
Trí tuệ nhân tạo
Ba thách thức phía trước để khuếch tán ổn định

phát hành của Stable Diffusion của stability.ai khuếch tán tiềm ẩn mô hình tổng hợp hình ảnh vài tuần trước có thể là một trong những tiết lộ công nghệ quan trọng nhất kể từ DeCSS năm 1999; chắc chắn đây là sự kiện lớn nhất về hình ảnh do AI tạo ra kể từ năm 2017 mã deepfake đã được sao chép sang GitHub và rẽ nhánh thành thứ sẽ trở thành DeepFaceLab và Hoán đổi khuôn mặt, cũng như phần mềm deepfake phát trực tuyến theo thời gian thực DeepFaceSống.
Tại một cơn đột quỵ, sự thất vọng của người dùng qua hạn chế nội dung trong API tổng hợp hình ảnh của DALL-E 2 đã bị gạt sang một bên, vì bộ lọc NSFW của Stable Diffusion có thể bị vô hiệu hóa bằng cách thay đổi dòng mã duy nhất. Các Reddit về Khuếch tán Ổn định lấy nội dung khiêu dâm làm trung tâm xuất hiện gần như ngay lập tức và cũng nhanh chóng bị cắt giảm, trong khi nhóm nhà phát triển và người dùng chia Discord thành các cộng đồng chính thức và NSFW, và Twitter bắt đầu tràn ngập các sáng tạo Khuếch tán Ổn định tuyệt vời.
Hiện tại, mỗi ngày dường như mang lại một số đổi mới đáng kinh ngạc từ các nhà phát triển đã áp dụng hệ thống, với các plugin và phần bổ sung của bên thứ ba được viết vội vàng cho Krita, Photoshop, Cinema4D, Máy xay sinh tố, và nhiều nền tảng ứng dụng khác.

Trong khi đó, thủ công nhanh chóng – nghệ thuật chuyên nghiệp hiện nay là 'thầm thì với AI', có thể trở thành lựa chọn nghề nghiệp ngắn nhất kể từ 'bìa Filofax' – đang trở nên thương mại hóa, trong khi quá trình kiếm tiền sớm của Khuếch tán ổn định đang diễn ra tại cấp độ patreon, với sự chắc chắn sẽ có nhiều dịch vụ phức tạp hơn, dành cho những người không muốn điều hướng dựa trên conda lượt cài đặt mã nguồn hoặc bộ lọc NSFW theo quy định của các triển khai dựa trên web.
Tốc độ phát triển và khả năng khám phá tự do của người dùng đang diễn ra với tốc độ chóng mặt đến mức khó có thể nhìn xa trông rộng. Về cơ bản, chúng ta vẫn chưa biết chính xác mình đang đối mặt với điều gì, hay những hạn chế hay khả năng nào có thể xảy ra.
Tuy nhiên, hãy cùng xem xét ba trong số những rào cản thú vị và đầy thách thức nhất mà cộng đồng Stable Diffusion đang hình thành và phát triển nhanh chóng phải đối mặt và hy vọng có thể vượt qua.
1: Tối ưu hóa đường ống dựa trên ô vuông
Với tài nguyên phần cứng hạn chế và giới hạn cứng đối với độ phân giải của hình ảnh đào tạo, có vẻ như các nhà phát triển sẽ tìm ra giải pháp thay thế để cải thiện cả chất lượng và độ phân giải của đầu ra Khuếch tán ổn định. Rất nhiều dự án trong số này được thiết lập để liên quan đến việc khai thác các hạn chế của hệ thống, chẳng hạn như độ phân giải gốc của nó chỉ là 512 × 512 pixel.
Như thường lệ với các sáng kiến tổng hợp hình ảnh và thị giác máy tính, Khuếch tán ổn định được đào tạo trên các hình ảnh có tỷ lệ vuông, trong trường hợp này được lấy mẫu lại thành 512×512 để hình ảnh nguồn có thể được điều chỉnh và có thể phù hợp với các hạn chế của GPU đã đào tạo người mẫu.
Do đó, Stable Diffusion "suy nghĩ" (nếu nó có suy nghĩ) theo tỷ lệ 512×512, và chắc chắn là theo tỷ lệ bình phương. Nhiều người dùng hiện đang thăm dò giới hạn của hệ thống báo cáo rằng Stable Diffusion tạo ra kết quả đáng tin cậy nhất và ít lỗi nhất ở tỷ lệ khung hình khá hạn chế này (xem phần "xử lý các điểm cực trị" bên dưới).
Mặc dù các triển khai khác nhau có tính năng nâng cấp thông qua RealESRGAN (và có thể sửa các khuôn mặt được hiển thị kém thông qua GFPGAN) một số người dùng hiện đang phát triển các phương pháp để chia hình ảnh thành các phần 512x512px và ghép các hình ảnh lại với nhau để tạo thành các tác phẩm tổng hợp lớn hơn.

Kết xuất 1024×576 này, độ phân giải thường không thể có trong một kết xuất Khuếch tán ổn định duy nhất, được tạo bằng cách sao chép và dán tệp chú ý.py Python từ DoggettX nhánh của Khuếch tán ổn định (phiên bản triển khai tính năng nâng cấp dựa trên ô xếp) vào một nhánh khác. Nguồn: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Mặc dù một số sáng kiến thuộc loại này đang sử dụng mã gốc hoặc các thư viện khác, cổng txt2imghd của GOBIG (một chế độ trong ProgRockDiffusion ngốn VRAM) được thiết lập để sớm cung cấp chức năng này cho nhánh chính. Mặc dù txt2imghd là một cổng dành riêng cho GOBIG, những nỗ lực khác từ các nhà phát triển cộng đồng liên quan đến việc triển khai GOBIG khác nhau.

