Góc nhìn Anderson
Tại Sao Các Cuộc Tấn Công Hình Ảnh Adversarial Không Phải Là Một Trò Đùa
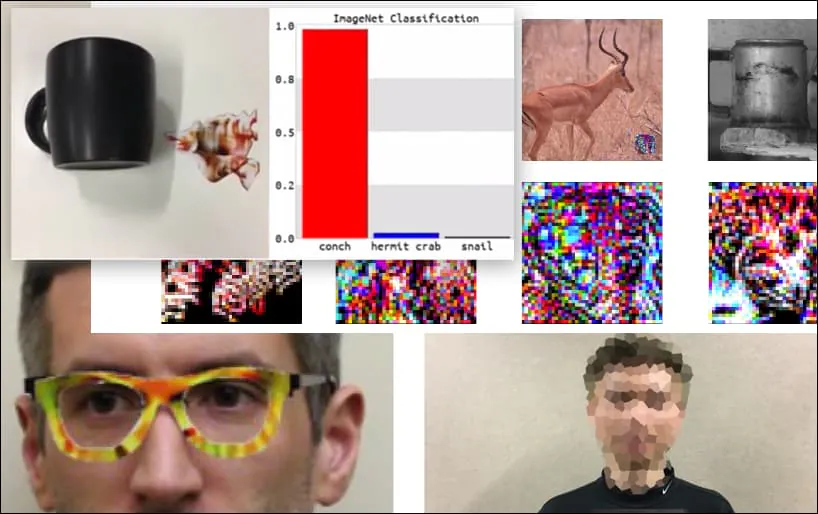
Đánh vào các hệ thống nhận dạng hình ảnh bằng cách sử dụng các hình ảnh đối kháng được tạo ra một cách cẩn thận đã được coi là một概念 chứng minh nhưng không quan trọng trong năm năm qua. Tuy nhiên, nghiên cứu mới từ Úc cho thấy rằng việc sử dụng rộng rãi các tập dữ liệu hình ảnh phổ biến cho các dự án AI thương mại có thể tạo ra một vấn đề bảo mật mới.
Trong vài năm qua, một nhóm các nhà nghiên cứu tại Đại học Adelaide đã cố gắng giải thích một điều gì đó rất quan trọng về tương lai của các hệ thống nhận dạng hình ảnh dựa trên AI.
Điều đó sẽ rất khó (và rất tốn kém) để sửa chữa ngay bây giờ, và sẽ rất tốn kém để khắc phục một khi các xu hướng hiện tại trong nghiên cứu nhận dạng hình ảnh đã được phát triển đầy đủ vào các triển khai thương mại và công nghiệp trong 5-10 năm tới.
Trước khi chúng ta đi vào chi tiết, hãy xem một bông hoa được phân loại là Tổng thống Barack Obama, từ một trong sáu video mà nhóm đã xuất bản trên trang dự án:
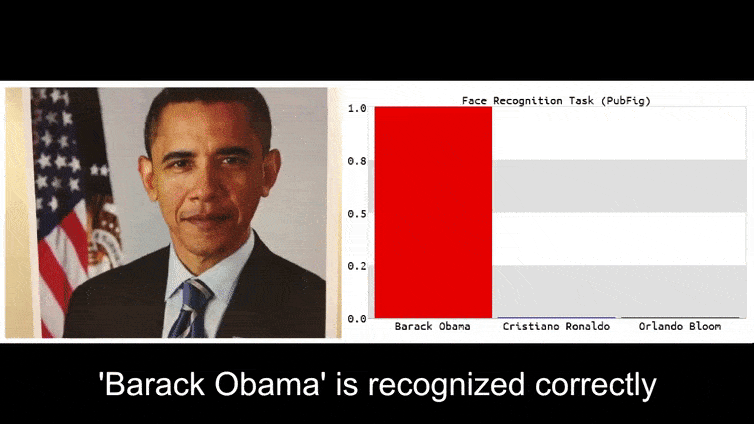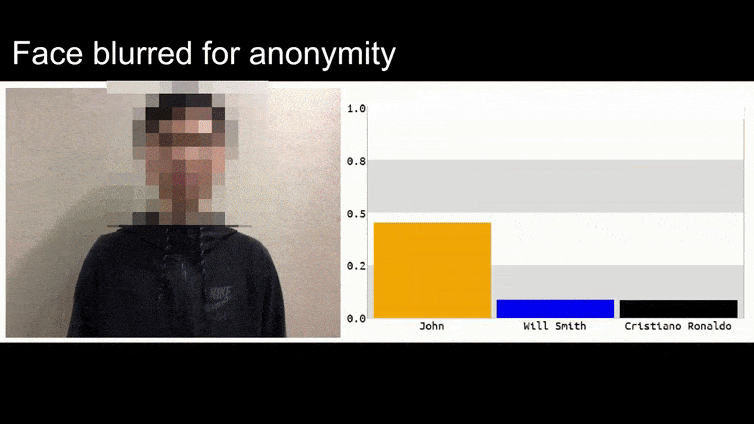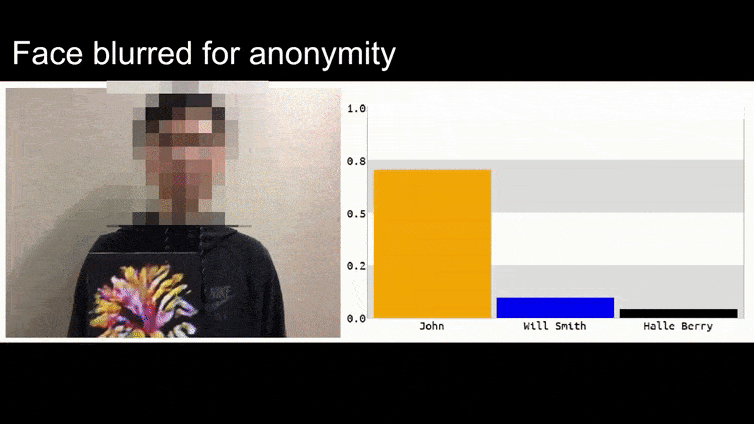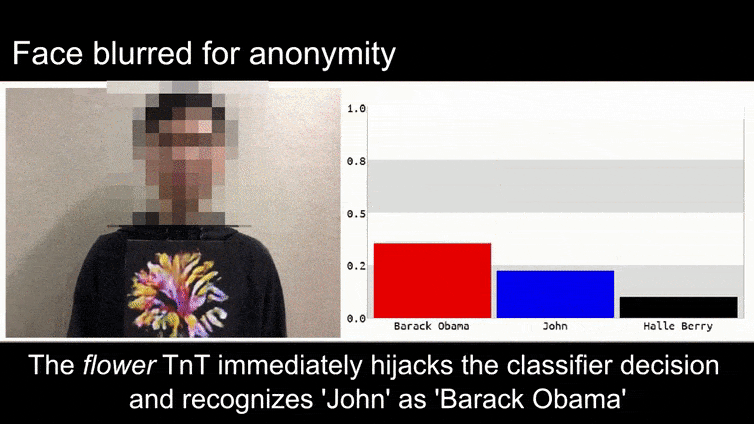
Source: https://www.youtube.com/watch?v=Klepca1Ny3c
