
Kunsmatige Intelligensie
ST-NeRF: Samestelling en redigering vir videosintese

'n Chinese navorsingskonsortium het ontwikkel tegnieke om redigering en samestelling vermoëns te bring na een van die warmste beeldsintese navorsingsektore van die afgelope jaar – Neural Radiance Fields (NeRF). Die stelsel is getitel ST-NeRF (Spatio-Temporal Coherent Neural Radiance Field).
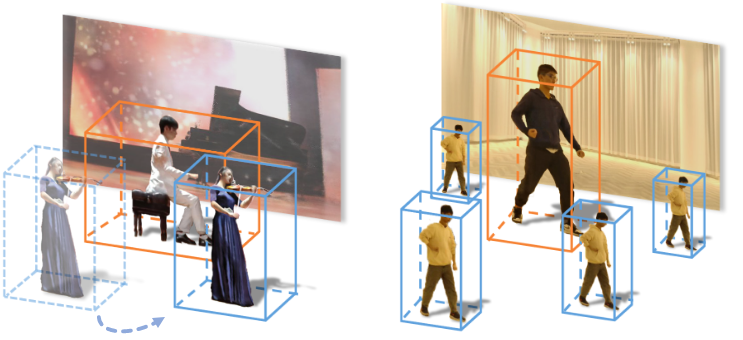
Wat lyk na 'n fisiese kamera-pan in die prent hieronder, is eintlik net 'n gebruiker wat deur standpunte oor video-inhoud wat in 'n 4D-ruimte bestaan, 'blaai'. Die POV is nie gesluit vir die prestasie van die mense wat in die video uitgebeeld word nie, wie se bewegings vanuit enige deel van 'n 180-grade radius gesien kan word.

Elke faset binne die video is 'n diskreet vasgevang element, saamgestel in 'n samehangende toneel wat dinamies verken kan word.
Die fasette kan vrylik binne die toneel gedupliseer word, of verander word:

Boonop kan die temporele gedrag van elke faset maklik verander, vertraag, agteruit hardloop of op enige aantal maniere gemanipuleer word, wat die pad oopmaak om argitekture te filter en 'n uiters hoë vlak van interpreteerbaarheid.

Twee afsonderlike NeRF-fasette loop teen verskillende spoed in dieselfde toneel. Bron: https://www.youtube.com/watch?v=Wp4HfOwFGP4
Dit is nie nodig om kunstenaars of omgewings te rotoskoop nie, of om kunstenaars hul bewegings blindelings en buite die konteks van die beoogde toneel te laat uitvoer. In plaas daarvan word beeldmateriaal natuurlik vasgelê via 'n verskeidenheid van 16 videokameras wat 180 grade dek:


Die drie elemente wat hierbo uitgebeeld is, die twee mense en die omgewing, is onderskeibaar en word slegs vir illustratiewe doeleindes uiteengesit. Elkeen kan omgeruil word, en elkeen kan op 'n vroeër of later punt in hul individuele vasvangtydlyn in die toneel ingevoeg word.
ST-NeRF is 'n innovasie oor navorsing in neurale uitstralingsvelde (NeRF), 'n masjienleerraamwerk waardeur veelvuldige oogpuntvasleggings gesintetiseer word in 'n bevaarbare virtuele ruimte deur uitgebreide opleiding (hoewel enkelstandpuntvaslegging ook 'n subsektor van NeRF-navorsing is).

Neurale uitstralingsvelde werk deur verskeie vangstandpunte in 'n enkele samehangende en navigeerbare 3D-ruimte te versamel, met die gapings tussen dekking wat deur 'n neurale netwerk geskat en weergegee word. Waar video (eerder as stilbeelde) gebruik word, is die leweringshulpbronne wat benodig word dikwels aansienlik. Bron: https://www.matthewtancik.com/nerf
Belangstelling in NeRF het die afgelope nege maande intens geword, en 'n Reddit-onderhou lys van afgeleide of verkennende NeRF-vraestelle lys tans sestig projekte.