Một hình ảnh trừu tượng tiện lợi trong bản kết xuất gốc 512x512px (bên trái và thứ hai từ trái sang); được nâng cấp bằng ESGRAN, hiện nay ít nhiều là bản địa trên tất cả các bản phân phối Stable Diffusion; và được 'chú ý đặc biệt' thông qua việc triển khai GOBIG, tạo ra các chi tiết, ít nhất là trong phạm vi của phần hình ảnh, có vẻ được nâng cấp tốt hơn. Snguồn: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Loại ví dụ trừu tượng nêu trên có nhiều 'vương quốc nhỏ' chi tiết phù hợp với cách tiếp cận duy ngã này để nâng cấp, nhưng có thể yêu cầu các giải pháp do mã điều khiển đầy thách thức hơn để tạo ra khả năng nâng cấp gắn kết, không lặp lại mà không xem như thể nó được ghép lại từ nhiều bộ phận. Đặc biệt là trong trường hợp khuôn mặt con người, nơi chúng ta thường nhạy cảm với những sai lệch hoặc hiện tượng "gây nhiễu". Do đó, khuôn mặt cuối cùng có thể cần một giải pháp chuyên biệt.
Hiện tại, Stable Diffusion không có cơ chế tập trung sự chú ý vào khuôn mặt trong quá trình render theo cách con người ưu tiên thông tin khuôn mặt. Mặc dù một số nhà phát triển trong cộng đồng Discord đang xem xét các phương pháp để triển khai loại "sự chú ý nâng cao" này, nhưng hiện tại, việc nâng cao khuôn mặt theo cách thủ công (và cuối cùng là tự động) sau khi render ban đầu dễ dàng hơn nhiều.
Khuôn mặt người có logic ngữ nghĩa nội tại và hoàn chỉnh mà không thể tìm thấy trong một 'ô' ở góc dưới của (ví dụ) một tòa nhà, do đó hiện tại có thể 'phóng to' và kết xuất lại một khuôn mặt 'phác thảo' rất hiệu quả trong đầu ra Stable Diffusion.

Bên trái, nỗ lực ban đầu của Stable Diffusion với gợi ý "Ảnh màu toàn thân của Christina Hendricks bước vào một nơi đông người, mặc áo mưa; Canon50, giao tiếp bằng mắt, độ chi tiết cao, chi tiết khuôn mặt cao". Bên phải, khuôn mặt được cải thiện thu được bằng cách đưa khuôn mặt mờ và phác thảo từ bản render đầu tiên trở lại với sự chú ý hoàn toàn của Stable Diffusion bằng Img2Img (xem hình ảnh động bên dưới).
Trong trường hợp không có giải pháp Đảo ngược văn bản chuyên dụng (xem bên dưới), giải pháp này sẽ chỉ hoạt động đối với hình ảnh người nổi tiếng trong đó người được đề cập đã được thể hiện rõ ràng trong tập hợp con dữ liệu LAION đã đào tạo Khuếch tán ổn định. Do đó, nó sẽ hoạt động trên những người như Tom Cruise, Brad Pitt, Jennifer Lawrence và một số giới hạn những người nổi tiếng trên phương tiện truyền thông chân chính có mặt với số lượng lớn hình ảnh trong dữ liệu nguồn.
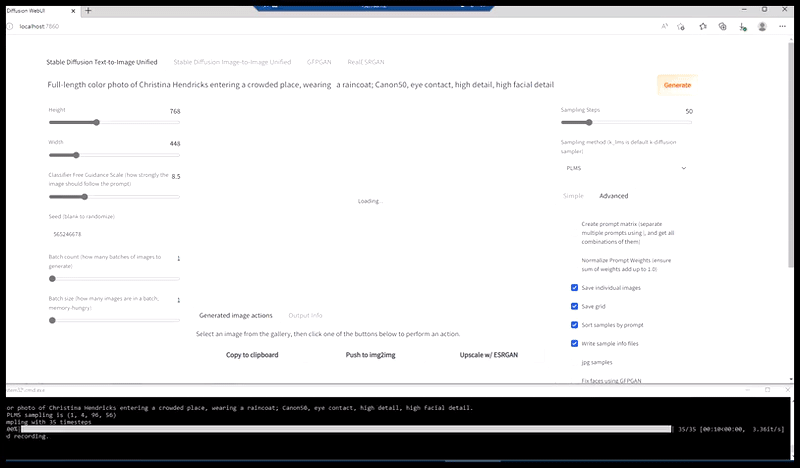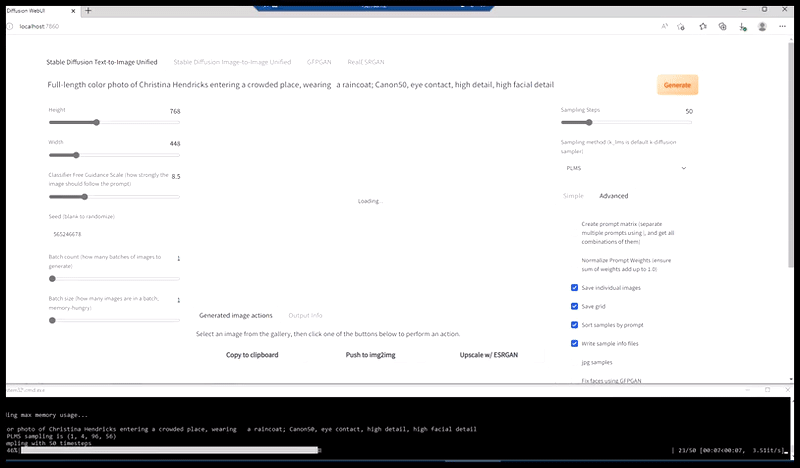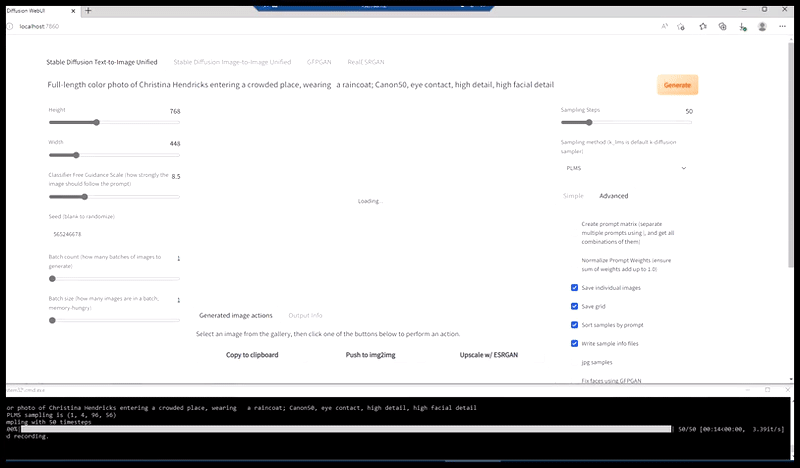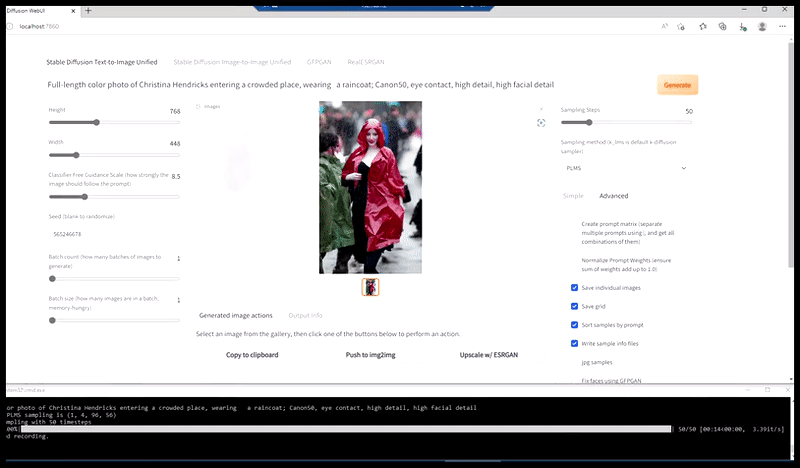
Tạo ra một bức ảnh báo chí hợp lý với gợi ý 'Ảnh màu toàn thân của Christina Hendricks bước vào nơi đông người, mặc áo mưa; Canon50, giao tiếp bằng mắt, độ chi tiết cao, độ chi tiết khuôn mặt cao'.
Đối với những người nổi tiếng có sự nghiệp lâu dài và lâu dài, Sự phổ biến ổn định thường sẽ tạo ra hình ảnh của người đó ở độ tuổi gần đây (tức là già hơn) và sẽ cần phải thêm các điều chỉnh nhanh như 'trẻ' or 'vào năm [NĂM]' để tạo ra những hình ảnh trẻ trung hơn.