Trong hình ảnh trên, một hệ thống nhận dạng khuôn mặt rõ ràng biết cách nhận dạng Barack Obama bị đánh lừa với độ chắc chắn 80% rằng một người đàn ông vô danh cầm một hình ảnh đối kháng được tạo ra và in ra của một bông hoa cũng là Barack Obama. Hệ thống không quan tâm đến việc “khuôn mặt giả” nằm trên ngực của đối tượng, thay vì trên vai.
Mặc dù các nhà nghiên cứu đã có thể thực hiện được loại tấn công này bằng cách tạo ra một hình ảnh hợp lý (một bông hoa) thay vì chỉ tiếng ồn ngẫu nhiên, nhưng dường như những cuộc tấn công như thế này xuất hiện khá thường xuyên trong nghiên cứu bảo mật về tầm nhìn máy tính. Ví dụ, những chiếc kính có họa tiết kỳ lạ có thể đánh lừa nhận dạng khuôn mặt vào năm 2016, hoặc các hình ảnh đối kháng được tạo ra một cách đặc biệt có thể thay đổi ý nghĩa của biển báo đường.
Nếu bạn quan tâm, mô hình CNN được tấn công trong ví dụ trên là VGGFace (VGG-16), được đào tạo trên tập dữ liệu PubFig của Đại học Columbia. Các mẫu tấn công khác được phát triển bởi các nhà nghiên cứu sử dụng các tài nguyên khác nhau trong các kết hợp khác nhau.

Source: https://www.youtube.com/watch?v=dhTTjjrxIcU
Nhận Dạng Hình Ảnh Là Một Vector Tấn Công Mới
Các cuộc tấn công ấn tượng mà các nhà nghiên cứu phác thảo và minh họa không phải là những lời chỉ trích về các tập dữ liệu hoặc kiến trúc học máy cụ thể mà sử dụng chúng. Chúng cũng không thể được bảo vệ dễ dàng bằng cách chuyển đổi tập dữ liệu hoặc mô hình, hoặc bằng cách đào tạo lại mô hình, hoặc bằng cách sử dụng các biện pháp “đơn giản” khác mà các kỹ sư học máy thường coi thường các cuộc tấn công này.
