
Kunsmatige Intelligensie
Google beoog 'n GPT-3-agtige navraagstelsel, sonder soekresultate

'n Nuwe referaat van vier Google-navorsers stel 'n 'deskundige'-stelsel voor wat gebruikers se vrae gesaghebbend kan beantwoord sonder om 'n lys van moontlike soekresultate aan te bied, soortgelyk aan die V&A-paradigma wat deur die koms van GPT-3 in die verlede onder die publiek se aandag gekom het. jaar.
Die papier, geregtig Heroorweging van soektog: maak kundiges uit Dilettante, stel voor dat die huidige standaard om die gebruiker van 'n lys soekresultate in reaksie op 'n navraag aan te bied 'n 'kognitiewe las' is, en stel verbeterings voor in die vermoë van 'n natuurlike taalverwerkingstelsel (NLP) om 'n gesaghebbende en definitiewe antwoord te verskaf .
Onder die voorgestelde model van 'n 'kundige', kruisdomein-orakel, sal die duisende moontlike soekresultaatbronne in 'n taalmodel gebak word in plaas daarvan om eksplisiet beskikbaar te wees as 'n verkennende hulpbron vir gebruikers om self te evalueer en te navigeer. Bron: https://arxiv.org/pdf/2105.02274.pdf
Die referaat, gelei deur Donald Metzler by Google Research, stel verbeterings voor in die tipe multi-domein orakel-reaksies wat tans verkry kan word uit diepte-leer outoregressiewe taalmodelle soos GPT-3. Die belangrikste verbeterings wat in die vooruitsig gestel word, is a) dat die model in staat sal wees om die bronne wat die reaksie ingelig het, akkuraat aan te haal, en b) dat die model verhoed sal word om 'hallusineer' antwoorde of die uitvind van nie-bestaande bronmateriaal, wat tans 'n probleem met sulke argitekture is.
Multi-domein opleiding en vermoëns
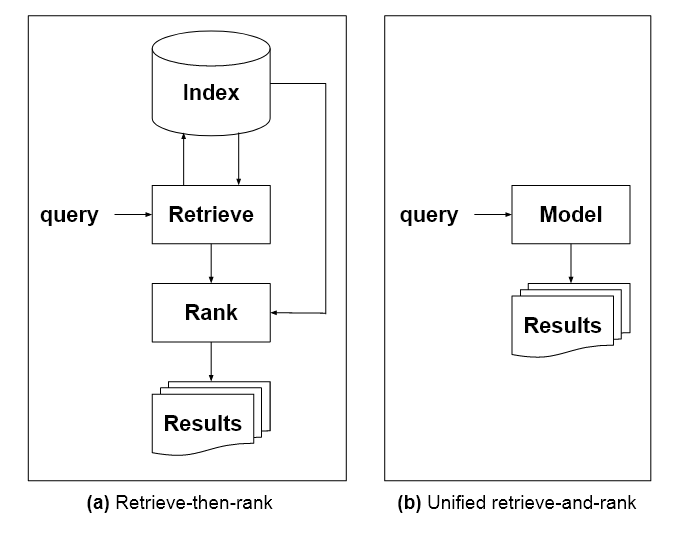
Daarbenewens sal die voorgestelde taalmodel, wat in die referaat as ''n Enkele model vir alle inligtingherwinningstake' gekenmerk word, opgelei word op 'n verskeidenheid domeine, insluitend beelde en teks. Dit sal ook 'n begrip nodig hê oor die herkoms van kennis, wat ontbreek in GPT-3-styl-argitekture.
'Om indekse met 'n enkele, verenigde model te vervang, moet dit vir die model self moontlik wees om kennis te hê oor die heelal van dokumentidentifiseerders, op dieselfde manier as wat tradisionele indekse doen. Een manier om dit te bereik, is om weg te beweeg van tradisionele LM'e en na korpusmodelle wat gesamentlik term-term, term-dokument en dokument-dokument verhoudings modelleer.'

In die prent hierbo, uit die referaat, drie benaderings in reaksie op 'n gebruikernavraag: links, die taalmodelle wat implisiet is in Google se algoritmiese soekresultate het 'n 'beste antwoord' gekies en geprioritiseer, maar het dit as die topresultaat van baie gelaat. Sentrum, 'n GPT-3-styl gespreksreaksie, wat met gesag praat, maar nie sy aansprake regverdig of bronne aanhaal nie. Reg, die voorgestelde deskundige stelsel inkorporeer die 'beste reaksie' van die gerangskik soekresultate direk in 'n didaktiese antwoord, met akademiese-styl voetnoot aanhalings (nie uitgebeeld in die oorspronklike beeld) wat die bronne aandui wat die antwoord inlig.
Verwydering van giftige en onakkurate resultate
Die navorsers merk op dat die dinamiese en voortdurend bygewerkte aard van soekindekse 'n uitdaging is om heeltemal in 'n masjienleermodel van hierdie aard te herhaal. Byvoorbeeld, waar 'n eens vertroude bron direk opgelei is in die model se begrip van die wêreld, kan die verwydering van die invloed daarvan (byvoorbeeld nadat dit gediskrediteer is) moeiliker wees as om net 'n URL van SERP's te verwyder, aangesien datakonsepte kan word abstrak en wyd verteenwoordig tydens assimilasie in opleiding.