Với sự nghiệp nổi bật, được chụp ảnh nhiều và nhất quán kéo dài gần 40 năm, nữ diễn viên Jennifer Connelly là một trong số ít những người nổi tiếng ở LAION cho phép Stable Diffusion đại diện cho nhiều lứa tuổi. Nguồn: prepack Stable Diffusion, local, v1.4 checkpoint; lời nhắc liên quan đến tuổi tác.
Điều này phần lớn là do sự phổ biến của nhiếp ảnh báo chí kỹ thuật số (chứ không phải đắt tiền, dựa trên nhũ tương) từ giữa những năm 2000 trở đi và sự tăng trưởng sau đó về khối lượng hình ảnh đầu ra do tốc độ băng thông rộng tăng lên.
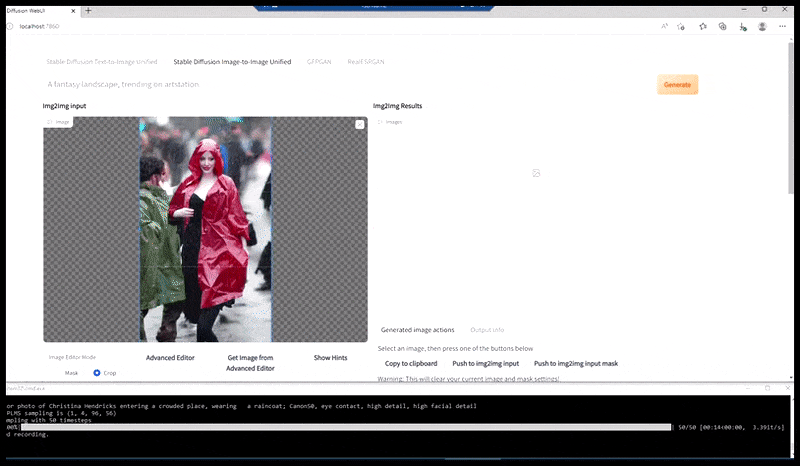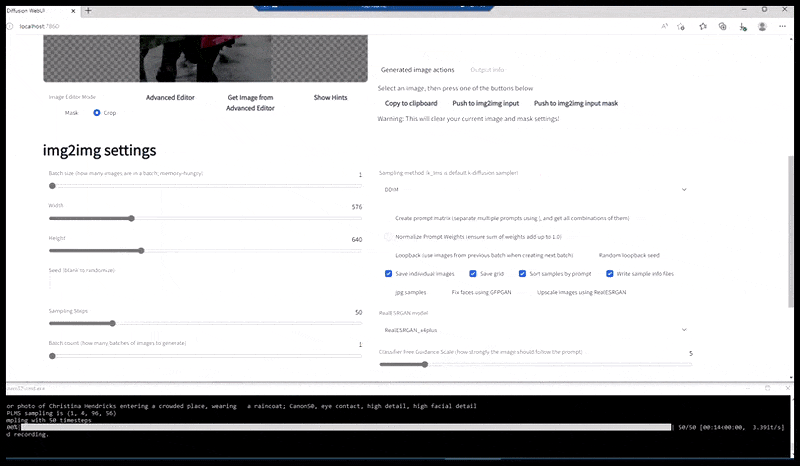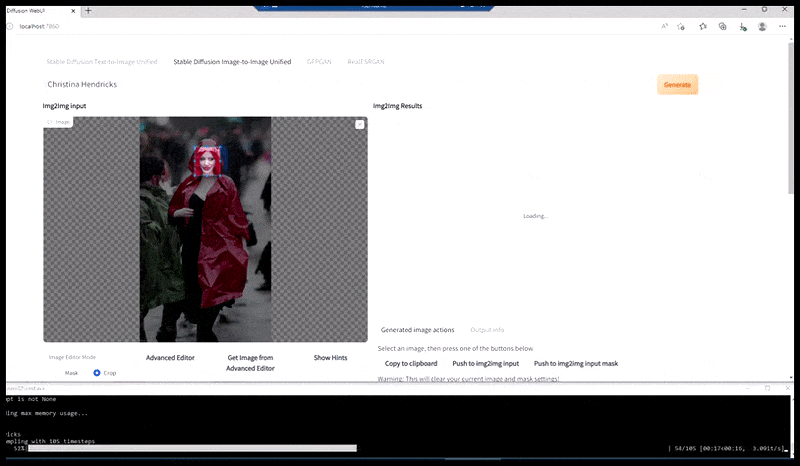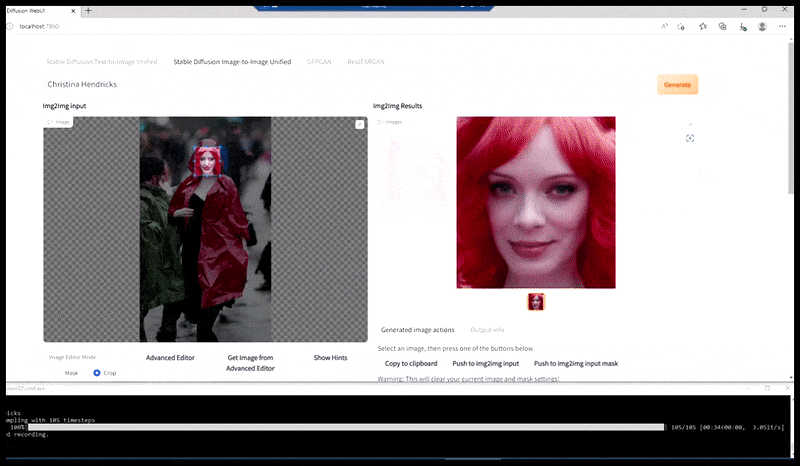
Hình ảnh được kết xuất sẽ được chuyển đến Img2Img trong Stable Diffusion, tại đó, một 'khu vực lấy nét' được chọn và một bản kết xuất mới có kích thước tối đa sẽ được tạo riêng cho khu vực đó, cho phép Stable Diffusion tập trung mọi nguồn lực có sẵn vào việc tái tạo khuôn mặt.
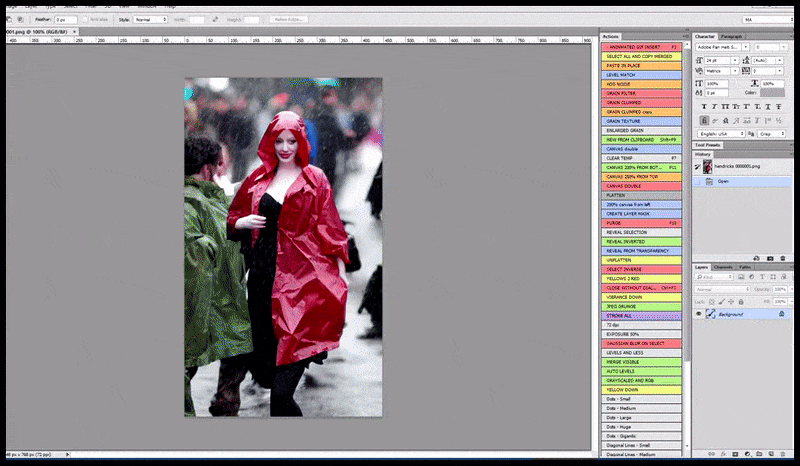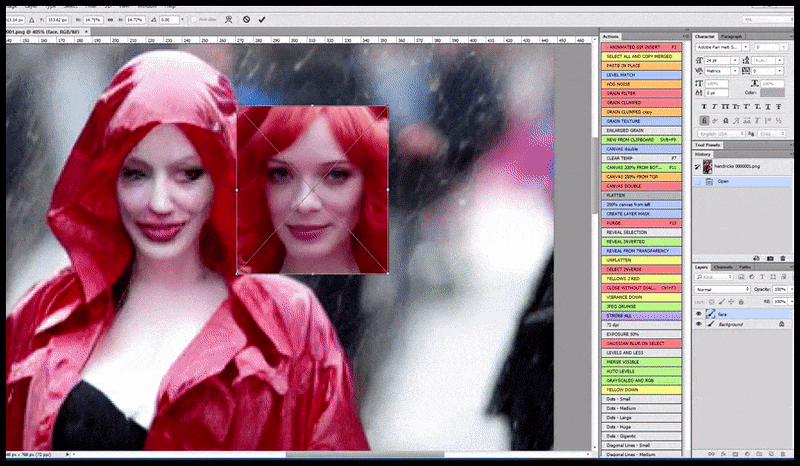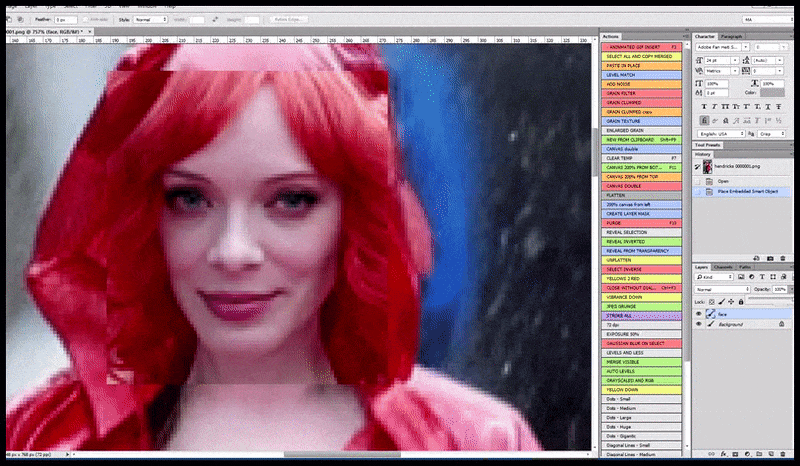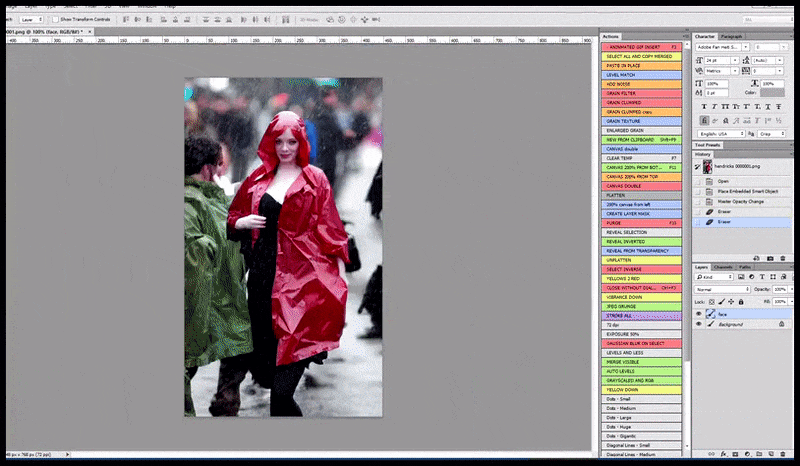