Net 'n paar van die vele uitlopers van die oorspronklike NeRF-vraestel. Bron: https://crossminds.ai/graphlist/nerf-neural-radiance-fields-ai-research-graph-60708936c8663c4cfa875fc2/
Bekostigbare opleiding
Die referaat is 'n samewerking tussen navorsers by Shanghai Tech University en DGene Digitale Tegnologie, en is met 'n mate van entoesiasme aanvaar by Open Review.
ST-NeRF bied 'n aantal innovasies oor vorige inisiatiewe in ML-afgeleide navigeerbare videoruimtes. Dit bereik nie die minste nie 'n hoë vlak van realisme met slegs 16 kameras. Alhoewel Facebook s'n DyNeRF gebruik slegs twee kameras meer as dit, dit bied 'n baie meer beperkte navigeerbare boog.

'n Voorbeeld van Facebook se DyNeRF-omgewing, met 'n meer beperkte bewegingsveld, en meer kameras per vierkante voet wat nodig is om die toneel te rekonstrueer. Bron: https://neural-3d-video.github.io
Behalwe dat dit nie die vermoë het om individuele fasette te redigeer en saam te stel nie, is DyNeRF besonder duur in terme van rekenaarhulpbronne. Daarenteen sê die Chinese navorsers dat die opleidingskoste vir hul data iewers tussen $900-$3,000 uitkom, vergeleke met die $30,000 vir die moderne videogenerasiemodel DVDGAN, en intensiewe stelsels soos DyNeRF.
Beoordelaars het ook opgemerk dat ST-NeRF 'n groot innovasie maak in die ontkoppeling van die proses van leerbeweging van die proses van beeldsintese. Hierdie skeiding is wat redigering en samestelling moontlik maak, met vorige benaderings beperkend en lineêr in vergelyking.
Alhoewel 16 kameras 'n baie beperkte reeks is vir so 'n volle halfsirkel van aansig, hoop die navorsers om hierdie getal verder te verminder in latere werk deur die gebruik van instaanbediener voorafgeskandeerde statiese agtergronde, en meer data-gedrewe toneelmodelleringbenaderings. Hulle hoop ook om herbeligtingsvermoëns in te sluit, a onlangse innovasie in NeRF-navorsing.
Aanspreek van beperkings van ST-NeRF
In die konteks van akademiese RW-vraestelle wat geneig is om die werklike bruikbaarheid van 'n nuwe stelsel in 'n weggooi-eindparagraaf te vermors, is selfs die beperkings wat die navorsers vir ST-NeRF erken, ongewoon.
Hulle neem waar dat die sisteem nie tans spesifieke voorwerpe in 'n toneel kan individueer en afsonderlik weergee nie, omdat die mense in die beeldmateriaal in individuele entiteite gesegmenteer word via 'n stelsel wat ontwerp is om mense te herken en nie voorwerpe nie - 'n probleem wat blykbaar maklik opgelos kan word met YOLO en soortgelyke raamwerke, met die harder werk om menslike video te onttrek wat reeds bereik is.
Alhoewel die navorsers opmerk dat dit tans nie moontlik is om stadige beweging te genereer nie, blyk dit min te verhoed dat die implementering hiervan deur bestaande innovasies in raaminterpolasie te gebruik, soos DAIN en RYF.
Soos met alle NeRF-implementerings, en in baie ander sektore van rekenaarvisie-navorsing, kan ST-NeRF misluk in gevalle van ernstige okklusie, waar die onderwerp tydelik deur 'n ander persoon of 'n voorwerp verduister word, en dit kan moeilik wees om deurlopend na te spoor of akkuraat te wees. naderhand weer aan te skaf. Soos elders, moet hierdie moeilikheid dalk stroomop-oplossings wag. Intussen gee die navorsers toe dat manuele ingryping nodig is in hierdie afgeslote rame.
Laastens neem die navorsers waar dat die menslike segmenteringsprosedures tans staatmaak op kleurverskille, wat kan lei tot onbedoelde samevoeging van twee mense in een segmentasieblok – 'n struikelblok nie beperk tot ST-NeRF nie, maar intrinsiek aan die biblioteek wat gebruik word, en wat kan dalk opgelos word deur optiese vloei-analise en ander opkomende tegnieke.
Eerste gepubliseer 7 Mei 2021.















