos YOLov4.
- Die YOLOv7-model het die hoogste mAP- en FPS-koers in die reeks van 5 tot 160 FPS.
Gevolgtrekking
YOLO of You Only Look Once is die moderne voorwerpopsporingsmodel in moderne rekenaarvisie. Die YOLO-algoritme is bekend vir sy hoë akkuraatheid en doeltreffendheid, en gevolglik vind dit uitgebreide toepassing in die intydse voorwerpopsporingsbedryf. Sedert die eerste YOLO-algoritme in 2016 bekendgestel is, het eksperimente ontwikkelaars in staat gestel om die model voortdurend te verbeter.
Die YOLOv7-model is die nuutste toevoeging in die YOLO-familie, en dit is die kragtigste YOLO-algoritme tot dusver. In hierdie artikel het ons oor die grondbeginsels van YOLOv7 gepraat en probeer verduidelik wat YOLOv7 so doeltreffend maak.















