
Kunsmatige Intelligensie
Hoe stabiele verspreiding as 'n hoofstroomverbruikersproduk kan ontwikkel

Ironies genoeg, Stabiele diffusien, die nuwe KI-beeldsintese-raamwerk wat die wêreld met storm geneem het, is nie stabiel nie en ook nie regtig so 'verspreid' nie – ten minste, nog nie.
Die volle reeks van die stelsel se vermoëns is versprei oor 'n wisselende smorgasbord van voortdurend muterende aanbiedinge van 'n handjievol ontwikkelaars wat woes die nuutste inligting en teorieë uitruil in uiteenlopende gesprekvoering oor Discord - en die oorgrote meerderheid van die installasieprosedures vir die pakkette wat hulle skep of wysiging is baie ver van 'plug and play'.
Hulle is eerder geneig om opdragreël of BAT-gedrewe installasie via GIT, Conda, Python, Miniconda en ander bloeiende ontwikkelingsraamwerke – sagtewarepakkette so skaars onder die algemene gebruik van verbruikers dat hul installasie gereeld gemerk deur antivirus- en anti-wanware-verskaffers as bewys van 'n gekompromitteerde gasheerstelsel.

Slegs 'n klein seleksie van stadiums in die handskoen wat die standaard stabiele diffusie-installasie tans vereis. Baie van die verspreidings vereis ook spesifieke weergawes van Python, wat kan bots met bestaande weergawes wat op die gebruiker se masjien geïnstalleer is – hoewel dit vermy kan word met Docker-gebaseerde installasies en, tot 'n sekere mate, deur die gebruik van Conda-omgewings.
Boodskapdrade in beide die SFW- en NSFW-stabiele verspreidingsgemeenskappe word oorstroom met wenke en truuks wat verband hou met die inbraak van Python-skrifte en standaardinstallasies, om verbeterde funksionaliteit moontlik te maak, of om gereelde afhanklikheidsfoute en 'n reeks ander probleme op te los.
Dit laat die gemiddelde verbruiker belangstel in skep wonderlike beelde van teksaanwysings, amper aan die genade van die groeiende aantal gemonetiseerde API-webkoppelvlakke, waarvan die meeste 'n minimale aantal gratis beeldgenerasies bied voordat die aankoop van tokens vereis word.
Daarbenewens weier byna al hierdie webgebaseerde aanbiedinge om die NSFW-inhoud uit te voer (waarvan baie verband hou met nie-pornografiese onderwerpe van algemene belang, soos 'oorlog') wat Stable Diffusion onderskei van die bowdlerized dienste van OpenAI se DALL-E 2.
'Photoshop vir stabiele verspreiding'
Gelok deur die fantastiese, raserige of anderwêreldse beelde wat Twitter se #stablediffusion hashtag daagliks bevolk, waarvoor die groter wêreld waarskynlik wag, is 'Photoshop vir stabiele verspreiding' – 'n kruisplatform installeerbare toepassing wat die beste en kragtigste funksionaliteit van Stability.ai se argitektuur invou, sowel as die verskeie vernuftige innovasies van die opkomende SD-ontwikkelingsgemeenskap, sonder enige drywende CLI-vensters, obskure en voortdurend veranderende installering en opdatering roetines, of ontbrekende kenmerke.
Wat ons tans het, in die meeste van die meer bekwame installasies, is 'n verskillende elegante webblad wat deur 'n onbeliggaamde opdragreëlvenster gespan word, en waarvan die URL 'n plaaslike gasheerpoort is:

Soortgelyk aan CLI-gedrewe sintese-apps soos FaceSwap, en die BAT-gesentreerde DeepFaceLab, wys die 'prepack'-installasie van Stable Diffusion sy opdragreëlwortels, met die koppelvlak wat toeganklik is via 'n plaaslike gasheerpoort (sien bo-aan prent hierbo) wat kommunikeer met die CLI-gebaseerde Stabiele Diffusie-funksie.
Sonder twyfel kom 'n meer vaartbelynde toepassing. Daar is reeds verskeie Patreon-gebaseerde integrale toepassings wat afgelaai kan word, soos GRisk en NMKD (sien prent hieronder) – maar nie een wat nog die volle reeks kenmerke integreer wat sommige van die meer gevorderde en minder toeganklike implementerings van Stable Diffusion kan bied nie.

