
Kunsmatige Intelligensie
Drie uitdagings wat voorlê vir stabiele verspreiding

Die vrystel van stabiliteit.ai se stabiele verspreiding latente diffusie beeldsintese-model 'n paar weke gelede kan een van die belangrikste tegnologiese onthullings wees sedert DeCSS in 1999; dit is beslis die grootste gebeurtenis in KI-gegenereerde beelde sedert die 2017 deepfakes kode is na GitHub gekopieer en ingevurk in wat sou word DeepFaceLab en gesig ruil, sowel as die real-time streaming deepfake sagteware DeepFaceLive.
Met 'n slag, gebruikers frustrasie oor die inhoudsbeperkings in DALL-E 2 se beeldsintese-API is eenkant toe gevee, aangesien dit geblyk het dat Stable Diffusion se NSFW-filter gedeaktiveer kan word deur 'n enigste reël kode. Porno-gesentreerde Stable Diffusion Reddits het byna onmiddellik ontstaan, en is so vinnig afgekap, terwyl die ontwikkelaar- en gebruikerskamp op Discord in die amptelike en NSFW-gemeenskappe verdeel het, en Twitter begin vol word met fantastiese Stable Diffusion-skeppings.
Op die oomblik lyk dit of elke dag ongelooflike innovasie bring van die ontwikkelaars wat die stelsel aangeneem het, met inproppe en derdeparty-byvoegsels wat inderhaas geskryf word vir kryt, Photoshop, Cinema4D, Blender, en baie ander toepassingsplatforms.

In die tussentyd, promptwerk – die nou professionele kuns van 'KI-fluistering', wat dalk die kortste loopbaanopsie sedert 'Filofax binder' kan wees – word reeds gekommersialiseer, terwyl vroeë monetisering van Stabiele Diffusie plaasvind by die Patreon vlak, met die sekerheid van meer gesofistikeerde aanbiedings wat kom, vir diegene wat nie wil navigeer nie Conda-gebaseer installasies van die bronkode, of die proskriptiewe NSFW-filters van webgebaseerde implementerings.
Die tempo van ontwikkeling en vrye gevoel van verkenning van gebruikers vorder teen so 'n duiselingwekkende spoed dat dit moeilik is om baie ver vooruit te sien. In wese weet ons nog nie presies waarmee ons te doen het nie, of wat al die beperkinge of moontlikhede kan wees nie.
Kom ons kyk nietemin na drie van wat die interessantste en uitdagendste struikelblokke kan wees vir die vinnig gevormde en vinnig groeiende Stabiele Diffusie-gemeenskap om die hoof te bied en, hopelik, te oorkom.
1: Optimalisering van teëlgebaseerde pyplyne
Aangebied met beperkte hardewarehulpbronne en harde beperkings op die resolusie van opleidingsbeelde, lyk dit waarskynlik dat ontwikkelaars oplossings sal vind om beide die kwaliteit en die resolusie van Stabiele Diffusie-uitset te verbeter. Baie van hierdie projekte behels die ontginning van die beperkings van die stelsel, soos die oorspronklike resolusie van slegs 512 × 512 pixels.
Soos altyd die geval is met rekenaarvisie en beeldsintese-inisiatiewe, is Stable Diffusion opgelei op vierkantige verhouding beelde, in hierdie geval hermonster na 512×512, sodat die bronbeelde gereguleer kan word en kan inpas by die beperkings van die GPU's wat het die model opgelei.
Daarom 'dink' Stabiele Diffusie (as dit enigsins dink) in 512×512 terme, en beslis in vierkante terme. Baie gebruikers wat tans die grense van die stelsel ondersoek, rapporteer dat stabiele verspreiding die mees betroubare en minste foutiewe resultate lewer teen hierdie taamlik beperkte aspekverhouding (sien 'aanspreek ledemate' hieronder).
Alhoewel verskeie implementerings opskaling via RealESRGAN (en kan swak gelewerde gesigte regmaak via GFPGAN) verskeie gebruikers is tans besig om metodes te ontwikkel om beelde in 512x512px-afdelings op te deel en die beelde aanmekaar te heg om groter saamgestelde werke te vorm.

Hierdie 1024×576-weergawe, 'n resolusie wat gewoonlik onmoontlik is in 'n enkele Stabiele Diffusion-weergawe, is geskep deur die aandag.py Python-lêer te kopieer en te plak vanaf die DoggettX vurk van Stable Diffusion ('n weergawe wat teëlgebaseerde opskaling implementeer) in 'n ander vurk. Bron: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Alhoewel sommige inisiatiewe van hierdie soort oorspronklike kode of ander biblioteke gebruik, is die txt2imghd-poort van GOBIG ('n modus in die VRAM-honger ProgRockDiffusion) is ingestel om hierdie funksionaliteit binnekort aan die hooftak te verskaf. Terwyl txt2imghd 'n toegewyde hawe van GOBIG is, behels ander pogings van gemeenskapsontwikkelaars verskillende implementerings van GOBIG.