Ghép lại khuôn mặt "có độ chú ý cao" vào bản render gốc. Bên cạnh khuôn mặt, quy trình này chỉ hiệu quả với các thực thể có vẻ ngoài tiềm năng, gắn kết và toàn vẹn, chẳng hạn như một phần ảnh gốc có một vật thể riêng biệt, chẳng hạn như đồng hồ hoặc ô tô. Việc nâng cấp một phần của bức tường – ví dụ – sẽ dẫn đến một bức tường được ghép lại trông rất kỳ lạ, bởi vì các bản render dạng gạch không có bối cảnh rộng hơn cho "mảnh ghép" này khi chúng được render.
Một số người nổi tiếng trong cơ sở dữ liệu được "đóng băng" theo thời gian, hoặc vì họ qua đời sớm (chẳng hạn như Marilyn Monroe), hoặc chỉ nổi lên thoáng qua trong giới chính thống, tạo ra một lượng lớn hình ảnh trong một khoảng thời gian hạn chế. Polling Stable Diffusion được cho là cung cấp một loại chỉ số phổ biến "hiện tại" cho các ngôi sao hiện đại và lớn tuổi. Đối với một số người nổi tiếng hiện tại và lớn tuổi, không có đủ hình ảnh trong dữ liệu nguồn để có được sự giống nhau thực sự, trong khi sự nổi tiếng lâu dài của một số ngôi sao đã qua đời từ lâu hoặc đã mờ nhạt đảm bảo rằng hệ thống có thể thu được sự giống nhau hợp lý của họ.