Vroeë, Patreon-gebaseerde pakkette van stabiele diffusie, liggies 'app-gevorm'. NMKD's is die eerste om die CLI-uitset direk in die GUI te integreer.
Kom ons kyk na hoe 'n meer gepoleerde en integrale implementering van hierdie verstommende oopbronwonder uiteindelik kan lyk – en watter uitdagings dit in die gesig staar.
Regsoorwegings vir 'n volledig-befondsde kommersiële stabiele verspreidingsaansoek
Die NSFW-faktor
Die Stable Diffusion bronkode is vrygestel onder 'n uiters permissiewe lisensie wat nie kommersiële herimplementerings en afgeleide werke wat omvattend uit die bronkode bou, verbied nie.
Behalwe die voorgenoemde en groeiende aantal Patreon-gebaseerde Stable Diffusion builds, sowel as die uitgebreide aantal toepassings-inproppe wat ontwikkel word vir figma, kryt, Photoshop, GIMP, en Blender (onder andere), is daar geen praktiese rede waarom 'n goed befondsde sagteware-ontwikkelingshuis nie 'n veel meer gesofistikeerde en bekwame Stable Diffusion-toepassing kon ontwikkel nie. Vanuit 'n markperspektief is daar alle rede om te glo dat verskeie sulke inisiatiewe reeds goed op dreef is.
Hier staar sulke pogings onmiddellik voor die dilemma te staan of die toepassing, soos die meeste web-API's vir Stable Diffusion, Stable Diffusion se inheemse NSFW-filter ('n fragment van kode), afgeskakel te word.
'Begrawe' die NSFW-skakelaar
Alhoewel Stability.ai se oopbronlisensie vir Stable Diffusion 'n wyd interpreteerbare lys van toepassings bevat waarvoor dit moontlik is. nie gebruik word (waarskynlik insluitend pornografiese inhoud en deepfakes), die enigste manier waarop 'n verkoper sulke gebruik effektief kan verbied, is om die NSFW-filter saam te stel in 'n ondeursigtige uitvoerbare in plaas van 'n parameter in 'n Python-lêer, of anders 'n kontrolesomvergelyking af te dwing op die Python-lêer of DLL wat die NSFW-aanwysing bevat, sodat weergawes nie kan plaasvind as gebruikers hierdie instelling verander nie.
Dit sal die vermeende aansoek 'gekastreer' laat op baie dieselfde manier as wat DALL-E 2 is tans, wat sy kommersiële aantrekkingskrag verminder. Ook onvermydelik sal gedekompileerde 'gedokterde' weergawes van hierdie komponente (óf oorspronklike Python-looptydelemente óf saamgestelde DLL-lêers, soos nou gebruik word in die Topaz-reeks van AI-beeldverbeteringsnutsmiddels) waarskynlik in die torrent-/hacking-gemeenskap verskyn om sulke beperkings te ontsluit , bloot deur die belemmerende elemente te vervang en enige kontrolesomvereistes te ontken.
Op die ou end kan die verkoper kies om bloot Stability.ai se waarskuwing teen misbruik wat die eerste lopie van baie huidige Stable Diffusion-verspreidings kenmerk, te herhaal.
Die klein oopbron-ontwikkelaars wat tans op hierdie manier toevallige vrywarings gebruik, het egter min om te verloor in vergelyking met 'n sagtewaremaatskappy wat aansienlike hoeveelhede tyd en geld belê het om Stable Diffusion volledig en toeganklik te maak - wat dieper oorweging nodig het.
Deepfake aanspreeklikheid
Soos ons het onlangs opgemerk, die LAION-estetika-databasis, deel van die 4.2 biljoen beelde waarop Stable Diffusion se deurlopende modelle opgelei is, bevat 'n groot aantal bekende beelde, wat gebruikers in staat stel om effektief diepvals te skep, insluitend diepvalse beroemdheidpornografie.