'n Gerieflik abstrakte prent in die oorspronklike 512x512px-weergawe (links en tweede van links); opgeskaal deur ESGRAN, wat nou min of meer inheems is oor alle Stabiele Diffusie-verspreidings; en 'spesiale aandag' gegee deur 'n implementering van GOBIG, wat detail produseer wat, ten minste binne die grense van die beeldafdeling, beter opgeskaal lyk. Sons: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Die soort abstrakte voorbeeld hierbo het baie 'klein koninkryke' van detail wat by hierdie solipsistiese benadering tot opskaling pas, maar wat dalk meer uitdagende kodegedrewe oplossings vereis om nie-herhalende, samehangende opskaling te produseer wat nie kyk asof dit uit baie dele saamgestel is. Nie die minste nie, in die geval van menslike gesigte, waar ons buitengewoon ingestel is op afwykings of 'skot' artefakte. Daarom kan gesigte uiteindelik 'n toegewyde oplossing benodig.
Stabiele Diffusie het tans geen meganisme om aandag op die gesig te fokus tydens 'n weergawe op dieselfde manier as wat mense gesiginligting prioritiseer nie. Alhoewel sommige ontwikkelaars in die Discord-gemeenskappe metodes oorweeg om hierdie soort 'versterkte aandag' te implementeer, is dit tans baie makliker om die gesig handmatig (en uiteindelik outomaties) te verbeter nadat die aanvanklike weergawe plaasgevind het.
'n Menslike gesig het 'n interne en volledige semantiese logika wat nie in 'n 'teël' van die onderste hoek van (byvoorbeeld) 'n gebou gevind sal word nie, en daarom is dit tans moontlik om baie effektief 'in te zoem' en 'n weer te gee. 'sketsagtige' gesig in stabiele diffusie-uitset.

Links, Stable Diffusion se aanvanklike poging met die vinnige 'Vollengte-kleurfoto van Christina Hendricks wat 'n stampvol plek binnegaan, met 'n reënjas aan; Canon50, oogkontak, hoë detail, hoë gesigsdetail'. Regs, 'n verbeterde gesig verkry deur die vaag en sketsagtige gesig vanaf die eerste weergawe terug te voer na die volle aandag van Stable Diffusion met behulp van Img2Img (sien geanimeerde prente hieronder).
In die afwesigheid van 'n toegewyde Tekstuele Inversie-oplossing (sien hieronder), sal dit net werk vir celebrity-beelde waar die betrokke persoon reeds goed verteenwoordig is in die LAION-datasubstelle wat Stabiele Diffusion opgelei het. Daarom sal dit werk op mense soos Tom Cruise, Brad Pitt, Jennifer Lawrence, en 'n beperkte reeks ware media-ligte wat in groot getalle beelde in die brondata voorkom.
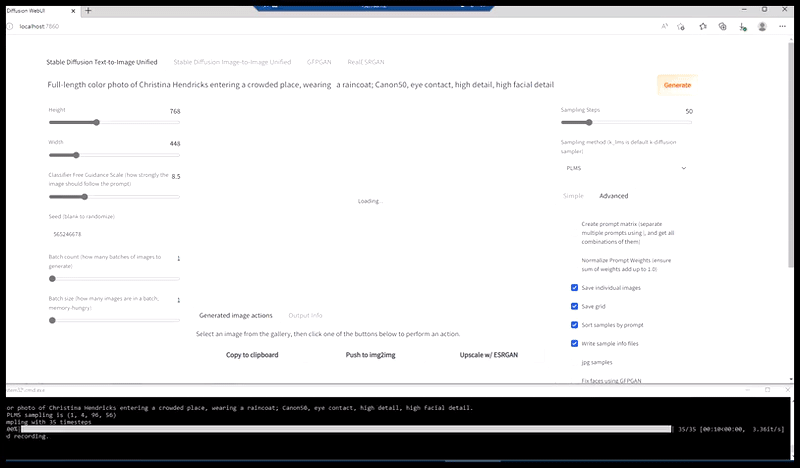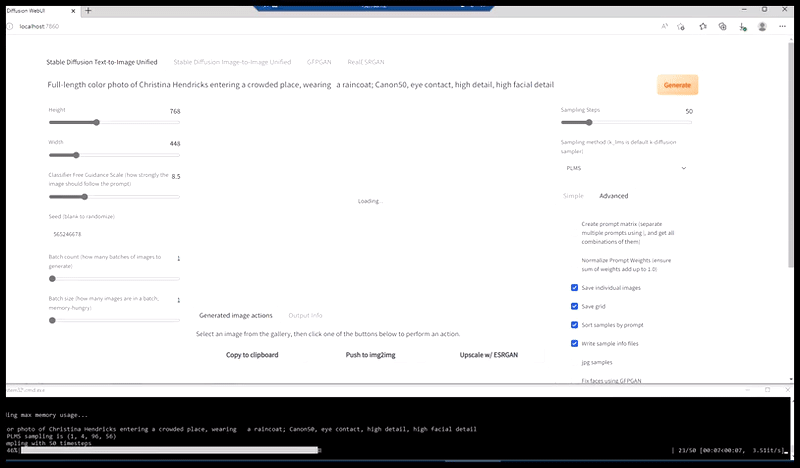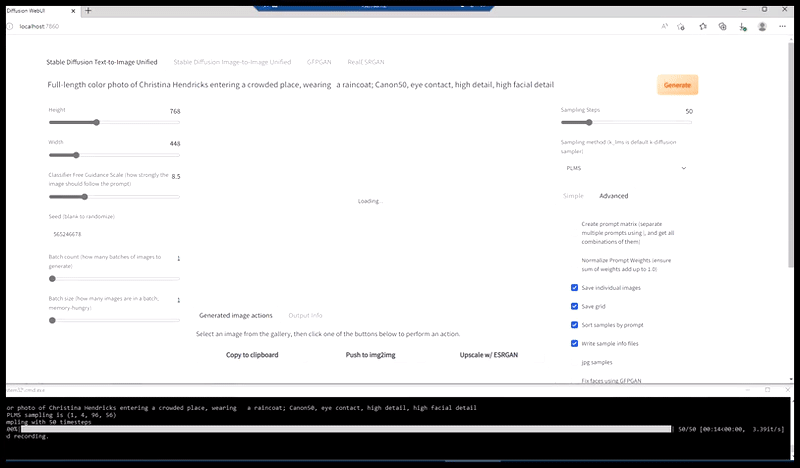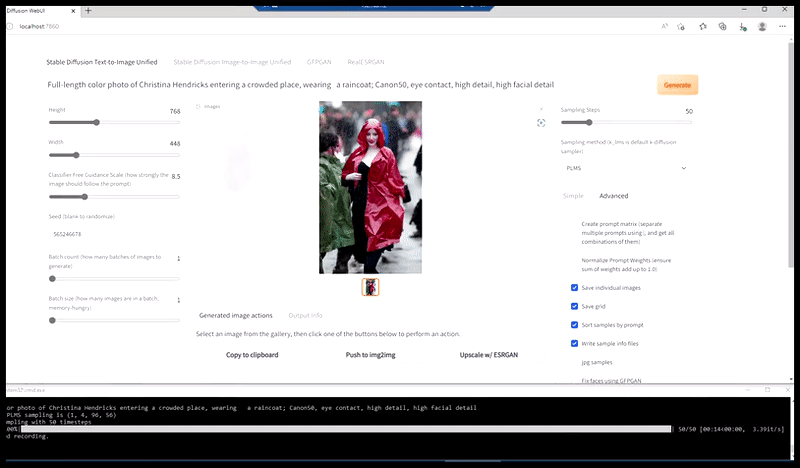
Genereer 'n geloofwaardige persprent met die vinnige 'Vollengte-kleurfoto van Christina Hendricks wat 'n stampvol plek binnegaan, met 'n reënjas; Canon50, oogkontak, hoë detail, hoë gesigsdetail'.
Vir bekendes met lang en blywende loopbane sal Stable Diffusion gewoonlik 'n beeld van die persoon op 'n onlangse (dws ouer) ouderdom genereer, en dit sal nodig wees om vinnige byvoegsels by te voeg, soos bv. 'jonk' or 'in die jaar [YEAR]' ten einde beelde wat jonger lyk te produseer.

