
Kunsmatige Intelligensie
KI-gegenereerde taal begin wetenskaplike literatuur besoedel

Navorsers van Frankryk en Rusland het 'n studie gepubliseer wat aandui dat die gebruik van KI-gedrewe waarskynlike teksopwekkers soos GPT-3 'gemartelde taal', aanhalings van nie-bestaande literatuur en ad hoc, ongekrediteerde beeldhergebruik in voorheen gerespekteerde kanale vir die publikasie van nuwe wetenskaplike literatuur.
Miskien is die grootste kommer dat die referate wat bestudeer is, ook wetenskaplik onakkurate of nie-reproduceerbare inhoud bevat wat aangebied word as die vrugte van objektiewe en sistematiese navorsing, wat aandui dat generatiewe taalmodelle nie net gebruik word om die beperkte Engelse vaardighede van die referate se skrywers te versterk nie, maar eintlik om die harde werk daaraan verbonde te doen (en, sonder uitsondering, om dit sleg te doen).
Die verslag, getitel Gemartelde frases: 'n twyfelagtige skryfstyl wat in die wetenskap na vore kom, is saamgestel deur navorsers van die Rekenaarwetenskap-departement aan die Universiteit van Toulouse en Yandex-navorser Alexander Magazinov, tans aan die Universiteit van Tel Aviv.
Die studie fokus veral op die groei van onsinnige KI-gegenereerde wetenskaplike publikasies by die Elsevier Journal Mikroverwerkers en mikrosisteme.
By enige ander naam
Outoregressiewe taalmodelle soos GPT-3 is opgelei op hoë volumes data, en is ontwerp om daardie bydraende data te parafraseer, op te som, te versamel en te interpreteer in samehangende generatiewe taalmodelle wat in staat is om natuurlike spraak- en skryfpatrone weer te gee, terwyl die oorspronklike behou word. bedoeling van die opleidingsdata.
Aangesien sulke raamwerke gereeld in die modelopleidingstadium gestraf word omdat hulle direkte en 'nie-geabsorbeerde' herhaling van die oorspronklike data bied, soek hulle onvermydelik sinonieme – selfs vir goed gevestigde frases.
Die skynbaar KI-geskepte/gesteunde wetenskaplike voorleggings wat deur die navorsers opgegrawe is, sluit 'n buitengewone aantal mislukte pogings tot kreatiewe sinonieme vir bekende frases in die masjienleersektor in:
diep neurale netwerk: 'diepgaande neurale organisasie'
kunsmatige neurale netwerkk: '(vals | nagemaakte) neurale organisasie'
Mobiele netwerk: "veelsydige organisasie'
netwerk aanval: "organisasie (hinderlaag | aanranding)'
netwerk konneksie: 'organisasie vereniging'
groot data: "(enorme | groot | ontsaglike | kolossale) inligting'
datastoor: 'inligting (voorraadkamer | verspreidingsentrum)'
kunsmatige intelligensie (KI): '(nagemaakte | mensgemaakte) bewussyn'
hoë werkverrigting rekenaar: 'elite-figurasie'
mis/mis/wolk rekenaar: 'waas figuring'
grafiese verwerkingseenheid (GPU): 'ontwerp-voorbereidingseenheid'
sentrale verwerkingseenheid (CPU): 'fokusvoorbereidingseenheid'
werksvloei-enjin: 'werk proses motor'
gesigherkenning: 'gesigserkenning'
Stemherkenning: 'diskoerserkenning'
gemiddelde vierkante fout: 'gemiddelde vierkant (fout | flater)'
beteken absolute fout: 'mee (reguit | opperste) (fout | flater)'
sein na geraas: '(beweging | vlag | aanwyser | teken | sein) na (gedreun | rumoer | geraas)'
globale parameters: 'wêreldwye parameters'
ewekansige toegang: '(arbitrêr | onreëlmatig) kry reg van deurgang na'
ewekansige woud: '(arbitrêr | onreëlmatig) (agterbos | houtland | welige gebied)'
ewekansige waarde: '(arbitrêre | onreëlmatige) agting'
mierkolonie: 'ondergrondse insek (staat | provinsie | gebied | streek | nedersetting)'
mierkolonie: 'ondergrondse grillerige kruip (staat | provinsie | gebied | streek | nedersetting)'
oorblywende energie: 'oorskiet vitaliteit'
kinetiese energie: 'motoriese vitaliteit'
naïewe Bayes: '(gelowig | onskuldig | liggelowige) Bayes'
persoonlike digitale assistent (PDA): 'individuele gerekenariseerde medewerker'
In Mei 2021 het die navorsers die dimensies akademiese soekenjin op soek na hierdie soort verminkte, geoutomatiseerde taal, en sorg dat wettige frases soos 'enorme inligting' (wat 'n geldige frase is, en nie 'n mislukte sinoniem vir 'groot data') uitsluit nie. Op hierdie stadium het hulle dit waargeneem Mikroverwerkers en mikrosisteme die hoogste aantal gevalle van mishanteerde parafrasering gehad.