Uit ons onlangse artikel, vier stadiums van Jennifer Connelly oor vier dekades van haar loopbaan, afgelei van Stable Diffusion.
Dit is 'n aparte en meer omstrede kwessie as die generering van (gewoonlik) wettige 'abstrakte' pornografie, wat nie 'regte' mense uitbeeld nie (hoewel sulke beelde afgelei word uit verskeie regte foto's in die opleidingsmateriaal).
Aangesien 'n toenemende aantal Amerikaanse state en lande wette teen vervalste pornografie ontwikkel of ingestel het, kan Stable Diffusion se vermoë om bekende pornografie te skep beteken dat 'n kommersiële toepassing wat nie heeltemal gesensor is nie (dws wat pornografiese materiaal kan skep) dalk nog 'n paar nodig het. vermoë om waargenome celebrity gesigte te filter.
Een metode sou wees om 'n ingeboude 'swartlys' van terme te verskaf wat nie in 'n gebruikersporboodskap aanvaar sal word nie, wat verband hou met name van bekendes en met fiktiewe karakters waarmee hulle geassosieer kan word. Vermoedelik sal sulke instellings in meer tale as net Engels ingestel moet word, aangesien die oorspronklike data ander tale bevat. Nog 'n benadering kan wees om celebrity-herkenningstelsels soos dié wat deur Clarifai ontwikkel is, in te sluit.
Dit mag nodig wees vir sagtewarevervaardigers om sulke metodes in te sluit, miskien aanvanklik afgeskakel, wat kan help om te verhoed dat 'n volwaardige selfstandige Stable Diffusion-toepassing bekende gesigte genereer, hangende nuwe wetgewing wat sulke funksionaliteit onwettig kan maak.
Weereens kon sulke funksionaliteit egter onvermydelik deur belanghebbende partye gedekompileer en omgekeer word; die sagtewarevervaardiger kan egter, in daardie geval, beweer dat dit effektief ongekeurde vandalisme is – solank hierdie soort omgekeerde ingenieurswese nie buitensporig maklik gemaak word nie.
Kenmerke wat ingesluit kan word
Die kernfunksies in enige verspreiding van Stabiele Diffusie sal van enige goed befondsde kommersiële toepassing verwag word. Dit sluit in die vermoë om teksaanwysings te gebruik om toepaslike beelde te genereer (teks-na-beeld); die vermoë om sketse of ander prente te gebruik as riglyne vir nuwe gegenereerde beelde (beeld-tot-beeld); die middele om aan te pas hoe 'verbeeldingryk' die stelsel opdrag gegee word om te wees; 'n manier om leweringstyd teen kwaliteit af te wissel; en ander 'basiese beginsels', soos opsionele outomatiese beeld-/spoedargivering, en roetine-opsionele opskaling via RealESRGAN, en ten minste basiese 'face fixing' met GFPGAN or CodeFormer.
Dit is 'n mooi 'vanielje-installasie'. Kom ons kyk na sommige van die meer gevorderde kenmerke wat tans ontwikkel of uitgebrei word, wat in 'n volwaardige 'tradisionele' Stabiele Diffusion-toepassing geïnkorporeer kan word.
Stogastiese bevriesing
Al is jy hergebruik 'n saad van 'n vorige suksesvolle weergawe, is dit verskriklik moeilik om Stabiele Diffusie te kry om 'n transformasie akkuraat te herhaal as enige onderdeel van die prompt of die bronbeeld (of albei) word verander vir 'n daaropvolgende weergawe.
Dit is 'n probleem as jy wil gebruik EbSynth om Stable Diffusion se transformasies op 'n tydelike samehangende manier op regte video af te dwing – hoewel die tegniek baie effektief kan wees vir eenvoudige kop-en-skouers skote:

Beperkte beweging kan EbSynth 'n effektiewe medium maak om Stabiele Diffusion-transformasies in realistiese video te omskep. Bron: https://streamable.com/u0pgzd
EbSynth werk deur 'n klein seleksie van 'veranderde' sleutelrame te ekstrapoleer na 'n video wat in 'n reeks beeldlêers weergegee is (en wat later weer in 'n video saamgevoeg kan word).

In hierdie voorbeeld van die EbSynth-werf is 'n klein handjievol rame van 'n video op 'n artistieke wyse geverf. EbSynth gebruik hierdie rame as stylgidse om die hele video op soortgelyke wyse te verander sodat dit by die geverfde styl pas. Bron: https://www.youtube.com/embed/eghGQtQhY38
In die voorbeeld hieronder, wat byna geen beweging van die (regte) blonde joga-instrukteur aan die linkerkant vertoon nie, sukkel Stable Diffusion steeds om 'n konsekwente gesig te handhaaf, omdat die drie beelde wat as 'sleutelrame' getransformeer word, nie heeltemal identies is nie, selfs al deel hulle almal dieselfde numeriese saad.

Hier, selfs met dieselfde vinnige en saad oor al drie transformasies, en baie min veranderinge tussen die bronrame, verskil die liggaamspiere in grootte en vorm, maar meer belangrik, die gesig is inkonsekwent, wat tydelike konsekwentheid in 'n potensiële EbSynth-weergawe belemmer.
Alhoewel die SD/EbSynth-video hieronder baie vindingryk is, waar die gebruiker se vingers omskep is in (onderskeidelik) 'n wandelende paar broekbene en 'n eend, tipeer die inkonsekwentheid van die broek die probleem wat Stabiele Diffusion het om konsekwentheid oor verskillende sleutelrame te handhaaf , selfs wanneer die bronrame soortgelyk aan mekaar is en die saad konsekwent is.

'n Man se vingers word 'n wandelende man en 'n eend, via Stable Diffusion en EbSynth. Bron: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
Die gebruiker wat hierdie video geskep het kommentaar dat die eendtransformasie, waarskynlik die doeltreffender van die twee, indien minder treffend en oorspronklik, slegs 'n enkele getransformeerde sleutelraam vereis het, terwyl dit nodig was om 50 stabiele diffusiebeelde weer te gee om die loopbroek te skep, wat meer tydelik vertoon. inkonsekwentheid. Die gebruiker het ook opgemerk dat dit vyf pogings geneem het om konsekwentheid vir elk van die 50 sleutelrame te bereik.
Daarom sal dit 'n groot voordeel wees vir 'n werklik omvattende Stabiele Diffusion-toepassing om funksionaliteit te verskaf wat kenmerke tot die maksimum mate oor sleutelrame behou.
Een moontlikheid is dat die toepassing die gebruiker toelaat om die stogastiese enkode vir die transformasie op elke raam te 'vries', wat tans slegs bereik kan word deur die bronkode handmatig te wysig. Soos die voorbeeld hieronder toon, help dit tydelike konsekwentheid, hoewel dit dit beslis nie oplos nie:

