Trí tuệ nhân tạo
Cuộc Cách Mạng MoE: Làm Thế Nào Routing Và Chuyên Hóa Nâng Cao Đang Biến Đổi LLMs
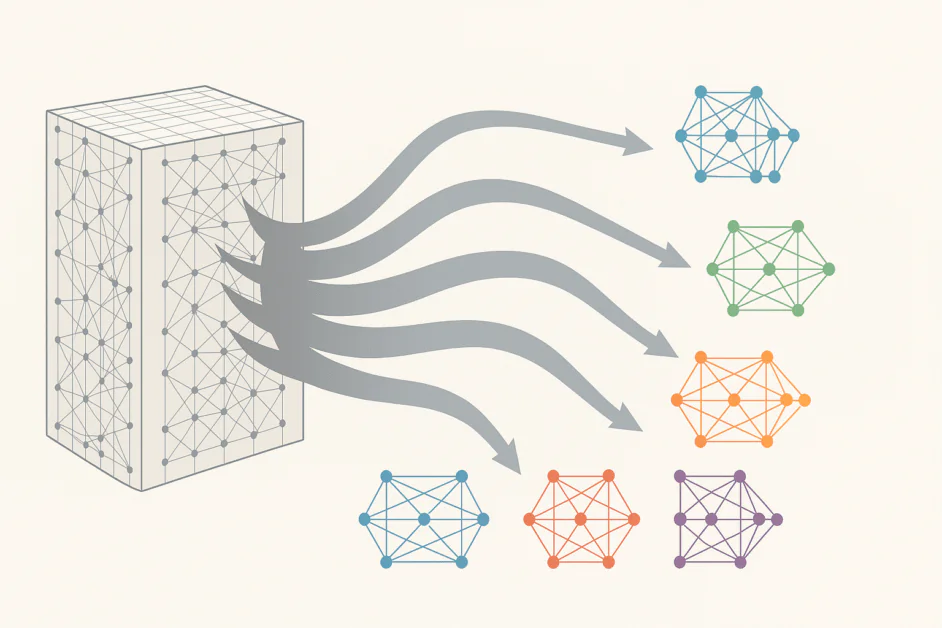
Chỉ trong vài năm, các mô hình ngôn ngữ lớn (LLMs) đã mở rộng từ hàng triệu đến hàng trăm tỷ tham số, thể hiện sự tiến bộ đáng kinh ngạc trong khả năng thiết kế và mở rộng các hệ thống AI khổng lồ. Những hệ thống khổng lồ này đã cung cấp các khả năng đáng kinh ngạc như viết văn bản trôi chảy, tạo mã, lý luận thông qua các vấn đề phức tạp và tham gia vào cuộc trò chuyện giống con người. Nhưng sự mở rộng nhanh chóng này đi kèm với một chi phí đáng kể. Việc đào tạo và chạy các mô hình khổng lồ như vậy tiêu thụ một lượng điện toán, năng lượng và vốn đáng kinh ngạc. Chiến lược “lớn hơn là tốt hơn” từng thúc đẩy sự tiến bộ đã bắt đầu hiển thị giới hạn của nó. Để đáp ứng những hạn chế ngày càng tăng này, một kiến trúc AI được gọi là Mixture of Experts (MoE) đang tiến bộ để cung cấp một con đường thông minh và hiệu quả hơn để mở rộng các mô hình ngôn ngữ lớn. Thay vì dựa vào một mạng lưới khổng lồ luôn hoạt động, MoE chia mô hình thành một tập hợp các mạng con chuyên dụng hoặc ‘chuyên gia’, mỗi mạng được đào tạo để xử lý các loại dữ liệu hoặc nhiệm vụ cụ thể. Thông qua việc định tuyến thông minh, mô hình chỉ kích hoạt các chuyên gia liên quan nhất cho mỗi đầu vào để giảm tải tính toán trong khi duy trì hoặc thậm chí cải thiện hiệu suất. Khả năng kết hợp khả năng mở rộng với hiệu quả làm cho MoE trở thành một trong những mô hình nổi bật nhất đang xuất hiện trong AI. Bài viết này khám phá cách định tuyến và chuyên hóa nâng cao đang thúc đẩy sự biến đổi này và ý nghĩa của nó đối với tương lai của các hệ thống thông minh.
Hiểu Về Kiến Trúc Cốt Lõi
Ý tưởng đằng sau Mixture of Experts (MoE) không mới. Nó bắt nguồn từ các phương pháp học tập tập thể của những năm 1990. Điều đã thay đổi là công nghệ làm cho nó hoạt động. Chỉ trong những năm gần đây, sự tiến bộ trong phần cứng và thuật toán định tuyến đã làm cho nó trở thành hiện thực trong các mô hình ngôn ngữ Transformer-based hiện đại.