Op die oomblik is dit steeds moontlik om haal (argief momentopname, 15/07/2021) 'n aantal wetenskaplike referate vir die onsinnige frase 'diep neurale organisasie' (dws 'diep neurale netwerk'), en ander in die bogenoemde lys lewer soortgelyke trefslae op.
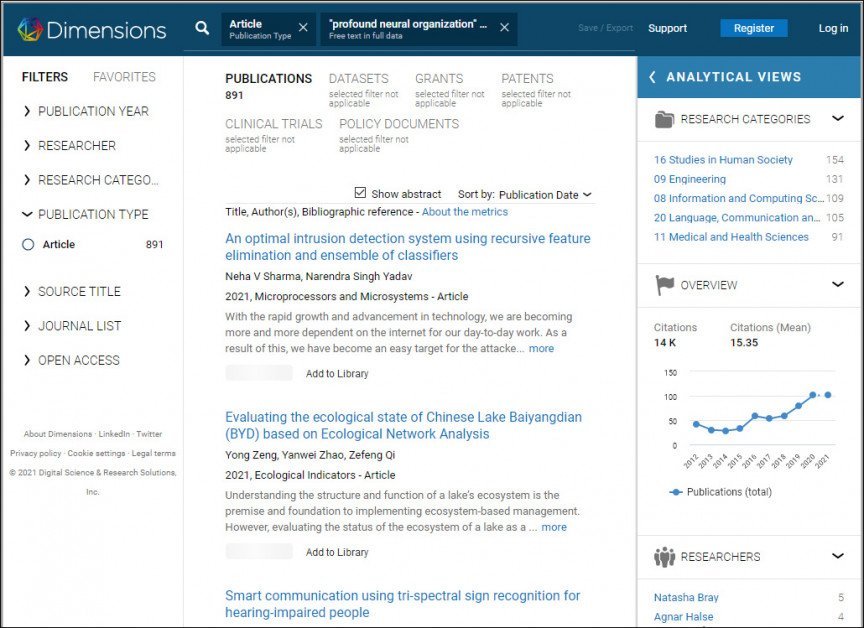
Soekresultate vir 'diep neurale organisasie' ('diep neurale netwerk') by Dimensions. Bron: https://app.dimensions.ai/
Die mikroverwerkers tydskrif is in 1976 gestig en herdoop na Mikroverwerkers en mikrosisteme twee jaar later.