Een Reddit-gebruiker het webcam-beeldmateriaal van homself in verskillende bekende mense omskep deur nie net die saad te volhard nie (wat enige implementering van Stable Diffusion kan doen), maar deur te verseker dat die stochastic_encode() parameter identies was in elke transformasie. Dit is bereik deur die kode te wysig, maar kan maklik 'n gebruiker-toeganklike skakelaar word. Dit is egter duidelik dat dit nie al die tydelike kwessies oplos nie. Bron: https://old.reddit.com/r/StableDiffusion/comments/wyeoqq/turning_img2img_into_vid2vid/
Wolk-gebaseerde tekstuele inversie
'n Beter oplossing om tydelik konsekwente karakters en voorwerpe te ontlok, is om hulle te 'bak' in 'n Tekstuele inversie – 'n 5KB-lêer wat binne 'n paar uur opgelei kan word, gebaseer op net vyf geannoteerde beelde, wat dan deur 'n spesiale '*' vinnig, wat byvoorbeeld 'n aanhoudende verskyning van romankarakters moontlik maak vir insluiting in 'n vertelling.

Beelde wat met toepaslike merkers geassosieer word, kan deur middel van teksomkering in diskrete entiteite omgeskakel word, en sonder dubbelsinnigheid, en in die korrekte konteks en styl, deur spesiale tekenwoorde opgeroep word. Bron: https://huggingface.co/docs/diffusers/training/text_inversion
Tekstuele inversies is bykomende lêers tot die baie groot en volledig opgeleide model wat Stable Diffusion gebruik, en word effektief 'gegly' in die ontlokings-/aansporingsproses, sodat hulle kan deel te neem in model-afgeleide tonele, en trek voordeel uit die model se enorme databasis van kennis oor voorwerpe, style, omgewings en interaksies.
Alhoewel 'n Tekstuele Inversie nie lank neem om op te lei nie, benodig dit 'n groot hoeveelheid VRAM; volgens verskeie huidige deurlopers, iewers tussen 12, 20 en selfs 40GB.
Aangesien dit onwaarskynlik is dat die meeste toevallige gebruikers daardie soort GPU-krag tot hul beskikking sal hê, is wolkdienste reeds besig om die operasie te hanteer, insluitend 'n Hugging Face-weergawe. Al is daar Google Colab-implementerings wat tekstuele inversies vir stabiele verspreiding kan skep, kan die vereiste VRAM- en tydvereistes dit uitdagend maak vir gratis-vlak Colab-gebruikers.
Vir 'n potensiële volskaalse en goed-belêde Stable Diffusion (geïnstalleerde) toepassing, lyk dit asof hierdie swaar taak na die maatskappy se wolkbedieners deurgee 'n voor die hand liggende monetiseringstrategie is (aangeneem dat 'n lae of geen-koste Stable Diffusion-toepassing deurspek is met sulke nie- gratis funksionaliteit, wat waarskynlik in baie moontlike toepassings lyk wat in die volgende 6-9 maande uit hierdie tegnologie sal voortspruit).
Boonop kan die taamlik ingewikkelde proses van annotasie en formatering van die ingestuurde beelde en teks baat by outomatisering in 'n geïntegreerde omgewing. Die potensiële 'verslawende faktor' om unieke elemente te skep wat die uitgestrekte wêrelde van Stabiele Diffusion kan verken en daarmee in wisselwerking kan tree, lyk potensieel kompulsief, beide vir algemene entoesiaste en jonger gebruikers.
Veelsydige vinnige gewig
Daar is baie huidige implementerings wat die gebruiker toelaat om groter klem te gee aan 'n gedeelte van 'n lang teksopdrag, maar die instrumentaliteit wissel nogal baie tussen hierdie, en is dikwels lomp of onintuïtief.
Die baie gewilde Stable Diffusion vurk deur AUTOMATIC1111, byvoorbeeld, kan die waarde van 'n promptwoord verlaag of verhoog deur dit in enkel- of veelvuldige hakies (vir ontklemtoning) of vierkantige hakies vir ekstra klem te plaas.