Kết xuất khuếch tán ổn định nhanh chóng tiết lộ những gương mặt nổi tiếng nào được thể hiện tốt trong dữ liệu đào tạo. Bất chấp sự nổi tiếng to lớn của cô ấy khi còn là một thiếu niên lớn tuổi hơn vào thời điểm viết bài, Millie Bobby Brown trẻ hơn và ít nổi tiếng hơn khi bộ dữ liệu nguồn LAION bị lấy từ trang web, khiến cho sự tương đồng chất lượng cao với Khuếch tán ổn định trở nên khó khăn vào lúc này.
Khi có sẵn dữ liệu, các giải pháp nâng cấp độ phân giải dựa trên ô vuông trong Khuếch tán ổn định có thể tiến xa hơn là tìm kiếm trên khuôn mặt: chúng có khả năng cho phép khuôn mặt chính xác và chi tiết hơn nữa bằng cách chia nhỏ các đặc điểm khuôn mặt và biến toàn bộ lực lượng của GPU cục bộ tài nguyên về các tính năng nổi bật riêng lẻ, trước khi lắp ráp lại – một quy trình hiện tại, một lần nữa, là thủ công.

Điều này không giới hạn ở các khuôn mặt, nhưng nó bị giới hạn ở các phần của đối tượng ít nhất được đặt ở vị trí có thể dự đoán được trong ngữ cảnh rộng hơn của đối tượng máy chủ và phù hợp với các nhúng cấp cao mà người ta có thể mong đợi tìm thấy một cách hợp lý trong một siêu tỷ lệ tập dữ liệu.
Giới hạn thực sự là lượng dữ liệu tham chiếu có sẵn trong tập dữ liệu, vì cuối cùng, các chi tiết được lặp lại nhiều lần sẽ trở nên hoàn toàn 'ảo giác' (tức là hư cấu) và kém chân thực hơn.
Những phóng to chi tiết ở mức độ cao như vậy phù hợp với trường hợp của Jennifer Connelly, bởi vì cô ấy được đại diện tốt ở nhiều độ tuổi khác nhau trong LAION-thẩm mỹ (tập con chính của LAION 5B mà Stable Diffusion sử dụng) và nói chung là trên toàn bộ LAION; trong nhiều trường hợp khác, độ chính xác sẽ bị ảnh hưởng do thiếu dữ liệu, đòi hỏi phải tinh chỉnh (đào tạo bổ sung, xem phần 'Tùy chỉnh' bên dưới) hoặc Đảo ngược văn bản (xem bên dưới).
Các ô xếp là một cách mạnh mẽ và tương đối rẻ để bật Khuếch tán ổn định nhằm tạo ra đầu ra có độ phân giải cao, nhưng tính năng nâng cấp ô xếp theo thuật toán của loại này, nếu nó thiếu một số loại cơ chế chú ý cấp cao hơn, rộng hơn, có thể không đạt được như mong đợi- cho các tiêu chuẩn trên một loạt các loại nội dung.
2: Giải Quyết Các Vấn Đề Về Chân Tay Con Người
Stable Diffusion không xứng đáng với tên gọi của nó khi mô tả sự phức tạp của các chi người. Bàn tay có thể nhân lên ngẫu nhiên, các ngón tay hợp lại, chân thứ ba xuất hiện tự phát, và các chi hiện có biến mất không dấu vết. Về phần mình, Stable Diffusion cũng gặp vấn đề tương tự như những người anh em cùng nhà, và chắc chắn là cả DALL-E 2.