Boonop sal so 'n model deurlopend opgelei moet word om dieselfde vlak van reaksie op nuwe artikels en publikasies te bied as wat tans verskaf word deur Google se konstante spidering van bronne. Dit beteken effektief deurlopende en outomatiese uitrol, in teenstelling met die huidige regime, waar geringe wysigings aan die gewigte en instellings van die vryvormsoekalgoritme aangebring word, maar die algoritme self word gewoonlik net selde opgedateer.
Aanvalsoppervlaktes vir 'n gesentraliseerde deskundige orakel
'n Gesentraliseerde model wat voortdurend nuwe data assimileer en veralgemeen, kan die aanvaloppervlak vir soeknavrae transformeer.
Tans kan 'n aanvaller voordeel verkry deur 'n hoë posisie te behaal vir domeine of bladsye wat óf verkeerde inligting óf kwaadwillige kode bevat. Onder die beskerming van 'n meer ondeursigtige 'deskundige'-orakel word die geleentheid om gebruikers na aanvalsdomeine te herlei aansienlik verminder, maar die moontlikheid om giftige data-aanvalle in te spuit word aansienlik vergroot.
Dit is omdat die voorgestelde stelsel nie die soekrangorde-algoritme uitskakel nie, maar dit vir die gebruiker verberg, die prioriteit van die topresultaat/s effektief outomatiseer en dit (of hulle) in 'n didaktiese stelling bak. Kwaadwillige gebruikers was lank reeds in staat om aanvalle teen die Google-soekalgoritme te orkestreer, om vals produkte verkoop, direkte gebruikers na wanware-verspreidende domeine, of vir doeleindes van politieke manipulasie, onder baie ander gebruiksgevalle.
Nie AGI nie
Die navorsers beklemtoon dat so 'n stelsel waarskynlik nie as Kunsmatige Algemene Intelligensie (AGI) sal kwalifiseer nie, en die vooruitsig van 'n universele kundige reageerder in die konteks van natuurlike taalverwerking sal plaas, onderhewig aan al die uitdagings wat sulke modelle tans in die gesig staar.
Die vraestel gee 'n uiteensetting van vyf vereistes vir 'n 'hoë kwaliteit' reaksie:
1: Gesag
Soos met huidige rangordealgoritmes, blyk 'gesag' afgelei te word van aanhaling van hoë kwaliteit domeine wat op sigself as gesaghebbend beskou word. Die navorsers neem waar:
'Reaksies moet inhoud genereer deur uit hoogs gesaghebbende bronne te trek. Dit is nog 'n rede waarom die vestiging van meer eksplisiete verbande tussen reekse terme en dokumentmetadata so noodsaaklik is. As al die dokumente in 'n korpus met 'n gesaghebbende-telling geannoteer is, moet daardie telling in ag geneem word wanneer die model opgelei word, reaksies gegenereer word, of albei.'
Alhoewel die navorsers nie voorstel dat tradisionele SERP-resultate onbeskikbaar sou word as 'n kundige orakel van hierdie tipe as presterende en gewild gevind word nie, bied die hele referaat wel die tradisionele ranglysstelsel en soekresultaatlyste aan in die lig van 'n 'dekades ou' en verouderde inligtingherwinningstelsel.
'Die feit dat rangorde 'n kritieke komponent van hierdie paradigma is, is 'n simptoom van die herwinningstelsel wat gebruikers 'n seleksie van potensiële antwoorde bied, wat 'n taamlik beduidende kognitiewe las op die gebruiker veroorsaak. Die begeerte om antwoorde terug te gee in plaas van geranglyste resultate was een van die motiverende faktore vir die ontwikkeling van vraagantwoordstelsels. '
2: Deursigtigheid
Die navorsers lewer kommentaar:
'Waar moontlik, moet die herkoms van die inligting wat aan die gebruiker aangebied word, aan hulle beskikbaar gestel word. Is dit die primêre bron van inligting? Indien nie, wat is die primêre bron?'
3: Hantering Vooroordeel
Die referaat merk op dat vooraf-opgeleide taalmodelle nie ontwerp is om empiriese waarheid te evalueer nie, maar om dominante tendense in die data te veralgemeen en te prioritiseer. Dit gee toe dat hierdie richtlijn die model oopmaak om aan te val (soos met Microsoft s'n onbedoelde rassistiese kletsbot in 2016), en dat bykomende stelsels nodig sal wees om teen sulke bevooroordeelde stelselreaksies te beskerm.
4: Verskeie standpunte moontlik maak
Die referaat stel ook meganismes voor om 'n veelheid van standpunte te verseker:
'Gegenereerde antwoorde moet 'n reeks uiteenlopende perspektiewe verteenwoordig, maar moet nie polariserend wees nie. Byvoorbeeld, vir navrae oor kontroversiële onderwerpe, moet beide kante van die onderwerp op 'n regverdige en gebalanseerde manier behandel word. Dit het natuurlik noue verbintenisse met modelvooroordeel.'
5: Toeganklike Taal
Benewens die verskaffing van akkurate vertalings in gevalle waar die geagte gesaghebbende antwoord in 'n ander taal is, stel die artikel voor dat ingekapselde antwoorde 'in so eenvoudig-as-moontlike terme geskryf moet word'.