Vierkante hakies en/of hakies kan jou ontbyt verander in hierdie weergawe van Stabiele Diffusie vinnige gewigte, maar dit is in elk geval 'n cholesterol-nagmerrie.
Ander iterasies van Stable Diffusion gebruik uitroeptekens vir beklemtoning, terwyl die mees veelsydige gebruikers toelaat om gewigte aan elke woord toe te ken in die prompt deur die GUI.
Die stelsel moet ook voorsiening maak vir negatiewe vinnige gewigte – nie net vir gruwel aanhangers, maar omdat daar dalk minder kommerwekkende en meer opbouende raaisels in Stable Diffusion se latente ruimte is as wat ons beperkte taalgebruik kan oproep.
Uitverf
Kort ná die opspraakwekkende open source van Stable Diffusion het OpenAI – grootliks tevergeefs – probeer om van sy DALL-E 2-donderweer terug te wen deur aankondiging 'outpainting', wat 'n gebruiker toelaat om 'n beeld buite sy grense uit te brei met semantiese logika en visuele samehang.
Natuurlik was dit sedertdien geïmplementeer in verskeie vorme vir Stabiele Diffusie, asook in Krita, en moet beslis ingesluit word in 'n omvattende, Photoshop-styl weergawe van Stable Diffusion.
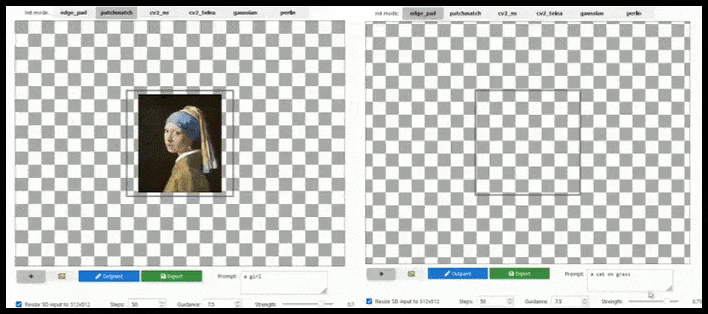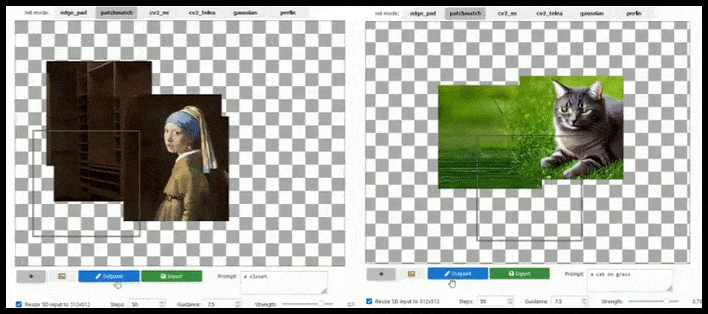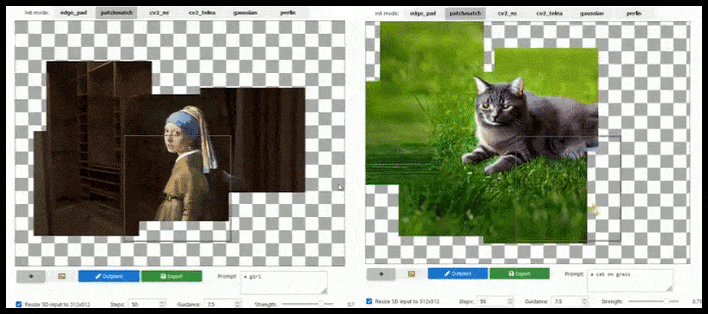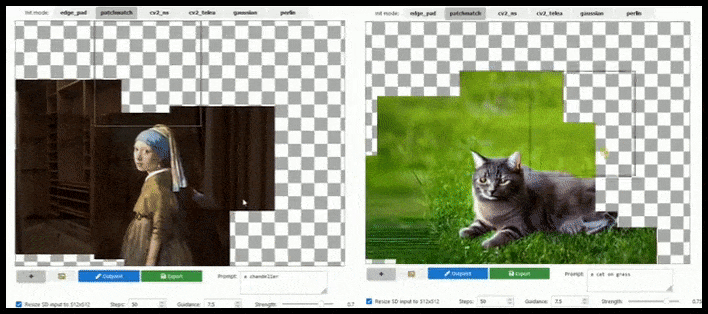
Teëlgebaseerde aanvulling kan 'n standaard 512 × 512-weergawe byna oneindig uitbrei, solank die opdragte, bestaande beeld en semantiese logika dit toelaat. Bron: https://github.com/lkwq007/stablediffusion-infinity
Omdat Stabiele Diffusie opgelei word op 512x512px-beelde (en vir 'n verskeidenheid ander redes), sny dit gereeld die koppe (of ander noodsaaklike liggaamsdele) van menslike proefpersone af, selfs waar die prompt duidelik 'kopbeklemtoning', ens.