Ở cốt lõi, MoE định nghĩa lại một mạng lưới thần kinh lớn như một tập hợp các mạng con chuyên dụng nhỏ hơn, mỗi mạng được đào tạo để xử lý một loại dữ liệu hoặc nhiệm vụ cụ thể. Thay vì kích hoạt mọi tham số cho mọi đầu vào, MoE giới thiệu một cơ chế định tuyến quyết định哪 chuyên gia nào là phù hợp nhất cho một token hoặc chuỗi cụ thể. Kết quả là một mô hình chỉ sử dụng một phần nhỏ của các tham số tại bất kỳ thời điểm nào, giảm đáng kể nhu cầu tính toán trong khi duy trì hoặc thậm chí cải thiện hiệu suất.
Trong thực tế, sự thay đổi kiến trúc này cho phép các nhà nghiên cứu mở rộng mô hình lên hàng nghìn tỷ tham số mà không cần tăng tương ứng về tài nguyên tính toán. Nó thay thế các lớp feedforward dày đặc bằng một hệ thống thông minh và động hơn. Mỗi lớp MoE chứa nhiều chuyên gia, thường là các mạng feedforward nhỏ hơn, và một bộ định tuyến hoặc mạng cổng quyết định哪 chuyên gia nên xử lý mỗi phần đầu vào. Bộ định tuyến hoạt động như một người quản lý dự án, gửi các câu hỏi liên quan đến từng chuyên gia. Theo thời gian, hệ thống học cách xác định哪 chuyên gia thực hiện tốt nhất cho các loại vấn đề khác nhau, tinh chỉnh chiến lược định tuyến của nó khi đào tạo.
Kiến trúc này cung cấp một sự kết hợp đáng kinh ngạc giữa quy mô và hiệu quả. Ví dụ, DeepSeek V3, một trong những mô hình MoE tiên tiến nhất, sử dụng 685 tỷ tham số nhưng chỉ kích hoạt một phần nhỏ trong quá trình suy luận. Nó cung cấp hiệu suất của một mô hình khổng lồ với nhu cầu tính toán và năng lượng đáng kể thấp hơn.
Sự Tiến Hóa Của Cơ Chế Định Tuyến
Bộ định tuyến là trái tim của MoE, quyết định哪 chuyên gia xử lý mỗi đầu vào. Các mô hình đầu tiên sử dụng các chiến lược đơn giản, chọn hai hoặc ba chuyên gia hàng đầu dựa trên trọng số đã học. Các hệ thống hiện đại phức tạp hơn nhiều.
Hôm nay, các cơ chế định tuyến động điều chỉnh số lượng chuyên gia được kích hoạt dựa trên độ phức tạp của đầu vào. Một câu hỏi đơn giản có thể chỉ cần một chuyên gia, trong khi các nhiệm vụ lý luận khó có thể kích hoạt nhiều chuyên gia. DeepSeek-V2 đã thực hiện định tuyến giới hạn thiết bị để kiểm soát chi phí giao tiếp trên phần cứng phân tán. DeepSeek-V3 đã tiên phong trong các chiến lược không mất mát phụ mà cho phép chuyên hóa giàu hơn mà không làm giảm hiệu suất.
Các bộ định tuyến tiên tiến hiện nay hoạt động như các nhà quản lý tài nguyên thông minh, điều chỉnh chiến lược chọn lọc dựa trên đặc điểm đầu vào, độ sâu mạng hoặc phản hồi hiệu suất thời gian thực. Một số nhà nghiên cứu đang khám phá việc sử dụng học tăng cường để tối ưu hóa hiệu suất nhiệm vụ dài hạn. Các kỹ thuật như cổng mềm cho phép chọn lọc chuyên gia mượt mà hơn, trong khi phân phối xác suất sử dụng các phương pháp thống kê để tối ưu hóa việc phân配.
Chuyên Hóa Đẩy Mạnh Hiệu Suất
Lời hứa cốt lõi của MoE là chuyên sâu vượt trội so với tổng quát hóa rộng. Mỗi chuyên gia tập trung vào việc thành thạo các lĩnh vực cụ thể thay vì trở nên tầm thường ở mọi thứ. Trong quá trình đào tạo, các cơ chế định tuyến liên tục chỉ đạo các loại đầu vào cụ thể đến các chuyên gia cụ thể, tạo ra một vòng phản hồi mạnh mẽ. Một số chuyên gia xuất sắc trong việc mã hóa, những chuyên gia khác trong thuật ngữ y tế, và những chuyên gia khác trong viết sáng tạo.
Tuy nhiên, việc đạt được mục tiêu này đặt ra những thách thức. Các phương pháp cân bằng tải truyền thống có thể vô tình cản trở chuyên hóa bằng cách buộc sử dụng chuyên gia đồng đều. Tuy nhiên, lĩnh vực này đang phát triển nhanh chóng. Các nghiên cứu cho thấy rằng các mô hình MoE tinh tế hiển thị chuyên hóa rõ ràng, với các chuyên gia khác nhau thống trị trong các lĩnh vực của họ. Các nghiên cứu xác nhận rằng các cơ chế định tuyến đóng vai trò tích cực trong việc định hình sự phân chia lao động kiến trúc này.