Thay vào đó, các cuộc tấn công của nhóm Adelaide thể hiện một điểm yếu trung tâm trong toàn bộ kiến trúc hiện tại của phát triển AI nhận dạng hình ảnh; một điểm yếu có thể khiến nhiều hệ thống nhận dạng hình ảnh trong tương lai dễ bị thao túng bởi các cuộc tấn công, và khiến các biện pháp phòng thủ sau này gặp khó khăn.
Hãy tưởng tượng các hình ảnh đối kháng mới nhất (như bông hoa trên) được thêm vào các hệ thống bảo mật trong tương lai như các “zero-day exploits”, giống như các framework chống vi-rút và chống malware hiện tại cập nhật các định nghĩa vi-rút mỗi ngày.
Khả năng tấn công hình ảnh đối kháng mới sẽ là vô tận, vì kiến trúc cơ bản của hệ thống không dự kiến các vấn đề hạ nguồn, như đã xảy ra với internet, lỗi Millennium Bug và tháp nghiêng Pisa.
Lấy Dữ Liệu Cho Một Cuộc Tấn Công
Các hình ảnh đối kháng như ví dụ “bông hoa” trên được tạo ra bằng cách có quyền truy cập vào các tập dữ liệu hình ảnh đã đào tạo các mô hình máy tính. Bạn không cần “quyền truy cập đặc biệt” vào dữ liệu đào tạo (hoặc kiến trúc mô hình), vì các tập dữ liệu phổ biến nhất (và nhiều mô hình đã đào tạo) đều có sẵn trong một luồng torrent mạnh và liên tục cập nhật.
Ví dụ, tập dữ liệu Goliath của tầm nhìn máy tính, ImageNet, có sẵn trên Torrent trong tất cả các phiên bản của nó, vượt qua các hạn chế thông thường của nó, và cung cấp các yếu tố thứ cấp quan trọng, chẳng hạn như tập hợp xác thực.

Source: https://academictorrents.com
Nếu bạn có dữ liệu, bạn có thể (như các nhà nghiên cứu Adelaide quan sát) “ngược lại” bất kỳ tập dữ liệu phổ biến nào, chẳng hạn như CityScapes, hoặc CIFAR.
Trong trường hợp PubFig, tập dữ liệu đã cho phép “bông hoa Obama” trong ví dụ trước, Đại học Columbia đã giải quyết một xu hướng ngày càng tăng về các vấn đề bản quyền xung quanh việc phân phối lại tập dữ liệu hình ảnh bằng cách hướng dẫn các nhà nghiên cứu cách tái tạo tập dữ liệu thông qua các liên kết được kiểm soát, thay vì cung cấp trực tiếp tập hợp, quan sát ‘Điều này dường như là cách các cơ sở dữ liệu lớn dựa trên web khác đang phát triển’.
Trong hầu hết các trường hợp, điều đó không cần thiết: Kaggle ước tính rằng mười tập dữ liệu hình ảnh phổ biến nhất trong tầm nhìn máy tính là: CIFAR-10 và CIFAR-100 (cả hai có thể tải xuống trực tiếp); CALTECH-101 và 256 (cả hai có sẵn, và cả hai hiện có sẵn dưới dạng torrent); MNIST (có sẵn chính thức, cũng trên torrent); ImageNet (xem trên); Pascal VOC (có sẵn, cũng trên torrent); MS COCO (có sẵn, và trên torrent); Sports-1M (có sẵn); và YouTube-8M (có sẵn).
Sự sẵn có này cũng đại diện cho phạm vi rộng hơn của các tập dữ liệu hình ảnh máy tính có sẵn, vì sự không rõ ràng là cái chết trong một văn hóa phát triển nguồn mở “xuất bản hoặc tiêu diệt”.
Phê Bình Thông Thường Của Các Phương Pháp Tấn Công Hình Ảnh Đối Kháng
Lời chỉ trích thường xuyên và dai dẳng nhất của các kỹ sư học máy về hiệu quả của kỹ thuật tấn công hình ảnh đối kháng mới nhất là rằng cuộc tấn công là riêng cho một tập dữ liệu cụ thể, một mô hình cụ thể, hoặc cả hai; rằng nó không “tổng quát hóa” cho các hệ thống khác; và do đó, chỉ đại diện cho một mối đe dọa nhỏ.