Tipiese voorbeelde van 'onthoofding' van stabiele diffusie; maar uitverf kan George weer in die prentjie plaas.
Enige uitverf-implementering van die tipe wat in die geanimeerde prent hierbo geïllustreer word (wat uitsluitlik op Unix-biblioteke gebaseer is, maar moet in staat wees om op Windows gerepliseer te word) moet ook as 'n een-klik/spoedige oplossing hiervoor gebruik word.
Tans brei 'n aantal gebruikers die doek van 'onthoofde' uitbeeldings uit na bo, vul die koparea rofweg in en gebruik img2img om die vervalste weergawe te voltooi.
Effektiewe maskering wat konteks verstaan
maskering kan 'n vreeslike tref-en-mis-affêre in Stable Diffusion wees, afhangend van die vurk of weergawe ter sprake. Dikwels, waar dit moontlik is om enigsins 'n samehangende masker te teken, word die gespesifiseerde area uiteindelik geverf met inhoud wat nie die hele konteks van die prent in ag neem nie.
By een geleentheid het ek die korneas van 'n gesigbeeld gemasker en die opdrag gegee 'blou oë' as 'n masker inverf - net om te vind dat dit gelyk het of ek deur twee uitgesnyde menslike oë na 'n veraf prentjie van 'n onaards-lykende wolf kyk. Ek dink ek is gelukkig dat dit nie Frank Sinatra was nie.
Semantiese redigering is ook moontlik deur die geraas te identifiseer wat die prent in die eerste plek gekonstrueer het, wat die gebruiker in staat stel om spesifieke strukturele elemente in 'n weergawe aan te spreek sonder om met die res van die prent in te meng:

Die verandering van een element in 'n prent sonder tradisionele maskering en sonder om aangrensende inhoud te verander, deur die geraas te identifiseer wat die prent eerste ontstaan het en die dele daarvan aan te spreek wat tot die teikenarea bygedra het. Bron: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Hierdie metode is gebaseer op die K-diffusie monsternemer.
Semantiese filters vir fisiologiese goofs
Soos ons al voorheen genoem het, kan Stable Diffusion gereeld ledemate byvoeg of aftrek, grootliks as gevolg van datakwessies en tekortkominge in die aantekeninge wat die beelde vergesel wat dit opgelei het.

Net soos daardie dwalende kind wat sy tong uitgesteek het in die skoolgroepfoto, is Stable Diffusion se biologiese gruweldade nie altyd onmiddellik voor die hand liggend nie, en jy het dalk jou nuutste KI-meesterstuk op Instagram ge-Instagram voordat jy die ekstra hande of gesmelte ledemate opmerk.
Dit is so moeilik om hierdie soort foute reg te stel dat dit nuttig sal wees as 'n volgrootte Stabiele Diffusie-toepassing 'n soort anatomiese herkenningstelsel bevat wat semantiese segmentering gebruik om te bereken of die inkomende prent ernstige anatomiese tekortkominge het (soos in die prent hierbo) ), en gooi dit weg ten gunste van 'n nuwe weergawe voordat dit aan die gebruiker aangebied word.