Met 'n prominente, baie gefotografeerde en konsekwente loopbaan wat byna 40 jaar strek, is die aktrise Jennifer Connelly een van 'n handjievol bekendes in LAION wat Stable Diffusion toelaat om 'n verskeidenheid ouderdomme te verteenwoordig. Bron: prepack Stable Diffusion, local, v1.4 kontrolepunt; ouderdomverwante aanwysings.
Dit is grootliks as gevolg van die verspreiding van digitale (eerder as duur, emulsie-gebaseerde) persfotografie vanaf die middel van die 2000's, en die latere groei in volume van beelduitset as gevolg van verhoogde breëbandspoed.
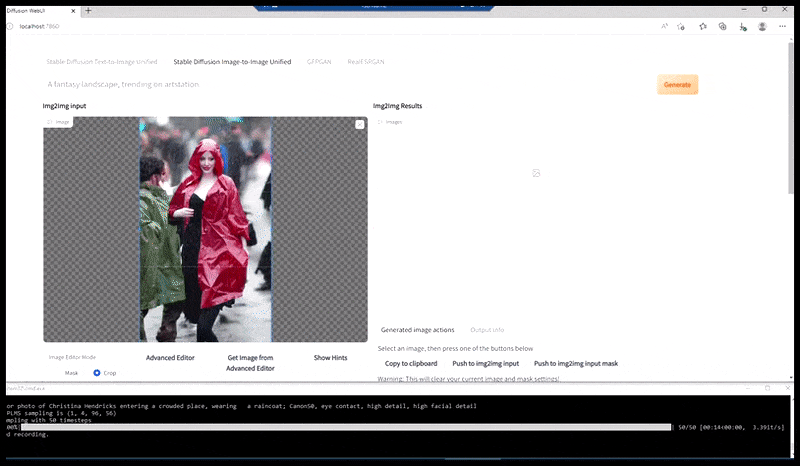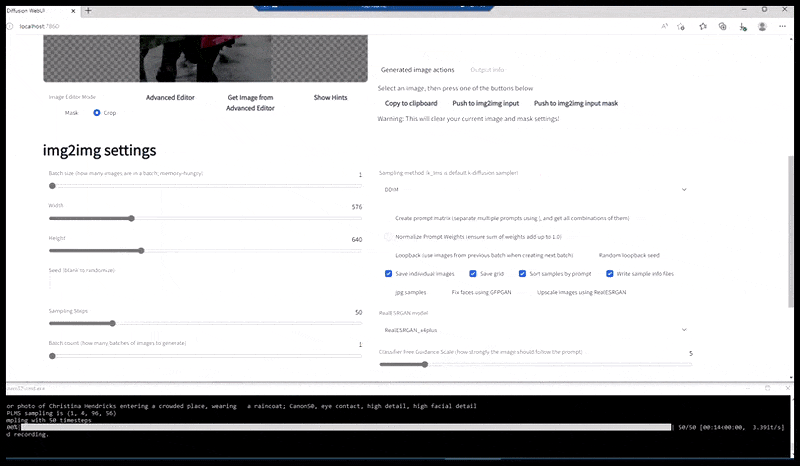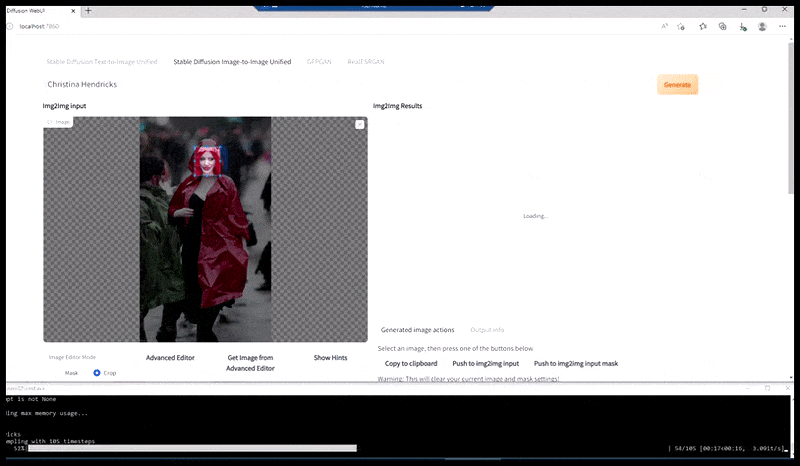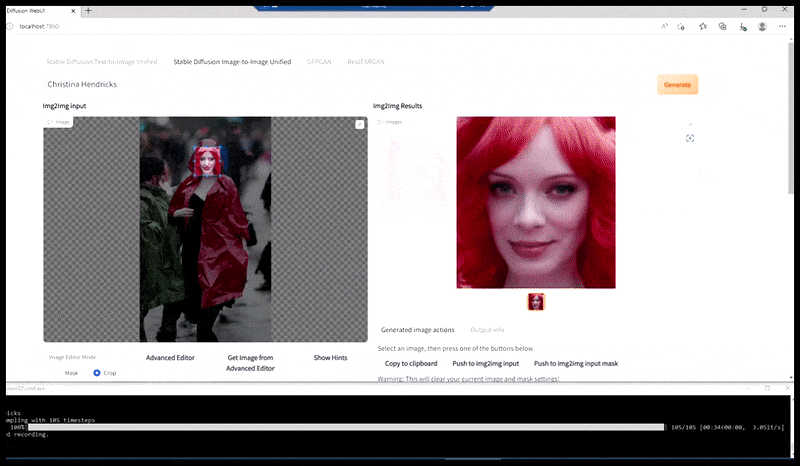
Die gelewerde beeld word deurgegee na Img2Img in Stabiele Diffusie, waar 'n 'fokusarea' gekies word, en 'n nuwe, maksimum-grootte weergawe word slegs van daardie area gemaak, wat Stabiele Diffusie in staat stel om alle beskikbare hulpbronne te konsentreer om die gesig te herskep.
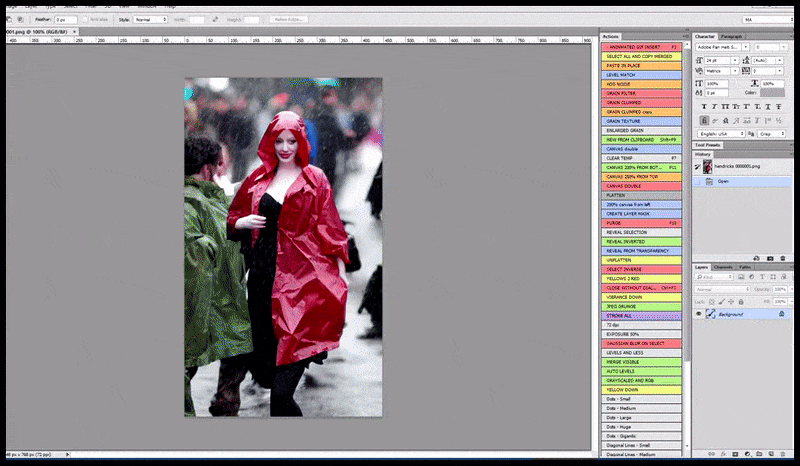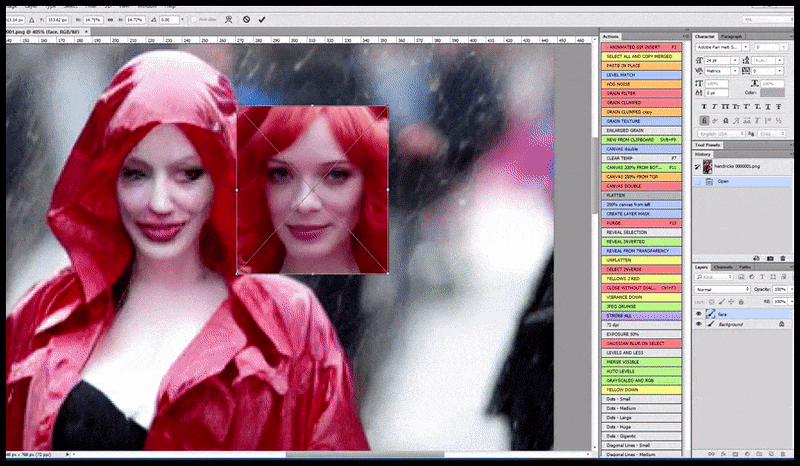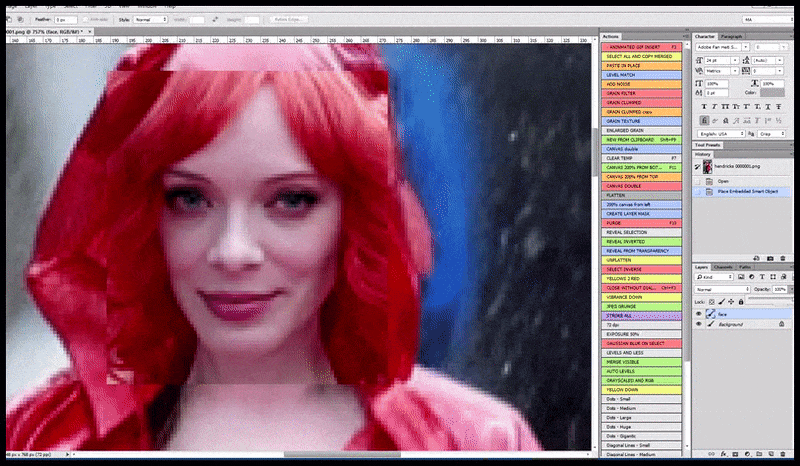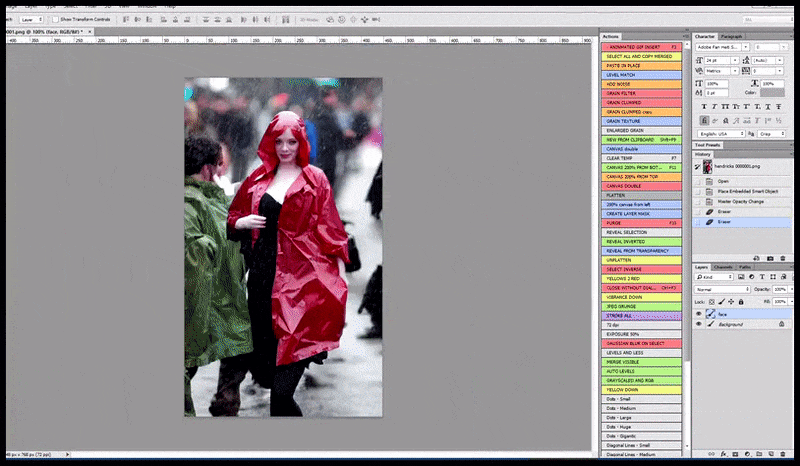
