AI 101
Linear Regression là gì?
Linear Regression là gì?
Linear regression là một thuật toán được sử dụng để dự đoán, hoặc trực quan hóa, một mối quan hệ giữa hai tính năng / biến khác nhau. Trong các nhiệm vụ linear regression, có hai loại biến được kiểm tra: biến phụ thuộc và biến độc lập. Biến độc lập là biến tự đứng alone, không bị ảnh hưởng bởi biến khác. Khi biến độc lập được điều chỉnh, mức độ của biến phụ thuộc sẽ thay đổi. Biến phụ thuộc là biến được nghiên cứu, và nó là những gì mô hình hồi quy cố gắng giải quyết / dự đoán. Trong các nhiệm vụ linear regression, mỗi quan sát / thể hiện bao gồm cả giá trị biến phụ thuộc và giá trị biến độc lập.
Đó là một lời giải thích nhanh về linear regression, nhưng hãy đảm bảo chúng ta hiểu rõ hơn về linear regression bằng cách xem xét một ví dụ về nó và kiểm tra công thức mà nó sử dụng.
Hiểu Linear Regression
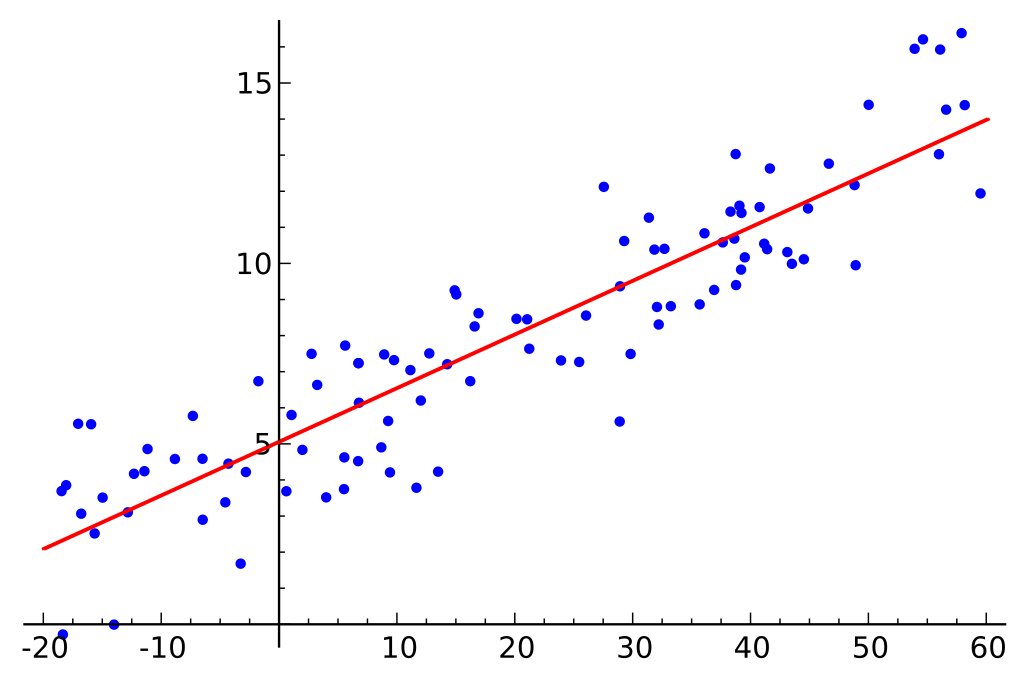
Giả sử chúng ta có một tập dữ liệu bao gồm kích thước ổ cứng và chi phí của chúng.
Hãy giả sử rằng tập dữ liệu chúng ta có bao gồm hai tính năng khác nhau: lượng bộ nhớ và chi phí. Khi chúng ta mua nhiều bộ nhớ hơn cho một máy tính, chi phí của mua hàng sẽ tăng lên. Nếu chúng ta vẽ các điểm dữ liệu riêng lẻ trên một biểu đồ phân tán, chúng ta có thể nhận được một biểu đồ trông giống như này:

Tỷ lệ chính xác giữa bộ nhớ và chi phí có thể khác nhau giữa các nhà sản xuất và mẫu ổ cứng, nhưng nói chung, xu hướng của dữ liệu là một xu hướng bắt đầu từ góc dưới bên trái (ở đó ổ cứng rẻ hơn và có dung lượng nhỏ hơn) và di chuyển đến góc trên bên phải (ở đó ổ cứng đắt hơn và có dung lượng cao hơn).
Nếu chúng ta có lượng bộ nhớ trên trục X và chi phí trên trục Y, một đường thẳng捕 mối quan hệ giữa biến X và Y sẽ bắt đầu từ góc dưới bên trái và chạy đến góc trên bên phải.

