
Kunsmatige Intelligensie
Skep 'n GPT-styl-taalmodel vir 'n enkele vraag

Navorsers van China het 'n ekonomiese metode ontwikkel om GPT-3-styl natuurlike taalverwerkingstelsels te skep, terwyl hulle die toenemend onbetaalbare uitgawes van tyd en geld vermy wat betrokke is by die opleiding van hoëvolume datastelle - 'n groeiende neiging wat andersins dreig om hierdie sektor van KI uiteindelik te relegeer aan FAANG-spelers en hoëvlakbeleggers.
Die voorgestelde raamwerk word genoem Taakgedrewe taalmodellering (TLM). In plaas daarvan om 'n groot en komplekse model op 'n groot korpus van miljarde woorde en duisende etikette en klasse op te lei, lei TLM eerder 'n veel kleiner model op wat eintlik 'n navraag direk binne die model insluit.

Links, 'n tipiese hiperskaalbenadering tot hoëvolume taalmodelle; reg, TLM se slanke metode om 'n groot taalkorpus op 'n per-onderwerp of per-vraag-basis te verken. Bron: https://arxiv.org/pdf/2111.04130.pdf
Effektief word 'n unieke NLP-algoritme of -model vervaardig om 'n enkele vraag te beantwoord, in plaas daarvan om 'n enorme en lomp algemene taalmodel te skep wat 'n groter verskeidenheid vrae kan beantwoord.
In die toetsing van TLM het die navorsers bevind dat die nuwe benadering resultate behaal wat soortgelyk of beter is as voorafopgeleide taalmodelle soos bv. ROBERTA-Groot, en hiperskaal NLP-stelsels soos OpenAI se GPT-3, Google se TRILLION Parameter Switch Transformer model, Korea HyperClover, AI21 Labs' Jurassic 1, en Microsoft s'n Megatron-Turing NLG 530B.
In proewe van TLM oor agt klassifikasiedatastelle oor vier domeine, het die skrywers ook gevind dat die stelsel die opleiding-FLOP's verminder (swaaipuntbewerkings per sekonde) vereis deur twee ordes van grootte. Die navorsers hoop dat TLM 'n sektor kan 'demokratiseer' wat al hoe meer elite word, met NLP-modelle wat so groot is dat dit nie realisties plaaslik geïnstalleer kan word nie, en eerder, in die geval van GPT-3, agter die duur en beperkte toegang API's van OpenAI en, nou, Microsoft Azure.
Die skrywers sê dat die verkorting van opleidingstyd met twee ordes van grootte opleidingskoste van meer as 1,000 8 GPU's vir een dag verminder tot slegs 48 GPU's oor XNUMX uur.
Die nuwe verslag is getiteld NLP van nuuts af sonder grootskaalse vooropleiding: 'n eenvoudige en doeltreffende raamwerk, en kom van drie navorsers aan die Tsinghua Universiteit in Beijing, en 'n navorser van China-gebaseerde KI-ontwikkelingsmaatskappy Recurrent AI, Inc.
Onbekostigbare antwoorde
Die kos van opleiding doeltreffende, alledaagse taalmodelle word toenemend gekenmerk as 'n potensiële 'termiese beperking' op die mate waarin presterende en akkurate NLP werklik in kultuur versprei kan word.
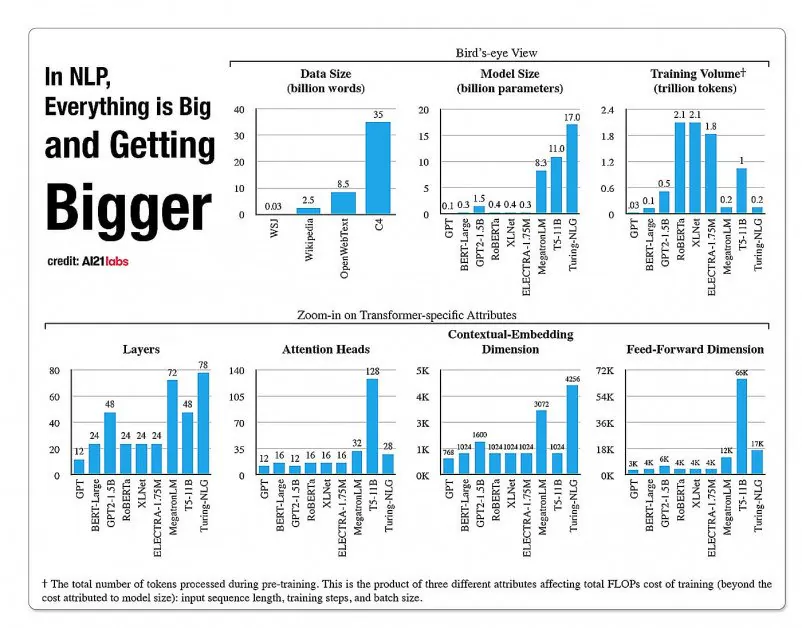
Statistieke oor die groei van fasette in NLP-modelargitekture, uit 'n 2020-verslag deur A121 Labs. Bron: https://arxiv.org/pdf/2004.08900.pdf
In 2019 'n navorser bereken dat dit $61,440 USD kos om die op te lei XLNet-model (Destyds gerapporteer om BERT in NLP-take te klop) oor 2.5 dae op 512 kerns oor 64 toestelle, terwyl GPT-3 beraamde $12 miljoen gekos het om op te lei – 200 keer die koste van die opleiding van sy voorganger, GPT-2 (hoewel onlangse herskattings beweer dat dit nou opgelei kan word vir 'n skamele $ 4,600,000 op die laagste prys-wolk-GPU's).
Substelle data gebaseer op navraagbehoeftes
In plaas daarvan poog die nuwe voorgestelde argitektuur om akkurate klassifikasies, etikette en veralgemening af te lei deur 'n navraag as 'n soort filter te gebruik om 'n subset van inligting uit 'n groot taaldatabasis te definieer wat saam met die navraag opgelei sal word om antwoorde te verskaf oor 'n beperkte onderwerp.