Om die 'hoë aandag' gesig terug te plaas in die oorspronklike weergawe. Behalwe gesigte, sal hierdie proses net werk met entiteite wat 'n potensiële bekende, samehangende en integrale voorkoms het, soos 'n gedeelte van die oorspronklike foto wat 'n duidelike voorwerp het, soos 'n horlosie of 'n motor. Die opskaling van 'n gedeelte van - byvoorbeeld - 'n muur gaan lei tot 'n baie vreemde voorkoms wat hersaamgestel is, want die teëlafbeeldings het geen wyer konteks vir hierdie 'legsaagstuk' gehad soos wat hulle weergegee het nie.
Sommige bekendes in die databasis word betyds 'voorafgevries', óf omdat hulle vroeg gesterf het (soos Marilyn Monroe), óf omdat hulle tot net vlugtige hoofstroom-prominensie gekom het, wat 'n groot volume beelde in 'n beperkte tydperk produseer. Polling Stable Diffusion bied waarskynlik 'n soort 'huidige' gewildheidsindeks vir moderne en ouer sterre. Vir sommige ouer en huidige bekendes is daar nie genoeg beelde in die brondata om 'n baie goeie ooreenkoms te verkry nie, terwyl die blywende gewildheid van bepaalde lank-dooie of andersins vervaagde sterre verseker dat hul redelike gelykenis van die stelsel verkry kan word.