Kết quả chưa chỉnh sửa từ DALL-E 2 và Stable Diffusion (1.4) vào cuối tháng 2022 năm XNUMX, cả hai đều cho thấy vấn đề về chi. Yêu cầu là 'Một người phụ nữ ôm một người đàn ông'
Những người hâm mộ Khuếch tán ổn định hy vọng rằng điểm kiểm tra 1.5 sắp tới (một phiên bản mô hình được đào tạo chuyên sâu hơn, với các thông số được cải thiện) sẽ giải quyết được sự nhầm lẫn chi có thể sẽ thất vọng. Mô hình mới, sẽ được phát hành trong khoảng hai tuần nữa, hiện đang được công chiếu tại cổng thông tin stable.ai thương mại xưởng vẽ trong mơ, sử dụng 1.5 theo mặc định và là nơi người dùng có thể so sánh đầu ra mới với kết xuất từ hệ thống 1.4 cục bộ hoặc hệ thống XNUMX khác của họ:

Nguồn: Gói sẵn 1.4 cục bộ và https://beta.dreamstudio.ai/

Nguồn: Gói sẵn 1.4 cục bộ và https://beta.dreamstudio.ai/

Nguồn: Gói sẵn 1.4 cục bộ và https://beta.dreamstudio.ai/
Như thường lệ, chất lượng dữ liệu cũng có thể là nguyên nhân góp phần chính.
Cơ sở dữ liệu mã nguồn mở cung cấp nhiên liệu cho các hệ thống tổng hợp hình ảnh như Khuếch tán ổn định và DALL-E 2 có thể cung cấp nhiều nhãn cho cả con người riêng lẻ và hành động giữa con người với nhau. Các nhãn này được đào tạo cộng sinh với các hình ảnh hoặc phân đoạn hình ảnh được liên kết của chúng.

Người dùng Stable Diffusion có thể khám phá các khái niệm được đào tạo trong mô hình bằng cách truy vấn tập dữ liệu LAION-aesthetics, một tập con của tập dữ liệu LAION 5B lớn hơn, cung cấp năng lượng cho hệ thống. Các hình ảnh được sắp xếp không theo nhãn chữ cái mà theo "điểm thẩm mỹ" của chúng. Nguồn: https://rom1504.github.io/clip-retrieval/
A thứ bậc tốt các nhãn và lớp riêng lẻ góp phần mô tả cánh tay người sẽ giống như cơ thể>cánh tay>bàn tay>ngón tay>[chữ số phụ + ngón tay cái]> [đoạn chữ số]>Móng tay.

Phân đoạn ngữ nghĩa chi tiết các bộ phận của bàn tay. Ngay cả sự phân tích chi tiết bất thường này cũng để lại mỗi "ngón tay" như một thực thể duy nhất, không tính đến ba đốt ngón tay và hai đốt ngón cái. Nguồn: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Trên thực tế, các hình ảnh nguồn dường như không được chú thích một cách nhất quán trên toàn bộ tập dữ liệu và các thuật toán ghi nhãn không được giám sát có thể sẽ dừng lại ở cao hơn mức độ – ví dụ – 'bàn tay', và để lại các điểm ảnh bên trong (về mặt kỹ thuật chứa thông tin 'ngón tay') như một khối điểm ảnh không có nhãn mà từ đó các đặc điểm sẽ được suy ra một cách tùy ý và có thể biểu hiện trong các bản kết xuất sau này như một thành phần gây khó chịu.