Natuurlik wil jy dalk die godin Kali, of Doctor Octopus, weergee, of selfs 'n onaangeraakte gedeelte van 'n ledemaat-geteisterde prentjie red, so hierdie kenmerk moet 'n opsionele skakelaar wees.
As gebruikers die telemetrie-aspek kan verdra, kan sulke foute selfs anoniem oorgedra word in 'n kollektiewe poging van federatiewe leer wat toekomstige modelle kan help om hul begrip van anatomiese logika te verbeter.
LAION-gebaseerde outomatiese gesigverbetering
Soos ek opgemerk het in my vorige kyk by drie dinge wat Stable Diffusion in die toekoms kan aanspreek, moet dit nie uitsluitlik aan enige weergawe van GFPGAN oorgelaat word om te probeer om gelewerde gesigte in eerste-instansie-weergawes te 'verbeter' nie.
GFPGAN se 'verbeterings' is verskriklik generies, ondermyn gereeld die identiteit van die individu wat uitgebeeld word, en werk slegs op 'n gesig wat gewoonlik swak weergegee is, aangesien dit nie meer verwerkingstyd of aandag gekry het as enige ander deel van die prent nie.
Daarom moet 'n professionele standaardprogram vir stabiele verspreiding 'n gesig (met 'n standaard en relatief liggewig biblioteek soos YOLO) kan herken, die volle gewig van beskikbare GPU-krag kan toepas om dit weer te gee, en óf die verbeterde gesig in te meng die oorspronklike volkonteks-weergawe, of stoor dit afsonderlik vir handmatige hersamestelling. Tans is dit 'n redelike 'hands on'-operasie.
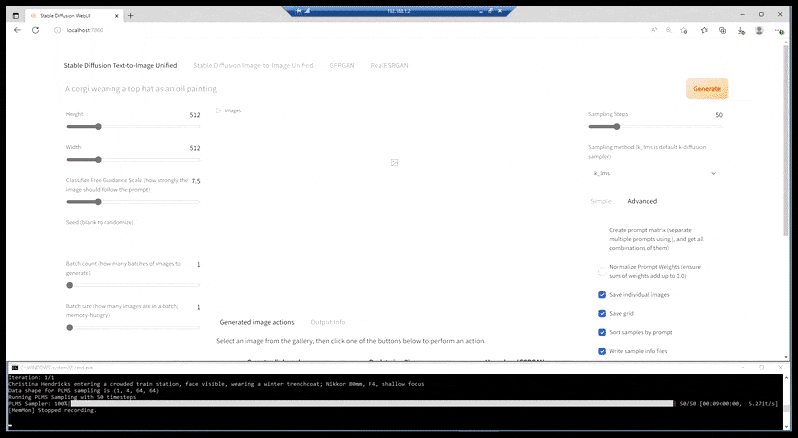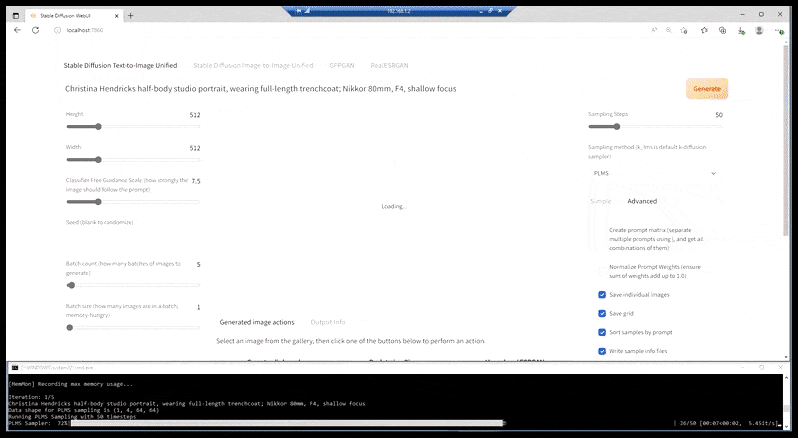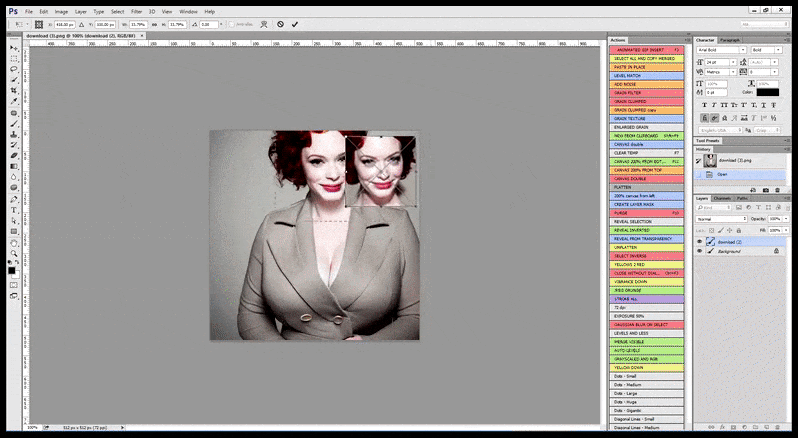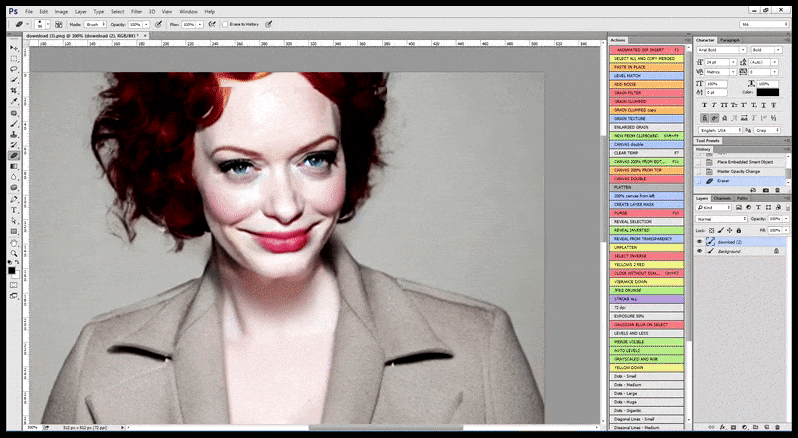
In gevalle waar Stabiele Diffusion opgelei is op 'n voldoende aantal beelde van 'n bekende persoon, is dit moontlik om die hele GPU-kapasiteit te fokus op 'n daaropvolgende weergawe slegs van die gesig van die gelewerde beeld, wat gewoonlik 'n noemenswaardige verbetering is - en, anders as GFPGAN , gebruik inligting van LAION-opgeleide data, eerder as om bloot die gelewerde pixels aan te pas.
In-App LAION Soektogte
Sedert gebruikers begin besef het dat die deursoeking van LAION se databasis vir konsepte, mense en temas 'n hulp kan wees vir beter gebruik van Stable Diffusion, is verskeie aanlyn LAION-ontdekkingsreisigers geskep, insluitend haveibeentrained.com.