Stabiele Diffusie-weergawes onthul vinnig watter bekende gesigte goed verteenwoordig is in die opleidingsdata. Ten spyte van haar enorme gewildheid as 'n ouer tiener ten tyde van die skryf hiervan, was Millie Bobby Brown jonger en minder bekend toe die LAION-brondatastelle van die web geskraap is, wat 'n hoë-gehalte ooreenkoms met Stable Diffusion problematies maak op die oomblik.
Waar die data beskikbaar is, kan teëlgebaseerde op-resolusie-oplossings in Stable Diffusion verder gaan as om op die gesig te kyk: hulle kan moontlik selfs meer akkurate en gedetailleerde gesigte moontlik maak deur die gelaatstrekke af te breek en die hele krag van plaaslike GPU te draai hulpbronne oor opvallende kenmerke individueel, voor hersamestelling – 'n proses wat tans weer handmatig is.

Dit is nie beperk tot gesigte nie, maar dit is beperk tot dele van voorwerpe wat minstens so voorspelbaar geplaas is in die wyer konteks van die gasheervoorwerp, en wat ooreenstem met hoëvlak-inbeddings wat 'n mens redelikerwys kan verwag om in 'n hiperskaal te vind. datastel.
Die werklike limiet is die hoeveelheid beskikbare verwysingsdata in die datastel, want uiteindelik sal diep-iterated detail totaal 'gehallusineerd' (dws fiktief) en minder outentiek word.
Sulke hoëvlakkorrelvergrotings werk in die geval van Jennifer Connelly, want sy is goed verteenwoordig oor 'n reeks ouderdomme in LAION-estetika (die primêre subset van LAION 5B wat Stabiele Diffusie gebruik), en oor die algemeen oor LAION; in baie ander gevalle sal akkuraatheid ly as gevolg van 'n gebrek aan data, wat óf fyn instel (bykomende opleiding, sien 'Aanpassing' hieronder) óf Tekstuele inversie (sien hieronder) noodsaak.
Teëls is 'n kragtige en relatief goedkoop manier waarop Stabiele Diffusie in staat gestel kan word om hoë-resolusie-uitset te produseer, maar algoritmiese geteëlde opskaling van hierdie soort, as dit nie 'n soort breër, hoërvlak-aandagmeganisme het nie, kan tekort skiet aan die gehoop- vir standaarde oor 'n reeks inhoudtipes.
2: Aanspreek van kwessies met menslike ledemate
Stabiele Diffusie doen nie sy naam gestand wanneer dit die kompleksiteit van menslike ledemate uitbeeld nie. Hande kan lukraak vermenigvuldig, vingers saamsmelt, derde bene lyk ongewens, en bestaande ledemate verdwyn spoorloos. In sy verdediging deel Stable Diffusion die probleem met sy stalmaats, en beslis met DALL-E 2.

