Trí tuệ nhân tạo
Andrew Ng Chỉ Trích Văn Hóa Overfitting Trong Học Máy
Andrew Ng, một trong những tiếng nói có ảnh hưởng nhất trong lĩnh vực học máy trong thập kỷ qua, hiện đang lên tiếng về mức độ mà lĩnh vực này nhấn mạnh vào các đổi mới trong kiến trúc mô hình hơn là dữ liệu – và cụ thể, mức độ mà nó cho phép các kết quả “overfitted” được mô tả như các giải pháp tổng quát hoặc tiến bộ.
Những lời chỉ trích này là sự chỉ trích rộng rãi về văn hóa học máy hiện tại, xuất phát từ một trong những thẩm quyền cao nhất, và có ý nghĩa đối với sự tự tin trong một lĩnh vực bị ảnh hưởng bởi nỗi sợ hãi về sự sụp đổ thứ ba của niềm tin kinh doanh trong phát triển AI trong không gian sáu mươi năm.
Ng, một giáo sư tại Đại học Stanford, cũng là một trong những người sáng lập của deeplearning.ai, và vào tháng 3 đã xuất bản một thư trên trang web của tổ chức đó, đã cô đọng một điado gần đây của ông xuống còn một vài khuyến nghị cốt lõi:
Trước hết, rằng cộng đồng nghiên cứu nên ngừng phàn nàn rằng việc làm sạch dữ liệu đại diện cho 80% thách thức trong học máy, và bắt đầu công việc phát triển các phương pháp và thực hành MLOps mạnh mẽ.
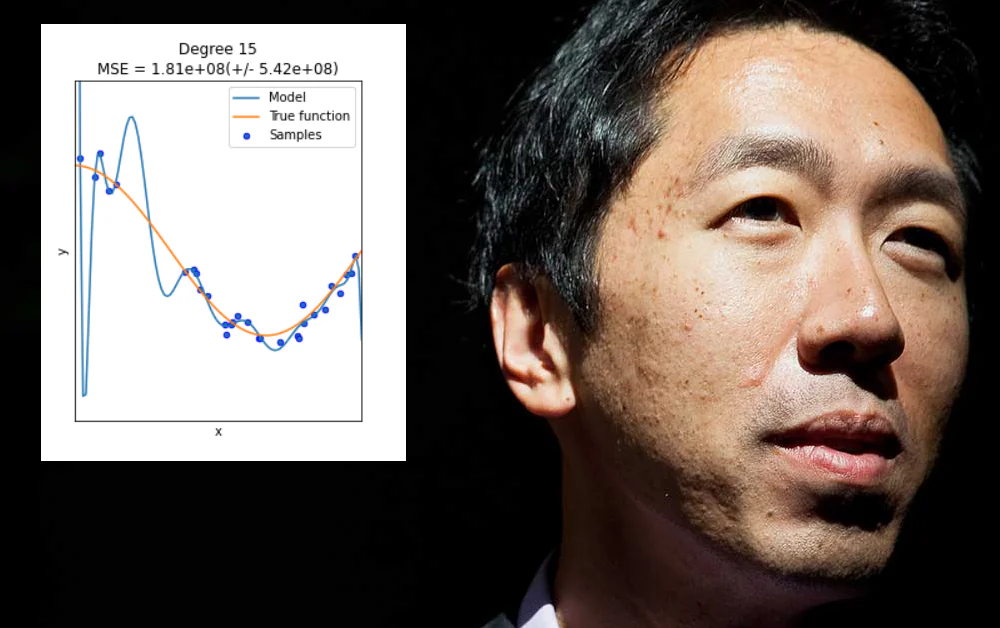
Thứ hai, rằng nó nên chuyển khỏi những “chiến thắng dễ dàng” có thể đạt được bằng cách over-fitting dữ liệu vào một mô hình học máy, để nó hoạt động tốt trên mô hình đó nhưng không tổng quát hóa hoặc sản xuất một mô hình có thể triển khai rộng rãi.
Chấp Nhận Thử Thách Của Kiến Trúc Dữ Liệu Và Curation
“Quan điểm của tôi”, Ng viết, “là nếu 80 phần trăm công việc của chúng tôi là chuẩn bị dữ liệu, thì đảm bảo chất lượng dữ liệu là công việc quan trọng của một đội học máy.”
Ông tiếp tục:
‘Thay vì dựa vào các kỹ sư may mắn tìm ra cách cải thiện một tập dữ liệu, tôi hy vọng chúng ta có thể phát triển các công cụ MLOps giúp xây dựng các hệ thống AI, bao gồm cả xây dựng các tập dữ liệu chất lượng cao, trở nên lặp lại và hệ thống hơn.
‘MLOps là một lĩnh vực mới, và khác người định nghĩa nó khác nhau. Nhưng tôi nghĩ rằng nguyên tắc tổ chức quan trọng nhất của các đội và công cụ MLOps nên là đảm bảo dòng chảy nhất quán và chất lượng cao của dữ liệu trong tất cả các giai đoạn của một dự án. Điều này sẽ giúp nhiều dự án trở nên mượt mà hơn.’
Khi nói trên Zoom tại một phiên Q&A trực tiếp vào cuối tháng 4, Ng đã giải quyết sự thiếu hụt về tính áp dụng trong các hệ thống phân tích học máy cho lĩnh vực X-quang:
“Thật ra, khi chúng tôi thu thập dữ liệu từ Bệnh viện Stanford, sau đó chúng tôi đào tạo và kiểm tra trên dữ liệu từ cùng một bệnh viện, thực sự, chúng tôi có thể xuất bản các bài báo cho thấy [các thuật toán] tương đương với các bác sĩ X-quang con người trong việc phát hiện các tình trạng nhất định.
