
Kunsmatige Intelligensie
'n KI-gedrewe vooroordeeltoetser vir nuusartikels, beskikbaar in Python

Navorsers in Kanada, Indië, China en Australië het saamgewerk om 'n vrylik-beskikbare Python-pakket te vervaardig wat effektief gebruik kan word om 'onregverdige taal' in nuuskopie op te spoor en te vervang.
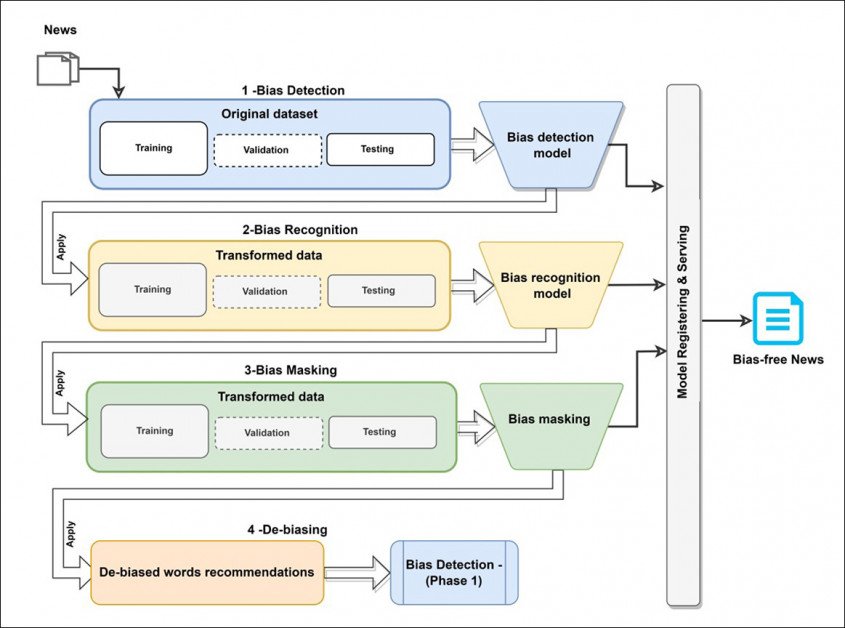
Die stelsel, getiteld Dbias, gebruik verskeie masjienleertegnologieë en databasisse om 'n drie-fase sirkelwerkvloei te ontwikkel wat kan verfyn bevooroordeelde teks totdat dit 'n nie-bevooroordeelde, of ten minste meer neutrale weergawe terugstuur.

Gelaaide taal in 'n nuusbrokkie wat as 'bevooroordeeld' geïdentifiseer is, word deur Dbias in 'n minder opruiende weergawe omskep. Bron: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
Die stelsel verteenwoordig 'n herbruikbare en selfstandige pyplyn wat kan wees geïnstalleer via Pip van Hugging Face, en geïntegreer in bestaande projekte as 'n aanvullende stadium, byvoeging of inprop.
In April is soortgelyke funksionaliteit in Google Docs geïmplementeer onder kritiek gekom, nie die minste nie vir sy gebrek aan redigeerbaarheid. Dbias, aan die ander kant, kan meer selektief opgelei word op enige korpus nuus wat die eindgebruiker wil hê, met behoud van die vermoë om pasgemaakte regverdigheidsriglyne te ontwikkel.
Die kritieke verskil is dat die Dbias-pyplyn bedoel is om 'gelaaide taal' (woorde wat 'n kritiese laag by feitelike kommunikasie voeg) outomaties in neutrale of prosaïese taal te transformeer, eerder as om die gebruiker op 'n deurlopende basis te skool. In wese sal die eindgebruiker etiese filters definieer en die stelsel dienooreenkomstig oplei; in die Google Docs-benadering lei die stelsel – waarskynlik – die gebruiker op 'n eensydige wyse op.
Konseptuele argitektuur vir die Dbias-werkvloei.
Volgens die navorsers is Dbias die eerste werklik konfigureerbare vooroordeelbespeuringspakket, in teenstelling met die uit-die-rak-samestellingsprojekte wat hierdie subsektor van Natuurlike Taalverwerking (NLP) tot op hede gekenmerk het.
Die nuwe papier is getiteld 'n Benadering om regverdigheid in nuusartikels te verseker, en kom van bydraers aan die Universiteit van Toronto, Toronto Metropolitaanse Universiteit, Omgewingshulpbronbestuur in Bangalore, DeepBlue Academy of Sciences in China, en die Universiteit van Sydney.
Metode
Die eerste module in Dbias is Vooroordeel-opsporing, wat gebruik maak van die DistilBERT pakket – 'n hoogs geoptimaliseerde weergawe van Google se redelik masjien-intensiewe BERT. Vir die projek is DistilBERT verfyn op die Media Bias Annotation (MBIC) datastel.