Nie-geredigeerde resultate van DALL-E 2 en Stable Diffusion (1.4) aan die einde van Augustus 2022, wat albei probleme met ledemate toon. Prompt is ''n Vrou wat 'n man omhels'
Stabiele Diffusie-aanhangers wat hoop dat die komende 1.5-kontrolepunt ('n meer intens opgeleide weergawe van die model, met verbeterde parameters) die ledemaatverwarring sal oplos, sal waarskynlik teleurgesteld wees. Die nuwe model, wat vrygestel sal word in ongeveer twee weke, word tans op die kommersiële stability.ai-portaal vertoon droom studio, wat 1.5 by verstek gebruik, en waar gebruikers die nuwe uitvoer kan vergelyk met weergawes van hul plaaslike of ander 1.4-stelsels:

Bron: Local 1.4 prepack en https://beta.dreamstudio.ai/

Bron: Local 1.4 prepack en https://beta.dreamstudio.ai/

Bron: Local 1.4 prepack en https://beta.dreamstudio.ai/
Soos dikwels die geval is, kan datakwaliteit die primêre bydraende oorsaak wees.
Die oopbrondatabasisse wat beeldsintesestelsels soos Stable Diffusion en DALL-E 2 aanvuur, is in staat om baie etikette vir beide individuele mense en intermenslike aksie te verskaf. Hierdie etikette word simbioties opgelei met hul gepaardgaande beelde, of segmente van beelde.

Stabiele Diffusion-gebruikers kan die konsepte wat in die model opgelei is, verken deur navraag te doen oor die LAION-estetiese datastel, 'n subset van die groter LAION 5B datastel, wat die stelsel aandryf. Die beelde word nie volgens hul alfabetiese etikette gerangskik nie, maar volgens hul 'estetiese telling'. Bron: https://rom1504.github.io/clip-retrieval/
A goeie hiërargie van Individuele etikette en klasse wat bydra tot die uitbeelding van 'n menslike arm sou iets wees soos lyf>arm>hand>vingers>[subsyfers + duim]> [syfersegmente]>Vingnaels.