Chức năng của một mô hình hồi quy là xác định một hàm tuyến tính giữa biến X và Y mô tả mối quan hệ giữa hai biến. Trong linear regression, nó được giả định rằng Y có thể được tính toán từ một sự kết hợp của các biến đầu vào. Mối quan hệ giữa các biến đầu vào (X) và các biến mục tiêu (Y) có thể được mô tả bằng cách vẽ một đường thẳng qua các điểm trong biểu đồ. Đường thẳng đại diện cho hàm mô tả mối quan hệ giữa X và Y (ví dụ, mỗi khi X tăng 3, Y tăng 2). Mục tiêu là tìm một “đường hồi quy” tối ưu, hoặc đường thẳng / hàm mô tả mối quan hệ giữa X và Y.
Các đường thẳng thường được biểu diễn bởi phương trình: Y = m * X + b. X đề cập đến biến độc lập trong khi Y là biến phụ thuộc. Trong khi đó, m là độ dốc của đường thẳng, được định nghĩa bởi “độ tăng” trên “độ chạy”. Các nhà thực hành học máy đại diện cho phương trình đường thẳng nổi tiếng một chút khác, sử dụng phương trình này thay thế:
y(x) = w0 + w1 * x
Trong phương trình trên, y là biến mục tiêu trong khi “w” là tham số của mô hình và đầu vào là “x”. Vì vậy phương trình được đọc là: “Hàm trả về Y, tùy thuộc vào X, bằng với tham số của mô hình nhân với các tính năng”. Các tham số của mô hình được điều chỉnh trong quá trình đào tạo để nhận được đường hồi quy phù hợp nhất.
Hồi Quy Tuyến Tính Đa Biến

Photo: Cbaf via Wikimedia Commons, Public Domain (https://commons.wikimedia.org/wiki/File:2d_multiple_linear_regression.gif)
Quá trình được mô tả ở trên áp dụng cho hồi quy tuyến tính đơn giản, hoặc hồi quy trên các tập dữ liệu nơi chỉ có một tính năng / biến độc lập. Tuy nhiên, một hồi quy cũng có thể được thực hiện với nhiều tính năng. Trong trường hợp của “hồi quy tuyến tính đa biến“, phương trình được mở rộng bởi số lượng biến trong tập dữ liệu. Nói cách khác, trong khi phương trình cho hồi quy tuyến tính thông thường là y(x) = w0 + w1 * x, phương trình cho hồi quy tuyến tính đa biến sẽ là y(x) = w0 + w1x1 cộng với trọng số và đầu vào cho các tính năng khác nhau. Nếu chúng ta đại diện cho tổng số trọng số và tính năng là w(n)x(n), thì chúng ta có thể đại diện cho công thức như này:
y(x) = w0 + w1x1 + w2x2 + … + w(n)x(n)
Sau khi thiết lập công thức cho hồi quy tuyến tính, mô hình học máy sẽ sử dụng các giá trị khác nhau cho trọng số, vẽ các đường phù hợp khác nhau. Hãy nhớ rằng mục tiêu là tìm đường thẳng phù hợp nhất với dữ liệu để xác định mối quan hệ giữa các biến.
Một hàm chi phí được sử dụng để đo lường mức độ gần giữa các giá trị Y giả định và các giá trị Y thực khi cho một trọng số cụ thể. Hàm chi phí cho hồi quy tuyến tính là sai số trung bình bình phương, chỉ lấy trung bình (sai số bình phương) giữa giá trị dự đoán và giá trị thực cho tất cả các điểm dữ liệu trong tập dữ liệu. Hàm chi phí được sử dụng để tính toán một chi phí, nắm bắt sự khác biệt giữa giá trị mục tiêu dự đoán và giá trị mục tiêu thực. Nếu đường thẳng phù hợp xa khỏi các điểm dữ liệu, chi phí sẽ cao hơn, trong khi chi phí sẽ trở nên nhỏ hơn khi đường thẳng đến gần hơn với việc nắm bắt mối quan hệ thực giữa các biến. Trọng số của mô hình sau đó được điều chỉnh cho đến khi cấu hình trọng số tạo ra ít sai số nhất được tìm thấy.