MBIC bestaan uit nuusartikels uit 'n verskeidenheid mediabronne, insluitend die Huffington Post, USA Today en MSNBC. Die navorsers het die uitgebreide weergawe van die datastel gebruik.
Alhoewel die oorspronklike data geannoteer is deur werkers wat deur skare verkry is ('n metode wat het onder vuur gekom laat in 2021) kon die navorsers van die nuwe referaat bykomende ongemerkte gevalle van vooroordeel in die datastel identifiseer en dit handmatig bygevoeg. Die geïdentifiseerde voorkoms van vooroordeel wat verband hou met ras, opvoeding, etnisiteit, taal, godsdiens en geslag.
Die volgende module, Vooroordeel Erkenning, gebruike Benoemde entiteitsherkenning (NER) om bevooroordeelde woorde uit die invoerteks te individueer. Die koerant sê:
'Byvoorbeeld, die nuus "Moenie die pseudo-wetenskaplike hype oor tornado's en klimaatsverandering koop nie" is geklassifiseer as bevooroordeeld deur die voorafgaande bevooroordeelde opsporingsmodule, en die bevooroordeelde herkenningsmodule kan nou die term "pseudo-wetenskaplike hype" identifiseer. as 'n bevooroordeelde woord.'
NER is nie spesifiek vir hierdie taak ontwerp nie, maar is wel gebruik voor vir vooroordeel-identifikasie, veral vir a 2021-projek van Durham Universiteit in die Verenigde Koninkryk.
Vir hierdie stadium het die navorsers gebruik ROBERTA gekombineer met die SpaCy English Transformer NER-pyplyn.

Die volgende fase, Vooroordeelmaskering, behels 'n nuwe meervoudige masker van die geïdentifiseerde vooroordeelwoorde, wat opeenvolgend werk in gevalle van veelvuldige geïdentifiseerde vooroordeelwoorde.

Gelaaide taal word vervang met pragmatiese taal in die derde fase van Dbias. Let daarop dat 'bek' en 'gebruik' gelykstaande is aan dieselfde handeling, hoewel eersgenoemde as bespotlik beskou word.
Soos nodig, sal die terugvoer vanaf hierdie stadium teruggestuur word na die begin van die pyplyn vir verdere evaluering totdat 'n aantal geskikte alternatiewe fraserings of woorde gegenereer is. Hierdie stadium gebruik Masked Language Modeling (MLM) volgens lyne wat deur a 2021 samewerking gelei deur Facebook Research.
Normaalweg sal die MLM-taak 15% van die woorde lukraak masker, maar die Dbias-werkvloei vertel eerder die proses om die geïdentifiseerde bevooroordeelde woorde as invoer te neem.
Die argitektuur is geïmplementeer en opgelei op Google Colab Pro op 'n NVIDIA P100 met 24 GB VRAM teen 'n bondelgrootte van 16, met slegs twee etikette (bevooroordeeld en onbevooroordeelde).
Toetse
Die navorsers het Dbias getoets teen vyf vergelykbare benaderings: LG-TFIDF met Logistieke regressie en TfidfVectorizer (TFIDF) woordinbeddings; LG-ELMO; MLP-ELMO ('n kunsmatige neurale netwerk wat ELMO-inbeddings bevat); BERT; en ROBERTA.
Metrieke wat vir die toetse gebruik is, was akkuraatheid (ACC), presisie (PREC), herroep (Rec) en 'n F1-telling. Aangesien die navorsers geen kennis gehad het van enige bestaande stelsel wat al drie take in 'n enkele pyplyn kan verrig nie, is dispensasie gemaak vir die mededingende raamwerke, deur slegs Dbias se primêre take te evalueer – vooroordeelopsporing en -herkenning.

Resultate van die Dbias proewe.
Dbias het daarin geslaag om resultate van alle mededingende raamwerke te oortref, insluitend dié met 'n swaarder verwerkingsvoetspoor
Die artikel sê:
'Die resultaat toon ook dat diep neurale inbeddings oor die algemeen beter kan presteer as tradisionele inbeddingsmetodes (bv. TFIDF) in die vooroordeelklassifikasietaak. Dit word getoon deur die beter werkverrigting van diep neurale netwerk-inbeddings (dws ELMO) in vergelyking met TFIDF-vektorisering wanneer dit met LG gebruik word.
'Dit is waarskynlik omdat diep neurale inbeddings die konteks van die woorde in die teks in verskillende kontekste beter kan vasvang. Die diep neurale inbeddings en diep neurale metodes (MLP, BERT, RoBERTa) presteer ook beter as tradisionele ML metode (LG).'
Die navorsers merk ook op dat transformator-gebaseerde metodes beter presteer as mededingende metodes in vooroordeelopsporing.
'n Bykomende toets het 'n vergelyking tussen Dbias en verskeie geure van die SpaCy Core Web behels, insluitend kern-sm (klein), kern-md (medium) en kern-lg (groot). Dbias kon die direksie ook in hierdie proewe lei:

Die navorsers sluit af deur waar te neem dat vooroordeelherkenningstake oor die algemeen beter akkuraatheid toon in groter en duurder modelle, as gevolg van - hulle spekuleer - van die verhoogde aantal parameters en datapunte. Hulle neem ook waar dat die doeltreffendheid van toekomstige werk in hierdie veld sal afhang van groter pogings om datastelle van hoë gehalte te annoteer.
Die Bos en die Bome
Hopelik sal hierdie soort fyn vooroordeel-herkenningsprojek uiteindelik geïnkorporeer word in vooroordeel-soekende raamwerke wat in staat is om 'n minder bysiende siening te neem, en om in ag te neem dat die keuse om enige spesifieke storie te dek op sigself 'n daad van vooroordeel is wat moontlik is gedryf deur meer as net gerapporteerde kykstatistieke.
Eerste gepubliseer 14 Julie 2022.