Korrelvormige semantiese segmentering van die dele van 'n hand. Selfs hierdie buitengewoon gedetailleerde dekonstruksie laat elke 'vinger' as 'n enigste entiteit, wat nie die drie dele van 'n vinger en die twee dele van 'n duim verreken nie. Bron: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
In werklikheid is dit onwaarskynlik dat die bronbeelde so konsekwent oor die hele datastel geannoteer sal word, en etiketalgoritmes sonder toesig sal waarskynlik stop by die hoër vlak van – byvoorbeeld – 'hand', en laat die binnepiksels (wat tegnies 'vinger'-inligting bevat) as 'n ongemerkte massa pixels waaruit kenmerke arbitrêr afgelei sal word, en wat in latere weergawes as 'n knellende element kan manifesteer.

Hoe dit behoort te wees (regs bo, indien nie bo-snit nie), en hoe dit geneig is om te wees (regs onder), as gevolg van beperkte hulpbronne vir etikettering, of argitektoniese ontginning van sulke etikette as dit wel in die datastel bestaan.
Dus, as 'n latente diffusiemodel so ver kom as om 'n arm weer te gee, gaan dit byna seker ten minste probeer om 'n hand aan die einde van daardie arm weer te gee, want arm>hand is die minimaal vereiste hiërargie, redelik hoog in wat die argitektuur van 'menslike anatomie' weet.
Daarna is 'vingers' dalk die kleinste groepering, al is daar 14 verdere vinger/duim-onderdele om in ag te neem wanneer mensehande uitgebeeld word.
As hierdie teorie geld, is daar geen werklike oplossing nie, as gevolg van die sektorwye gebrek aan begroting vir handaantekeninge, en die gebrek aan voldoende effektiewe algoritmes wat etikettering kan outomatiseer terwyl dit lae foutkoerse lewer. In werklikheid kan die model tans staatmaak op menslike anatomiese konsekwentheid tot papier oor die tekortkominge van die datastel waarop dit opgelei is.
Een moontlike rede hoekom dit kan nie staatmaak op hierdie, onlangs voorgestelde by die Stable Diffusion Discord, is dat die model verward kan raak oor die korrekte aantal vingers wat 'n (realistiese) menslike hand moet hê omdat die LAION-afgeleide databasis wat dit aandryf, strokiesprentkarakters bevat wat minder vingers kan hê (wat op sigself is 'n arbeidsbesparende kortpad).

Twee van die potensiële skuldiges in 'vermiste vinger'-sindroom in Stabiele Diffusie en soortgelyke modelle. Hieronder, voorbeelde van tekenprenthande uit die LAION-estetiese datastel wat Stable Diffusion aandryf. Bron: https://www.youtube.com/watch?v=0QZFQ3gbd6I
As dit waar is, dan is die enigste voor die hand liggende oplossing om die model te heroplei, met uitsluiting van nie-realistiese mensgebaseerde inhoud, om te verseker dat werklike gevalle van weglating (dws geamputeerdes) gepas as uitsonderings bestempel word. Vanuit 'n datakurasiepunt alleen, sou dit nogal 'n uitdaging wees, veral vir hulpbron-gehongerde gemeenskapspogings.
Die tweede benadering sou wees om filters toe te pas wat sulke inhoud (dws 'hand met drie/vyf vingers') uitsluit om tydens leweringstyd te manifesteer, op baie dieselfde manier as wat OpenAI tot 'n sekere mate, gefiltreer GPT-3 en DALL-E2, sodat hul uitset gereguleer kan word sonder om die bronmodelle te heroplei.

