
Trí tuệ nhân tạo
Các kỹ sư phát triển phương pháp “Early Bird” tiết kiệm năng lượng để đào tạo mạng lưới thần kinh sâu
Các kỹ sư tại Đại học Rice đã phát triển một phương pháp mới để đào tạo mạng lưới thần kinh sâu (DNN) với một phần năng lượng thường được yêu cầu. DNN là một dạng trí tuệ nhân tạo (AI) đóng vai trò chính trong việc phát triển các công nghệ như xe tự lái, trợ lý thông minh, nhận dạng khuôn mặt và các ứng dụng khác.
Early Bird đã được trình bày chi tiết trong một tờ giấy vào ngày 29 tháng XNUMX bởi các nhà nghiên cứu từ Đại học Rice và Texas A&M. Nó đã diễn ra tại Hội nghị quốc tế về đại diện học tập, hoặc ICLR 2020.
Các tác giả chính của nghiên cứu là Haoran You và Chaojian Li từ Phòng thí nghiệm Điện toán Thông minh và Hiệu quả (EIC) của Rice. Trong một nghiên cứu, họ đã chứng minh phương pháp này có thể huấn luyện DNN ở cùng cấp độ và độ chính xác như các phương pháp ngày nay, nhưng sử dụng năng lượng ít hơn 10.7 lần.
Nghiên cứu được dẫn dắt bởi giám đốc Phòng thí nghiệm EIC Yingyan Lin, Richard Baraniuk của Rice và Zhangyang Wang của Texas A&M. Các đồng tác giả khác bao gồm Pengfei Xu, Yonggan Fu, Yue Wang và Xiaohan Chen.
“Một động lực chính thúc đẩy những đột phá AI gần đây là việc giới thiệu các DNN lớn hơn, đắt tiền hơn”, Lin cho biết. “Nhưng việc đào tạo các DNN này đòi hỏi rất nhiều năng lượng. Để có thêm nhiều cải tiến được công bố, điều bắt buộc là phải tìm ra các phương pháp đào tạo 'xanh hơn' vừa giải quyết được các mối quan tâm về môi trường vừa giảm rào cản tài chính của nghiên cứu AI”.
Đắt tiền để đào tạo DNN
Có thể rất tốn kém để đào tạo các DNN tốt nhất thế giới và giá tiếp tục tăng. Vào năm 2019, một nghiên cứu do Viện AI Allen ở Seattle dẫn đầu đã phát hiện ra rằng để đào tạo một mạng nơ-ron sâu hàng đầu, cần phải tính toán nhiều hơn 300,000 lần so với giai đoạn 2012-2018. Một nghiên cứu khác vào năm 2019, lần này do các nhà nghiên cứu tại Đại học Massachusetts Amherst dẫn đầu, đã phát hiện ra rằng bằng cách đào tạo một DNN ưu tú, duy nhất, lượng khí thải carbon dioxide tương đương với năm chiếc ô tô của Hoa Kỳ được thải ra.
Để DNN thực hiện các nhiệm vụ chuyên môn hóa cao, chúng bao gồm ít nhất hàng triệu tế bào thần kinh nhân tạo. Chúng có khả năng học cách đưa ra quyết định, đôi khi vượt trội hơn con người, bằng cách quan sát một số lượng lớn các ví dụ. Họ có thể làm điều này mà không cần lập trình rõ ràng.
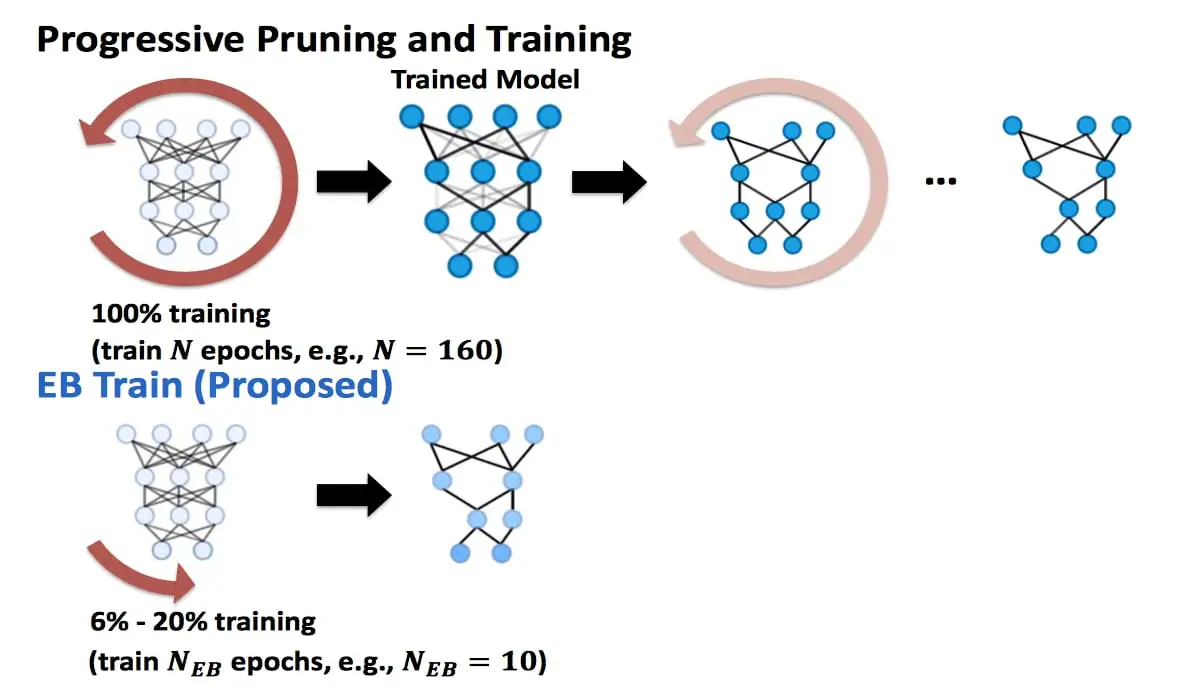
cắt tỉa và đào tạo
Lin là trợ lý giáo sư về kỹ thuật điện và máy tính tại Trường Kỹ thuật Rice's Brown.