'n Groei van nonsenstaal
Die navorsers het 'n tydperk van Februarie 2018 tot Junie 2021 bestudeer en 'n skerp styging in die volume voorleggings oor die afgelope twee jaar, en veral oor die afgelope 6-8 maande, waargeneem:
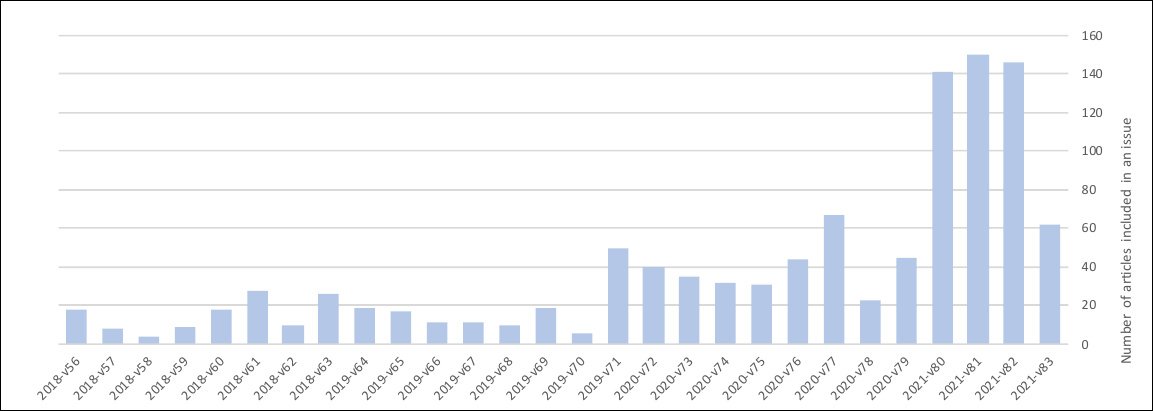
Korrelasie of oorsaaklikheid? Die toename in voorleggings aan die mikroverwerkers en mikrostelsels-joernaal blyk saam te val met die groei van 'nonsens' teks en sinonieme in oënskynlik respekvolle voorleggings. Bron: https://arxiv.org/pdf/2107.06751.pdf
Die finale datastel wat deur die medewerkers ingesamel is, bevat 1,078 XNUMX vollengte artikels wat verkry is via die Elsevier-intekening van die Universiteit van Toulouse.
Afnemende redaksionele toesig vir Chinese wetenskaplike referate
Die koerant merk op dat die tydperk wat vir redaksionele beoordeling van die gevlagde voorleggings toegeken word, in 2021 radikaal verkort word, en daal tot onder 40 dae; 'n sesvoudige afname in die standaardtyd vir portuurbeoordeling, duidelik vanaf Februarie 2021.
Die grootste aantal gemerkte referate kom van skrywers met affiliasies aan die vasteland van China: uit 404 vraestelle wat in minder as 30 dae aanvaar is, is 97.5% China-verwant. Omgekeerd, in gevalle waar die redaksionele proses 40 dae oorskry het (615 vraestelle), verteenwoordig China-geaffilieerde voorleggings slegs 9.5% van daardie kategorie – 'n tienvoudige wanbalans.
Die verslag skryf die infiltrasie van die gemerkte koerante toe aan tekortkominge in die redaksionele proses, en 'n moontlike gebrek aan hulpbronne in die lig van 'n groeiende aantal voorleggings.
Die navorsers veronderstel dat GPT-styl generatiewe modelle, en soortgelyke tipes taalgenereringsraamwerke, gebruik is om baie van die teks in die gemerkte vraestelle te produseer; die manier waarop 'n generatiewe model sy bronne abstraheer maak dit egter moeilik om te bewys, en die hoofgetuienis lê in 'n gesonde verstand-evaluering van swak en onnodige sinonieme, en 'n noukeurige ondersoek van die voorlegging se logiese samehang.
Die navorsers neem verder waar dat die generatiewe taalmodelle wat hulle glo tot hierdie stortvloed van onsin bydra nie net in staat is om die problematiese tekste te skep nie, maar ook om dit te herken en sistematies te vlag, op dieselfde manier as wat die navorsers self uitgevoer het. handmatig. Die werk gee besonderhede oor so 'n implementering, met behulp van GPT-2, en bied 'n raamwerk vir toekomstige stelsels om problematiese wetenskaplike voorleggings te identifiseer.
Die voorkoms van 'besoedelde' voorleggings is baie hoër in die Elsevier-joernaal (72.1%) in vergelyking met ander joernale wat bestudeer is (maksimum 13.6%).