Lời chỉ trích thứ hai thường gặp nhất là rằng cuộc tấn công hình ảnh đối kháng là ‘hộp trắng’, có nghĩa là bạn sẽ cần truy cập trực tiếp vào môi trường đào tạo hoặc dữ liệu. Điều này thực sự là một kịch bản không thể xảy ra trong hầu hết các trường hợp – ví dụ, nếu bạn muốn khai thác quá trình đào tạo cho các hệ thống nhận dạng khuôn mặt của Cảnh sát Thủ đô London, bạn sẽ phải xâm nhập vào NEC, hoặc bằng cách sử dụng máy tính hoặc rìu.
‘DNA’ Dài Hạn Của Các Tập Dữ Liệu Tầm Nhìn Máy Tính Phổ Biến
Về lời chỉ trích đầu tiên, chúng ta nên xem xét không chỉ rằng một số ít tập dữ liệu tầm nhìn máy tính thống trị ngành công nghiệp theo từng lĩnh vực hàng năm (tức là ImageNet cho nhiều loại đối tượng, CityScapes cho các cảnh lái xe, và FFHQ cho nhận dạng khuôn mặt); mà còn rằng, như dữ liệu hình ảnh được chú thích đơn giản, chúng là “nền tảng trung lập” và có thể chuyển đổi cao.
Tùy thuộc vào khả năng của nó, bất kỳ kiến trúc đào tạo tầm nhìn máy tính nào cũng sẽ tìm thấy một số tính năng của các đối tượng và lớp trong tập dữ liệu ImageNet. Một số kiến trúc có thể tìm thấy nhiều tính năng hơn những kiến trúc khác, hoặc tạo ra nhiều kết nối hữu ích hơn những kiến trúc khác, nhưng tất cả nên tìm thấy ít nhất các tính năng cấp cao:

Dữ liệu ImageNet, với số lượng nhận dạng chính xác tối thiểu – các tính năng ‘cấp cao’.
Đó là những “tính năng cấp cao” phân biệt và “dấu vân tay” một tập dữ liệu, và chúng là những “móc” đáng tin cậy để treo một phương pháp tấn công hình ảnh đối kháng dài hạn có thể vượt qua các hệ thống khác nhau và phát triển cùng với “tập dữ liệu cũ” khi tập dữ liệu đó được tiếp tục trong các sản phẩm và nghiên cứu mới.
Một kiến trúc phức tạp hơn sẽ tạo ra các nhận dạng chính xác và chi tiết hơn, tính năng và lớp:

Tuy nhiên, càng nhiều tấn công hình ảnh đối kháng phụ thuộc vào các tính năng thấp hơn (tức là “Nam giới da trắng trẻ” thay vì “Khuôn mặt”), tấn công sẽ càng kém hiệu quả trong các kiến trúc chéo hoặc sau này sử dụng phiên bản khác của tập dữ liệu ban đầu – chẳng hạn như một tập hợp con hoặc tập hợp được lọc, nơi nhiều hình ảnh ban đầu từ tập dữ liệu đầy đủ không có mặt:

Các Cuộc Tấn Công Đối Kháng Trên Các Mô Hình ‘Zeroed’, Đã Được Đào Tạo Trước
Vậy những trường hợp bạn chỉ tải xuống một mô hình đã được đào tạo trước và cung cấp cho nó dữ liệu mới?
Mô hình đã được đào tạo trên (ví dụ) ImageNet, và tất cả những gì còn lại là trọng số, có thể đã mất vài tuần hoặc vài tháng để đào tạo, và bây giờ đã sẵn sàng để giúp bạn nhận dạng các đối tượng tương tự như những đối tượng đã tồn tại trong dữ liệu ban đầu (hiện không có).

Với dữ liệu ban đầu bị xóa khỏi kiến trúc đào tạo, những gì còn lại là ‘sự sẵn sàng’ của mô hình để phân loại các đối tượng theo cách mà nó đã học để làm, điều này sẽ khiến nhiều ‘chữ ký’ ban đầu tái tạo và trở nên dễ bị tổn thương một lần nữa bởi các phương pháp tấn công hình ảnh đối kháng cũ.
Các trọng số đó rất quý giá. Không có dữ liệu hoặc trọng số, bạn cơ bản có một kiến trúc trống không có dữ liệu. Bạn sẽ phải đào tạo lại từ đầu, với chi phí thời gian và tài nguyên tính toán lớn, giống như các tác giả ban đầu đã làm (có thể trên phần cứng mạnh hơn và với ngân sách cao hơn so với bạn).