Vir Stable Diffusion kan die semantiese onderskeid tussen syfers en selfs ledemate gruwelik vervaag word, wat die 1980's 'liggaamsgruwel'-string gruwelfilms van mense soos David Cronenberg herinner. Bron: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Dit sal egter weer etikette vereis wat dalk nie oor al die geaffekteerde beelde bestaan nie, wat ons met dieselfde logistieke en begrotingsuitdaging laat.
Daar kan aangevoer word dat daar twee oorblywende paaie vorentoe is: om meer data na die probleem te gooi, en die toepassing van derdeparty-vertolkingstelsels wat kan ingryp wanneer fisiese goofs van die tipe wat hier beskryf word aan die eindgebruiker voorgehou word (ten minste, laasgenoemde sou OpenAI 'n metode gee om terugbetalings te verskaf vir 'body horror'-weergawes, indien die maatskappy gemotiveer is om dit te doen).
3: Aanpassing
Een van die opwindendste moontlikhede vir die toekoms van Stable Diffusion is die vooruitsig dat gebruikers of organisasies hersiene stelsels sal ontwikkel; wysigings wat toelaat dat inhoud buite die voorafopgeleide LAION-sfeer in die stelsel geïntegreer word – ideaal sonder die onregeerbare uitgawes om die hele model weer op te lei, of die risiko verbonde aan opleiding in 'n groot volume nuwe beelde tot 'n bestaande, volwasse en bekwame model.
Na analogie: as twee minder begaafde studente by 'n gevorderde klas van dertig studente aansluit, sal hulle óf assimileer en inhaal, óf as uitskieters druip; in beide gevalle sal die klasgemiddelde prestasie waarskynlik nie beïnvloed word nie. As 15 minder begaafde studente egter aansluit, sal die graadkurwe vir die hele klas waarskynlik daaronder ly.
Net so kan die sinergistiese en redelik delikate netwerk van verhoudings wat oor volgehoue en duur modelopleiding opgebou word, gekompromitteer word, in sommige gevalle effektief vernietig, deur oormatige nuwe data, wat die uitsetkwaliteit vir die model oor die hele linie verlaag.
Die rede om dit te doen is hoofsaaklik waar jou belangstelling daarin lê om die model se konseptuele begrip van verhoudings en dinge heeltemal te kap, en dit toe te eien vir die eksklusiewe produksie van inhoud wat soortgelyk is aan die bykomende materiaal wat jy bygevoeg het.
Dus, opleiding 500,000 Simpsons rame in 'n bestaande Stabiele Diffusie-kontrolepunt sal waarskynlik uiteindelik vir jou 'n beter maak Simpsons simulator as wat die oorspronklike bou kon aangebied het, met die veronderstelling dat genoeg breë semantiese verwantskappe die proses oorleef (bv. Homer Simpson eet 'n worsbroodjie, wat dalk materiaal benodig oor worsbroodjies wat nie in jou bykomende materiaal was nie, maar wat reeds in die kontrolepunt bestaan het), en as jy aanvaar dat jy nie skielik wil oorskakel van Simpsons inhoud te skep fantastiese landskap deur Greg Rutkowski – want jou na-opgeleide model se aandag is grootliks afgelei, en sal nie so goed wees om daardie soort ding te doen soos dit voorheen was nie.
Een noemenswaardige voorbeeld hiervan is waifu-diffusie, wat suksesvol het na-opgeleide 56,000 XNUMX anime-beelde in 'n voltooide en opgeleide Stabiele Diffusie-kontrolepunt. Dit is egter 'n moeilike vooruitsig vir 'n stokperdjie, aangesien die model 'n opvallende minimum van 30 GB VRAM benodig, veel verder as wat waarskynlik beskikbaar sal wees op die verbruikersvlak in NVIDIA se komende 40XX-reeksvrystellings.

Die opleiding van pasgemaakte inhoud in Stabiele Diffusie via waifu-diffusie: die model het twee weke na-opleiding geneem om hierdie vlak van illustrasie uit te voer. Die ses beelde aan die linkerkant toon die vordering van die model, soos opleiding vorder, om vakkoherente uitset te maak gebaseer op die nuwe opleidingsdata. Bron: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Baie moeite kan aan sulke 'vurke' van Stabiele Diffusie-kontrolepunte bestee word, net om deur tegniese skuld gestuit te word. Ontwikkelaars by die amptelike Discord het reeds aangedui dat latere kontrolepuntvrystellings nie noodwendig agteruitversoenbaar gaan wees nie, selfs met vinnige logika wat moontlik met 'n vorige weergawe gewerk het, aangesien hul primêre belang is om die beste model moontlik te verkry, eerder as om te ondersteun erfenistoepassings en -prosesse.
Daarom het 'n maatskappy of individu wat besluit om 'n kontrolepunt af te skakel na 'n kommersiële produk, effektief geen pad terug nie; hul weergawe van die model is op daardie stadium 'n 'harde vurk' en sal nie stroomop voordele uit latere vrystellings van stability.ai kan trek nie – wat nogal 'n verbintenis is.
Die huidige, en groter hoop vir aanpassing van Stabiele Diffusie is Tekstuele inversie, waar die gebruiker in 'n klein handvol oplei CLIP-belynde beelde.

'n Samewerking tussen Tel Aviv Universiteit en NVIDIA, tekstuele omkering maak voorsiening vir die opleiding van diskrete en nuwe entiteite, sonder om die vermoëns van die bronmodel te vernietig. Bron: https://textual-inversion.github.io/
Die primêre oënskynlike beperking van teksomkering is dat 'n baie lae aantal beelde aanbeveel word - so min as vyf. Dit produseer effektief 'n beperkte entiteit wat meer bruikbaar kan wees vir styloordragtake eerder as die invoeging van fotorealistiese voorwerpe.
Desnieteenstaande vind eksperimente tans plaas binne die verskillende Stabiele Diffusie Discords wat baie hoër getalle opleidingsbeelde gebruik, en dit moet nog gesien word hoe produktief die metode kan wees. Weereens, die tegniek verg baie VRAM, tyd en geduld.
As gevolg van hierdie beperkende faktore sal ons dalk 'n rukkie moet wag om van die meer gesofistikeerde tekstuele inversie-eksperimente van Stable Diffusion-entoesiaste te sien – en of hierdie benadering jou 'in die prentjie' kan plaas op 'n manier wat beter lyk as 'n Photoshop knip-en-plak, terwyl die verstommende funksionaliteit van die amptelike kontrolepunte behou word.
Eerste gepubliseer 6 September 2022.