Nó nên như thế nào (phía trên bên phải, nếu không phải là cắt trên) và nó có xu hướng như thế nào (phía dưới bên phải), do tài nguyên hạn chế để gắn nhãn hoặc khai thác kiến trúc của các nhãn đó nếu chúng tồn tại trong tập dữ liệu.
Vì vậy, nếu một mô hình khuếch tán tiềm ẩn tiến xa đến mức có thể tạo ra một cánh tay, thì gần như chắc chắn nó sẽ ít nhất có thể tạo ra một bàn tay ở cuối cánh tay đó, bởi vì tay>tay là hệ thống phân cấp tối thiểu cần thiết, khá cao trong những gì kiến trúc sư biết về 'giải phẫu con người'.
Sau đó, 'ngón tay' có thể là nhóm nhỏ nhất, mặc dù có thêm 14 bộ phận ngón tay/ngón cái cần xem xét khi mô tả bàn tay con người.
Nếu lý thuyết này đúng, thì không có biện pháp khắc phục thực sự, do thiếu ngân sách cho chú thích thủ công trên toàn ngành và thiếu các thuật toán hiệu quả đầy đủ có thể tự động hóa việc ghi nhãn trong khi tạo ra tỷ lệ lỗi thấp. Trên thực tế, mô hình hiện có thể dựa vào tính nhất quán về mặt giải phẫu của con người để khắc phục những thiếu sót của bộ dữ liệu mà nó được đào tạo.
Một lý do có thể tại sao nó không thể dựa vào điều này, gần đây đề xuất tại Sự bất hòa về khuếch tán ổn định, là mô hình có thể bị nhầm lẫn về số lượng ngón tay chính xác mà một bàn tay con người (thực tế) nên có vì cơ sở dữ liệu có nguồn gốc từ LAION cung cấp năng lượng cho nó có các nhân vật hoạt hình có thể có ít ngón tay hơn (bản thân nó một phím tắt tiết kiệm lao động).

Hai trong số những thủ phạm tiềm ẩn gây ra hội chứng "thiếu ngón tay" trong Stable Diffusion và các mô hình tương tự. Dưới đây là ví dụ về bàn tay hoạt hình từ bộ dữ liệu LAION-aesthetics hỗ trợ Stable Diffusion. Nguồn: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Nếu điều này là đúng, thì giải pháp rõ ràng duy nhất là đào tạo lại mô hình, loại trừ nội dung dựa trên con người phi thực tế, đảm bảo rằng các trường hợp thiếu sót thực sự (tức là người bị cụt chi) được dán nhãn phù hợp là trường hợp ngoại lệ. Chỉ riêng từ điểm quản lý dữ liệu, đây sẽ là một thách thức khá lớn, đặc biệt đối với các nỗ lực của cộng đồng đang thiếu tài nguyên.
Cách tiếp cận thứ hai sẽ là áp dụng các bộ lọc loại trừ nội dung như vậy (tức là 'bàn tay có ba/năm ngón tay') khỏi việc hiển thị tại thời điểm kết xuất, theo cách tương tự như OpenAI đã làm, ở một mức độ nào đó, đã lọc GPT-3 và DALL-E2, để đầu ra của chúng có thể được điều chỉnh mà không cần đào tạo lại các mô hình nguồn.