Die skrywers sê:
'TLM word gemotiveer deur twee sleutelidees. Eerstens bemeester mense 'n taak deur slegs 'n klein gedeelte van wêreldkennis te gebruik (bv. studente hoef net 'n paar hoofstukke te hersien, tussen alle boeke in die wêreld, om vir 'n eksamen in te prop).
'Ons veronderstel dat daar baie oortolligheid in die groot korpus vir 'n spesifieke taak is. Tweedens, opleiding oor gemerkte data onder toesig is baie meer data doeltreffend vir stroomaf prestasie as om die taalmodelleringsdoelwit op ongemerkte data te optimaliseer. Op grond van hierdie motiverings gebruik TLM die taakdata as navrae om 'n klein subset van die algemene korpus te herwin. Dit word gevolg deur die gesamentlike optimalisering van 'n taakdoelwit onder toesig en 'n taalmodelleringsdoelwit deur beide die opgespoorde data en die taakdata te gebruik.'
Behalwe om hoogs effektiewe NLP-modelopleiding bekostigbaar te maak, sien die skrywers 'n aantal voordele aan die gebruik van taakgedrewe NLP-modelle. Vir een kan navorsers groter buigsaamheid geniet, met pasgemaakte strategieë vir volgordelengte, tokenisering, hiperparameterinstelling en datavoorstellings.
Die navorsers voorsien ook die ontwikkeling van hibriede toekomstige stelsels wat beperkte vooropleiding van 'n PLM (wat andersins nie in die huidige implementering verwag word nie) verruil teen groter veelsydigheid en veralgemening teen opleidingstye. Hulle beskou die stelsel as 'n stap vorentoe vir die bevordering van in-domein nul-skoot veralgemeningsmetodes.
Toets en resultate
TLM is getoets op klassifikasie-uitdagings in agt take oor vier domeine – biomediese wetenskap, nuus, resensies en rekenaarwetenskap. Die take is in hoëhulpbron- en laehulpbronkategorieë verdeel. Hoë hulpbrontake het meer as 5,000 XNUMX taakdata ingesluit, soos AGNuus en RCT, onder andere; laehulpbrontake ingesluit ChemProt en ACL-ARC, Sowel as die HiperPartisan nuusbespeuringsdatastel.
Die navorsers het twee opleidingsstelle met die titel Corpus-BERT en Corpus-RoBERTa ontwikkel, laasgenoemde tien keer die grootte van eersgenoemde. Die eksperimente het algemene Vooropgeleide Taalmodelle vergelyk BERT (van Google) en ROBERTA (van Facebook) na die nuwe argitektuur.
Die referaat merk op dat alhoewel TLM 'n algemene metode is, en meer beperk in omvang en toepaslikheid behoort te wees as breër en hoërvolume state-of-the-art modelle, dit in staat is om naby aan domein-aanpasbare fynverstellingsmetodes uit te voer.

Resultate van vergelyking van die prestasie van TLM met BERT- en RobERTa-gebaseerde stelle. Die resultate lys 'n gemiddelde F1-telling oor drie verskillende opleidingskale, en lys die aantal parameters, totale opleidingsberekening (FLOP's) en grootte van opleidingskorpus.
Die skrywers kom tot die gevolgtrekking dat TLM in staat is om resultate te behaal wat vergelykbaar of beter is as PLM's, met 'n aansienlike vermindering in FLOP's wat nodig is, en wat slegs 1/16de van die opleidingskorpus benodig. Oor medium en groot skale kan TLM blykbaar prestasie met gemiddeld 0.59 en 0.24 punte verbeter, terwyl opleidingsdatagrootte met twee ordes van grootte verminder word.
'Hierdie resultate bevestig dat TLM hoogs akkuraat en baie meer doeltreffend is as PLM's. Boonop kry TLM meer voordele in doeltreffendheid op 'n groter skaal. Dit dui daarop dat groterskaalse PLM's dalk opgelei is om meer algemene kennis te stoor wat nie bruikbaar is vir 'n spesifieke taak nie.'