Các chiến lược sử dụng chuyên gia then chốt theo lĩnh vực đã chứng minh sự cải thiện hiệu suất đáng kể. Ví dụ, các nhà nghiên cứu đã báo cáo một lợi ích chính xác 3,33% trên điểm chuẩn AIME2024. Khi chuyên hóa hoạt động, kết quả thật đáng kinh ngạc. DeepSeek V3 vượt trội so với GPT-4o trên hầu hết các điểm chuẩn ngôn ngữ tự nhiên và dẫn đầu trong tất cả các nhiệm vụ lý luận toán học và mã hóa, một cột mốc ấn tượng cho một mô hình mã nguồn mở.
Tác Động Thực Tiễn Đối Với Khả Năng Mô Hình
Cuộc cách mạng MoE đã mang lại những cải thiện đáng kể về khả năng cốt lõi của mô hình. Các mô hình hiện có thể xử lý các ngữ cảnh dài hơn một cách hiệu quả hơn; cả DeepSeek V3 và GPT-4o đều có thể xử lý 128K token trong một đầu vào, với kiến trúc MoE tối ưu hóa hiệu suất, đặc biệt là trong các lĩnh vực kỹ thuật. Điều này rất quan trọng đối với các ứng dụng như phân tích toàn bộ cơ sở mã hoặc xử lý các tài liệu pháp lý dài.
Lợi ích về hiệu quả chi phí thậm chí còn ấn tượng hơn. Phân tích cho thấy DeepSeek-V3 rẻ hơn khoảng 29,8 lần so với GPT-4o trên mỗi token. Sự khác biệt về giá này làm cho AI tiên tiến trở nên dễ tiếp cận hơn với nhiều người dùng và ứng dụng. Nó đẩy nhanh quá trình dân chủ hóa AI.
Hơn nữa, kiến trúc này cho phép triển khai bền vững hơn. Việc đào tạo một mô hình MoE vẫn đòi hỏi tài nguyên đáng kể, nhưng chi phí suy luận thấp hơn đáng kể đã mở ra một mô hình hiệu quả và kinh tế hơn cho các công ty AI và khách hàng của họ.
Thách Thức Và Con Đường Tiếp Theo
Mặc dù có những lợi thế đáng kể, MoE không phải là không có thách thức. Việc đào tạo có thể không ổn định, với các chuyên gia đôi khi không chuyên hóa như dự định. Các mô hình đầu tiên gặp phải “sự sụp đổ định tuyến”, nơi một chuyên gia thống trị. Đảm bảo tất cả các chuyên gia nhận được đủ dữ liệu đào tạo trong khi chỉ một tập con đang hoạt động đòi hỏi sự cân bằng cẩn thận.
Điểm nghẽn lớn nhất là chi phí giao tiếp. Trong các thiết lập GPU phân tán, chi phí giao tiếp có thể tiêu thụ đến 77% thời gian xử lý. Nhiều chuyên gia “hợp tác quá mức”, thường xuyên kích hoạt cùng nhau và buộc phải chuyển dữ liệu lặp đi lặp lại qua các gia tốc phần cứng. Điều này đang thúc đẩy sự đánh giá lại cơ bản về thiết kế phần cứng AI.
Nhu cầu bộ nhớ cũng đặt ra một thách thức đáng kể. Mặc dù MoE giảm chi phí tính toán trong quá trình suy luận, nhưng tất cả các chuyên gia phải được tải vào bộ nhớ, gây áp lực lên các thiết bị biên hoặc môi trường tài nguyên hạn chế. Khả năng giải thích vẫn là một thách thức chính khác, vì việc xác định chuyên gia nào đóng góp cho một đầu ra cụ thể thêm một lớp phức tạp khác vào kiến trúc. Các nhà nghiên cứu hiện đang khám phá các phương pháp để theo dõi hoạt động của chuyên gia và trực quan hóa các đường dẫn quyết định, nhằm làm cho các hệ thống MoE trở nên minh bạch và dễ kiểm tra hơn.
Kết Luận
Mô hình Mixture of Experts không chỉ là một kiến trúc mới; mà nó là một triết lý mới để xây dựng các mô hình AI. Bằng cách kết hợp định tuyến thông minh với chuyên hóa cấp độ lĩnh vực, MoE đạt được điều gì từng似乎 mâu thuẫn: quy mô lớn hơn với ít tính toán hơn. Mặc dù các thách thức về ổn định, giao tiếp và khả năng giải thích vẫn tồn tại, sự cân bằng của nó về hiệu quả, khả năng thích ứng và độ chính xác chỉ ra tương lai của các hệ thống AI không chỉ lớn hơn mà còn thông minh hơn.