“Phương pháp tiên tiến nhất để thực hiện huấn luyện DNN được gọi là cắt tỉa và huấn luyện lũy tiến,” Lin nói. “Đầu tiên, bạn huấn luyện một mạng lưới khổng lồ, dày đặc, sau đó loại bỏ những phần trông không quan trọng — giống như việc cắt tỉa một cái cây. Sau đó, bạn huấn luyện lại mạng lưới đã cắt tỉa để khôi phục hiệu suất vì hiệu suất sẽ giảm sau khi cắt tỉa. Và trên thực tế, bạn cần cắt tỉa và huấn luyện lại nhiều lần để đạt được hiệu suất tốt.”
Phương pháp này được sử dụng vì không phải tất cả các tế bào thần kinh nhân tạo đều cần thiết để hoàn thành nhiệm vụ chuyên biệt. Các kết nối giữa các tế bào thần kinh được củng cố nhờ quá trình đào tạo và những kết nối khác có thể bị loại bỏ. Phương pháp cắt tỉa này cắt giảm chi phí tính toán và giảm kích thước mô hình, giúp cho các DNN được đào tạo đầy đủ trở nên hợp lý hơn.
“Bước đầu tiên, đào tạo mạng lưới khổng lồ, dày đặc, là bước tốn kém nhất”, Lin cho biết. “Ý tưởng của chúng tôi trong công trình này là xác định mạng lưới cuối cùng, được cắt tỉa hoàn toàn, có chức năng, mà chúng tôi gọi là 'vé sớm', trong giai đoạn đầu của bước đầu tiên tốn kém này”.
Các nhà nghiên cứu làm điều này bằng cách tìm kiếm các mẫu kết nối mạng chính và họ có thể phát hiện ra những tấm vé sớm này. Điều này cho phép họ đẩy nhanh quá trình đào tạo DNN.
Early Bird trong giai đoạn bắt đầu đào tạo
Lin và các nhà nghiên cứu khác phát hiện ra rằng Early Bird có thể chỉ đạt được một phần mười hoặc ít hơn trong suốt giai đoạn đầu của quá trình đào tạo.
Lin cho biết: “Phương pháp của chúng tôi có thể tự động xác định các yêu cầu đăng ký sớm trong 10% đầu tiên hoặc ít hơn trong quá trình đào tạo của các mạng khổng lồ, dày đặc. “Điều này có nghĩa là bạn có thể đào tạo một DNN để đạt được độ chính xác tương tự hoặc thậm chí tốt hơn cho một nhiệm vụ nhất định trong khoảng 10% hoặc ít hơn thời gian cần thiết cho đào tạo truyền thống, điều này có thể giúp tiết kiệm nhiều hơn một đơn hàng cả về tính toán và năng lượng.”
Bên cạnh việc nhanh hơn và tiết kiệm năng lượng hơn, các nhà nghiên cứu còn tập trung mạnh vào tác động môi trường.
“Mục tiêu của chúng tôi là làm cho AI trở nên thân thiện với môi trường hơn và toàn diện hơn,” cô nói. “Kích thước tuyệt đối của các vấn đề AI phức tạp đã khiến những người chơi nhỏ hơn không thể tham gia. Trí tuệ nhân tạo xanh có thể mở ra cánh cửa cho phép các nhà nghiên cứu có máy tính xách tay hoặc tài nguyên máy tính hạn chế khám phá các đổi mới trí tuệ nhân tạo.”
Nghiên cứu đã nhận được sự hỗ trợ từ Quỹ khoa học quốc gia.