Nie net semantiek nie
Die navorsers beklemtoon dat baie van die betrokke joernale nie bloot die verkeerde taal gebruik nie, maar wetenskaplik onakkurate stellings bevat, wat die moontlikheid aandui dat generatiewe taalmodelle nie net gebruik word om die beperkte taalvaardighede van bydraende wetenskaplikes te verbeter nie, maar kan eintlik word gebruik om ten minste sommige van die kernstellings en data in die vraestel te formuleer.
In ander gevalle stel die navorsers 'n effektiewe 'hersintese' of 'spin' van geabstraheerde (en voortreflike) vorige werk, ten einde die druk van 'publiseer of vergaan' akademiese navorsingskulture te ontmoet, en moontlik om nasionale ranglys vir globale pre- uitnemendheid in KI-navorsing, deur blote volume.

Onsinnige inhoud in 'n voorgelê vraestel. In hierdie geval het die navorsers gevind dat die teks ad hoc afgelei is van 'n EDN artikel, vanwaar die meegaande illustrasie ook sonder toeskrywing gesteel word. Die herskryf van die oorspronklike inhoud is so ekstreem dat dit betekenisloos maak.
Deur verskeie van die Elsevier-referate te ontleed, het die navorsers sinne gevind waarvoor hulle nie enige betekenis kon aflei nie; verwysings na nie-bestaande literatuur; verwysings na veranderlikes en stellings in formules wat nie werklik in die ondersteunende materiaal verskyn het nie (wat taalgebaseerde abstraksie voorstel, of 'hallucinatie' van skynbaar feitelike data); en hergebruik van beelde met geen erkenning van hul bronne nie (wat die navorsers nie uit 'n kopiereg-oogpunt kritiseer nie, maar eerder as 'n aanduiding van onvoldoende wetenskaplike strengheid).
Aanhalingsmislukkings
Daar is gevind dat die aanhalings wat bedoel is om die argumente in 'n wetenskaplike artikel te ondersteun in baie van die gevlagde voorbeelde 'óf gebroke óf lei tot onverwante publikasies'.
Daarbenewens sluit verwysings na 'verwante werk' blykbaar dikwels skrywers in wat die navorsers glo deur 'n GPT-styl stelsel 'gehallusineer' is.
Dwaal aandag
Nog 'n tekortkoming van selfs die nuutste taalmodelle soos GPT-3 is hul neiging om fokus te verloor oor 'n lang diskoers. Die navorsers het bevind dat die gemerkte referate dikwels vroeg in die referaat 'n onderwerp aanroer waarna eintlik nooit teruggekeer word nadat dit aanvanklik in voorlopige aantekeninge of elders aan die orde gestel is nie.
Hulle teoretiseer ook dat sommige van die ergste voorbeelde plaasvind deur verskeie reise van bronteks deur 'n reeks vertaalenjins, wat elkeen die betekenis verder verdraai.
Bronne en redes
In 'n poging om te onderskei wat agter hierdie verskynsel skuil, stel die skrywers van die koerant 'n aantal moontlikhede voor: dat inhoud van papierfabrieke word as bronmateriaal gebruik, wat onakkuraathede baie vroeg in 'n proses bekendstel wat onvermydelik verdere onakkuraathede sal veroorsaak; dat artikelspingereedskap soos Spinbot gebruik word om plagiaat te masker; en dat die oorweldigende druk om gereeld te publiseer daartoe lei dat navorsers met gebrekkige hulpbronne GPT-3-styl stelsels gebruik om óf aan te vul óf heeltemal nuwe akademiese referate te genereer.
Die navorsers sluit af met 'n oproep tot aksie vir groter toesig en verbeterde standaarde in 'n gebied van akademiese uitgewery wat blykbaar die voer vir sy eie vakmateriaal word - masjienleerstelsels. Hulle sweer Elsevier en ander uitgewers ook om strenger siftings- en hersieningsprosedures in te stel, en kritiseer breedweg huidige standaarde en praktyke in hierdie verband, en stel voor dat 'Misleiding met sintetiese tekste bedreig die integriteit van die wetenskaplike literatuur.'