“…[Khi] bạn lấy cùng mô hình đó, cùng hệ thống AI đó, đến một bệnh viện cũ hơn trên đường, với một máy cũ hơn, và kỹ thuật viên sử dụng một giao thức hình ảnh slightly khác, dữ liệu trôi dạt để gây ra hiệu suất của hệ thống AI suy giảm đáng kể. Ngược lại, bất kỳ bác sĩ X-quang nào cũng có thể đi xuống đường đến bệnh viện cũ và làm tốt.”
Under-specification Không Phải Là Giải Pháp
Overfitting xảy ra khi một mô hình học máy được thiết kế đặc biệt để phù hợp với các đặc điểm của một tập dữ liệu cụ thể (hoặc cách dữ liệu được định dạng). Điều này có thể liên quan, ví dụ, đến việc chỉ định các trọng số sẽ tạo ra kết quả tốt từ tập dữ liệu đó, nhưng sẽ không “tổng quát hóa” trên các dữ liệu khác.
Trong nhiều trường hợp, các tham số như vậy được định nghĩa trên các khía cạnh “phi dữ liệu” của tập dữ liệu đào tạo, chẳng hạn như độ phân giải cụ thể của thông tin thu thập được, hoặc các đặc điểm khác không được đảm bảo sẽ tái diễn trên các tập dữ liệu tiếp theo.
Mặc dù sẽ rất tốt, overfitting không phải là một vấn đề có thể được giải quyết bằng cách mù quáng mở rộng phạm vi hoặc tính linh hoạt của kiến trúc dữ liệu hoặc thiết kế mô hình, khi thực tế cần các tính năng có thể áp dụng rộng rãi và có ý nghĩa cao sẽ hoạt động tốt trên nhiều môi trường dữ liệu – một thách thức khó khăn hơn.
Nói chung, loại “under-specification” này chỉ dẫn đến các vấn đề mà Ng đã gần đây phác thảo, nơi một mô hình học máy thất bại trên dữ liệu không nhìn thấy. Sự khác biệt trong trường hợp này là mô hình thất bại không phải vì dữ liệu hoặc định dạng dữ liệu khác với tập dữ liệu đào tạo ban đầu được overfitted, mà vì mô hình quá linh hoạt chứ không quá giòn.
Vào cuối năm 2020, bài báo Underspecification Presents Challenges for Credibility in Modern Machine Learning đã chỉ trích gay gắt thực tiễn này, và mang tên của không ít hơn bốn mươi nhà nghiên cứu và nhà khoa học học máy từ Google và MIT, trong số các tổ chức khác.
Bài báo chỉ trích ‘shortcut learning’, và quan sát cách các mô hình underspecified có thể đi chệch theo các hướng ngẫu nhiên dựa trên điểm bắt đầu ngẫu nhiên mà quá trình đào tạo mô hình bắt đầu. Các tác giả nhận xét:
‘Chúng tôi đã thấy rằng underspecification là phổ biến trong các đường ống học máy thực tế trên nhiều lĩnh vực. Thực tế, nhờ underspecification, các khía cạnh quan trọng của quyết định được xác định bởi các lựa chọn tùy ý như hạt giống ngẫu nhiên được sử dụng cho việc khởi tạo tham số.’
Hậu Quả Kinh Tế Của Việc Thay Đổi Văn Hóa
Mặc dù có bằng cấp học thuật, Ng không phải là một học giả mơ hồ, mà có kinh nghiệm ngành sâu và cấp cao với tư cách là đồng sáng lập của Google Brain và Coursera, là cựu trưởng nhóm khoa học dữ liệu lớn và AI tại Baidu, và là sáng lập của Landing AI, điều hành 175 triệu USD cho các startup mới trong lĩnh vực này.
Khi ông nói “Toàn bộ AI, không chỉ y tế, có một khoảng cách giữa chứng minh khái niệm và sản xuất”, điều này được coi là một lời cảnh báo cho một lĩnh vực mà mức độ cường điệu và lịch sử lốm đốm đã ngày càng đặc trưng cho nó như một khoản đầu tư kinh doanh không chắc chắn, đối mặt với các vấn đề về định nghĩa và phạm vi.
Tuy nhiên, các hệ thống học máy độc quyền hoạt động tốt trong môi trường và thất bại trong các môi trường khác đại diện cho loại chiếm lĩnh thị trường có thể mang lại lợi nhuận cho đầu tư ngành. Việc trình bày ‘vấn đề overfitting’ trong bối cảnh một nguy cơ nghề nghiệp cung cấp một cách không trung thực để tài trợ cho đầu tư doanh nghiệp trong nghiên cứu mã nguồn mở, và để sản xuất (hiệu quả) các hệ thống độc quyền mà việc sao chép bởi các đối thủ cạnh tranh là có thể, nhưng có vấn đề.
Liệu cách tiếp cận này có hoạt động trong dài hạn hay không phụ thuộc vào mức độ mà các đột phá thực sự trong học máy tiếp tục đòi hỏi các mức đầu tư ngày càng lớn, và liệu tất cả các sáng kiến sản xuất có phải sẽ di chuyển đến FAANG ở một mức độ nào đó, do các nguồn lực khổng lồ cần thiết cho việc lưu trữ và hoạt động.