Đối với Stable Diffusion, sự phân biệt về mặt ngữ nghĩa giữa các ngón tay và thậm chí là các chi có thể trở nên mờ nhạt một cách đáng sợ, gợi nhớ đến dòng phim kinh dị 'kinh dị cơ thể' những năm 1980 của những người như David Cronenberg. Nguồn: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Tuy nhiên, một lần nữa, điều này sẽ yêu cầu các nhãn có thể không tồn tại trên tất cả các hình ảnh bị ảnh hưởng, khiến chúng tôi gặp phải thách thức tương tự về hậu cần và ngân sách.
Có thể lập luận rằng vẫn còn hai con đường phía trước: cung cấp thêm dữ liệu để giải quyết vấn đề và áp dụng các hệ thống giải thích của bên thứ ba có thể can thiệp khi những lỗi vật lý thuộc loại được mô tả ở đây được trình bày cho người dùng cuối (ít nhất, giải pháp sau sẽ cung cấp cho OpenAI một phương pháp để hoàn lại tiền cho các bản kết xuất 'kinh dị về cơ thể', nếu công ty có động lực để làm như vậy).
3: Tùy biến
Một trong những khả năng thú vị nhất cho tương lai của Khuếch tán ổn định là triển vọng người dùng hoặc tổ chức phát triển hệ thống sửa đổi; các sửa đổi cho phép tích hợp nội dung bên ngoài phạm vi LAION đã được đào tạo trước vào hệ thống – lý tưởng nhất là không tốn chi phí đào tạo lại toàn bộ mô hình hoặc rủi ro phát sinh khi đào tạo một khối lượng lớn hình ảnh mới cho một mô hình hiện có, trưởng thành và có khả năng người mẫu.
Tương tự như vậy: nếu hai học sinh kém năng khiếu hơn được học cùng một lớp tiên tiến gồm ba mươi học sinh, các em sẽ hoặc hòa nhập và bắt kịp, hoặc trượt vì là học sinh cá biệt; trong cả hai trường hợp, điểm trung bình của lớp có lẽ sẽ không bị ảnh hưởng. Tuy nhiên, nếu có 15 học sinh kém năng khiếu hơn được học cùng, điểm số của cả lớp có thể sẽ bị ảnh hưởng.
Tương tự như vậy, mạng lưới các mối quan hệ hiệp lực và khá mỏng manh được xây dựng qua quá trình đào tạo mô hình tốn kém và bền vững có thể bị tổn hại, trong một số trường hợp bị phá hủy một cách hiệu quả, bởi quá nhiều dữ liệu mới, làm giảm chất lượng đầu ra của mô hình trên diện rộng.
Trường hợp thực hiện điều này chủ yếu là khi bạn quan tâm đến việc chiếm đoạt hoàn toàn sự hiểu biết khái niệm của mô hình về các mối quan hệ và sự vật, và sử dụng nó cho mục đích sản xuất độc quyền nội dung tương tự như tài liệu bổ sung mà bạn đã thêm vào.
Như vậy, đào tạo 500,000 Simpsons khung vào một điểm kiểm tra Khuếch tán Ổn định hiện có, cuối cùng, có khả năng giúp bạn cải thiện Simpsons giả lập hơn so với bản dựng ban đầu có thể cung cấp, giả sử rằng đủ các mối quan hệ ngữ nghĩa rộng tồn tại trong quá trình (nghĩa là Homer Simpson ăn hotdog, có thể yêu cầu tài liệu về xúc xích không có trong tài liệu bổ sung của bạn nhưng đã có trong trạm kiểm soát) và giả sử rằng bạn không muốn đột nhiên chuyển từ Simpsons nội dung để tạo phong cảnh tuyệt vời của Greg Rutkowski – vì mô hình được đào tạo sau của bạn đã bị phân tâm quá nhiều và sẽ không còn hiệu quả trong việc thực hiện những việc như vậy như trước nữa.
Một ví dụ đáng chú ý về điều này là waifu-khuếch tán, đã thành công 56,000 hình ảnh anime sau khi được đào tạo vào một điểm kiểm tra Stable Diffusion đã hoàn thiện và được huấn luyện. Tuy nhiên, đây là một viễn cảnh khó khăn đối với người dùng nghiệp dư, vì mô hình này yêu cầu tối thiểu 30GB VRAM, vượt xa mức có thể có ở phân khúc người dùng phổ thông trong các phiên bản series 40XX sắp ra mắt của NVIDIA.

Quá trình đào tạo nội dung tùy chỉnh thành Phổ biến ổn định thông qua khuếch tán waifu: mô hình mất hai tuần đào tạo sau để xuất ra mức độ minh họa này. Sáu hình ảnh bên trái cho thấy tiến độ của mô hình, khi quá trình đào tạo được tiến hành, trong việc tạo ra đầu ra nhất quán với chủ đề dựa trên dữ liệu đào tạo mới. Nguồn: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Rất nhiều nỗ lực có thể được dành cho những "phân nhánh" điểm kiểm tra Stable Diffusion như vậy, nhưng lại bị cản trở bởi các khoản nợ kỹ thuật. Các nhà phát triển tại Discord chính thức đã chỉ ra rằng các bản phát hành điểm kiểm tra sau này không nhất thiết sẽ tương thích ngược, ngay cả với logic prompt có thể đã hoạt động với phiên bản trước đó, vì mối quan tâm chính của họ là có được mô hình tốt nhất có thể, thay vì hỗ trợ các ứng dụng và quy trình cũ.
Do đó, một công ty hoặc cá nhân quyết định chuyển một điểm kiểm tra thành một sản phẩm thương mại thực sự không có đường quay lại; phiên bản mô hình của họ, tại thời điểm đó, là một 'phân nhánh cứng' và sẽ không thể tận dụng các lợi ích từ các bản phát hành sau này từ stability.ai – đây là một cam kết khá lớn.
Hy vọng hiện tại và lớn hơn cho việc tùy chỉnh Khuếch tán ổn định là Đảo ngược văn bản, nơi người dùng đào tạo trong một số ít CLIP-aligned hình ảnh.

Là sự hợp tác giữa Đại học Tel Aviv và NVIDIA, đảo ngược văn bản cho phép đào tạo các thực thể riêng biệt và mới lạ mà không phá hủy các khả năng của mô hình nguồn. Nguồn: https://textual-inversion.github.io/
Hạn chế rõ ràng chính của đảo ngược văn bản là số lượng hình ảnh được khuyến nghị rất thấp – ít nhất là năm. Điều này tạo ra một thực thể giới hạn một cách hiệu quả có thể hữu ích hơn cho các tác vụ chuyển kiểu hơn là chèn các đối tượng ảnh thực.
Tuy nhiên, các thử nghiệm hiện đang diễn ra trong các Discords Stable Diffusion khác nhau sử dụng số lượng hình ảnh đào tạo cao hơn nhiều và vẫn còn phải xem phương pháp này có thể chứng minh hiệu quả như thế nào. Một lần nữa, kỹ thuật này đòi hỏi rất nhiều VRAM, thời gian và sự kiên nhẫn.
Do những yếu tố hạn chế này, chúng ta có thể phải đợi một thời gian để xem một số thử nghiệm đảo ngược văn bản phức tạp hơn từ những người đam mê Stable Diffusion – và liệu cách tiếp cận này có thể 'đưa bạn vào bức tranh' theo cách đẹp hơn so với việc cắt và dán trên Photoshop hay không, đồng thời vẫn giữ được chức năng đáng kinh ngạc của các điểm kiểm tra chính thức.
Xuất bản lần đầu vào ngày 6 tháng 2022 năm XNUMX.