Die soekfunksie by haveibeentrained.com laat gebruikers die beelde verken wat Stable Diffusion aandryf, en ontdek of voorwerpe, mense of idees wat hulle dalk uit die stelsel wil ontlok waarskynlik daarin opgelei is. Sulke stelsels is ook nuttig om aangrensende entiteite te ontdek, soos die manier waarop bekendes gegroepeer word, of die 'volgende idee' wat voortspruit uit die huidige een. Bron: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Alhoewel sulke webgebaseerde databasisse dikwels sommige van die etikette openbaar wat die beelde vergesel, is die proses van veralgemening wat tydens modelopleiding plaasvind, beteken dat dit onwaarskynlik is dat enige spesifieke beeld opgeroep kan word deur sy merker as 'n aansporing te gebruik.
Daarbenewens, die verwydering van 'stop woorde' en die praktyk van stemming en lemmatisering in Natuurlike Taalverwerking beteken dat baie van die frases wat vertoon is, opgedeel of weggelaat is voordat dit in Stabiele Diffusie opgelei is.
Nietemin, die manier waarop estetiese groeperings in hierdie koppelvlakke saambind, kan die eindgebruiker baie leer oor die logika (of, ongetwyfeld, die 'persoonlikheid') van Stable Diffusion, en 'n hulpmiddel vir beter beeldproduksie bewys.
Gevolgtrekking
Daar is baie ander kenmerke wat ek graag wil sien in 'n volledige inheemse lessenaar-implementering van Stable Diffusion, soos inheemse CLIP-gebaseerde beeldanalise, wat die standaard Stable Diffusion-proses omkeer en die gebruiker toelaat om frases en woorde te ontlok wat die stelsel sal natuurlik assosieer met die bronbeeld, of die weergawe.
Boonop sal ware teëlgebaseerde skaal 'n welkome toevoeging wees, aangesien ESRGAN amper so stomp 'n instrument is as GFPGAN. Gelukkig planne om die te integreer txt2imghd implementering van GOBIG maak dit vinnig 'n werklikheid oor die verspreidings heen, en dit lyk na 'n voor die hand liggende keuse vir 'n tafelrekenaar-iterasie.
Sommige ander gewilde versoeke van die Discord-gemeenskappe interesseer my minder, soos geïntegreerde vinnige woordeboeke en toepaslike lyste van kunstenaars en style, hoewel 'n inprogram-notaboek of aanpasbare leksikon van frases 'n logiese toevoeging lyk.
Net so bly die huidige beperkings van mensgesentreerde animasie in Stable Diffusion, alhoewel dit deur CogVideo en verskeie ander projekte begin is, ongelooflik ontluikend, en aan die genade van stroomopnavorsing oor tydelike prioriteite wat verband hou met outentieke menslike beweging.
Vir nou is 'n stabiele verspreidingsvideo streng psychedelic, alhoewel dit 'n baie beter nabye toekoms kan hê in diepvals poppespel, via EbSynth en ander relatief ontluikende teks-na-video-inisiatiewe (en dit is opmerklik die gebrek aan gesintetiseerde of 'veranderde' mense in Runway's nuutste promosie video).
Nog 'n waardevolle funksionaliteit sal deursigtige Photoshop-deurlaat wees, wat lank reeds in Cinema4D se tekstuurredigeerder gevestig is, onder ander soortgelyke implementerings. Hiermee kan 'n mens beelde maklik tussen toepassings skuif en elke toepassing gebruik om die transformasies uit te voer waarmee dit uitblink.
Ten slotte, en miskien die belangrikste, moet 'n volledige lessenaar Stable Diffusion-program nie net maklik tussen kontrolepunte kan ruil nie (dws weergawes van die onderliggende model wat die stelsel aandryf), maar moet ook in staat wees om pasgemaakte Tekstuele Inversies wat gewerk het, op te dateer met vorige amptelike modelvrystellings, maar kan andersins gebreek word deur latere weergawes van die model (soos ontwikkelaars by die amptelike Discord aangedui het, kan die geval wees).
Ironies genoeg het die organisasie in die heel beste posisie om so 'n kragtige en geïntegreerde matriks van gereedskap vir Stable Diffusion te skep, Adobe, homself so sterk aan die Inisiatief vir egtheid van inhoud dat dit dalk 'n retrograde PR-dwaling vir die maatskappy kan lyk – tensy dit was om Stable Diffusion se generatiewe kragte so deeglik te hobbel as wat OpenAI met DALL-E 2 gedoen het, en dit eerder as 'n natuurlike evolusie van sy aansienlike belange in voorraadfotografie te posisioneer.
Eerste gepubliseer 15 September 2022.