Vấn đề là trọng số đã được hình thành khá tốt và có khả năng chống lại sự thay đổi. Mặc dù chúng sẽ thích nghi một chút trong quá trình đào tạo, nhưng chúng sẽ hành xử tương tự trên dữ liệu mới như chúng đã làm trên dữ liệu ban đầu, tạo ra các tính năng đặc trưng mà một hệ thống tấn công hình ảnh đối kháng có thể dựa vào.
Không Cần ‘Hộp Trắng’
Về lời chỉ trích thứ hai của các phương pháp tấn công hình ảnh đối kháng, các tác giả của bài báo mới đã tìm thấy rằng khả năng đánh lừa các hệ thống nhận dạng với các hình ảnh đối kháng được tạo ra là có thể chuyển đổi cao trên nhiều kiến trúc.
Khi quan sát rằng phương pháp “Universal NaTuralistic adversarial paTches” (TnT) của họ là phương pháp đầu tiên sử dụng các hình ảnh nhận biết được (thay vì nhiễu loạn ngẫu nhiên) để đánh lừa các hệ thống nhận dạng hình ảnh, các tác giả cũng tuyên bố:
‘[TnTs] hiệu quả đối với nhiều bộ phân loại hàng đầu hiện nay, từ WideResNet50 được sử dụng rộng rãi trong nhiệm vụ Nhận dạng Hình ảnh Cấp độ Lớn của tập dữ liệu ImageNet đến các mô hình VGG-face trong nhiệm vụ nhận dạng khuôn mặt của tập dữ liệu PubFig, cả trong các cuộc tấn công định hướng và không định hướng.’
‘TnTs có thể có: i) sự tự nhiên có thể đạt được [với] các kích hoạt được sử dụng trong các phương pháp tấn công Trojan; và ii) sự tổng quát hóa và khả năng chuyển đổi của các ví dụ đối kháng đến các mạng khác.
‘Điều này làm dấy lên các lo ngại về an toàn và bảo mật liên quan đến các DNN đã được triển khai cũng như các triển khai DNN trong tương lai, nơi các kẻ tấn công có thể sử dụng các miếng vá đối kháng tự nhiên để đánh lừa các hệ thống mạng nơ-ron mà không cần can thiệp vào mô hình và rủi ro bị phát hiện.’
Các tác giả đề xuất rằng các biện pháp đối phó thông thường, chẳng hạn như làm giảm độ chính xác của mạng, có thể cung cấp một số biện pháp phòng thủ chống lại các miếng vá TnT, nhưng rằng ‘TnTs vẫn có thể vượt qua các biện pháp phòng thủ này với hầu hết các hệ thống phòng thủ đạt được 0% độ bền’.
Các giải pháp có thể khác bao gồm học liên bang, nơi nguồn gốc của các hình ảnh đóng góp được bảo vệ, và các phương pháp mới có thể mã hóa trực tiếp dữ liệu trong quá trình đào tạo, chẳng hạn như một phương pháp gần đây được đề xuất bởi Đại học Hàng không và Vũ trụ Nam Kinh.
Kết Luận
Các cuộc tấn công hình ảnh đối kháng đang được thực hiện không chỉ bởi các phương pháp học máy nguồn mở, mà còn bởi một văn hóa phát triển AI doanh nghiệp được thúc đẩy để tái sử dụng các tập dữ liệu tầm nhìn máy tính phổ biến vì một số lý do: chúng đã chứng minh hiệu quả; chúng rẻ hơn nhiều so với “bắt đầu từ đầu”; và chúng được duy trì và cập nhật bởi các tâm trí và tổ chức tiên phong trong học thuật và ngành công nghiệp, ở mức tài trợ và nhân viên mà một công ty đơn lẻ sẽ khó có thể复制.
Thêm vào đó, trong nhiều trường hợp mà dữ liệu không phải là ban đầu (không giống như CityScapes), các hình ảnh đã được thu thập trước khi có các cuộc tranh cãi gần đây về các vấn đề quyền riêng tư và thu thập dữ liệu, để lại các tập dữ liệu cũ trong một loại purgatory bán pháp lý có thể trông giống như một “thiên đường an toàn” từ góc độ của một công ty.
TnT Attacks! Universal Naturalistic Adversarial Patches Against Deep Neural Network Systems được đồng tác giả bởi Bao Gia Doan, Minhui Xue, Ehsan Abbasnejad, Damith C. Ranasinghe từ Đại học Adelaide, cùng với Shiqing Ma từ Bộ phận Khoa học Máy tính tại Đại học Rutgers.
Đã cập nhật 1st tháng 12 2021, 7:06am GMT+2 – corrected typo.












