Yapay Zeka
İstikrarlı Yayılım İçin Önümüzdeki Üç Zorluk

MKS serbest stability.ai'nin Kararlı Yayılımı gizli difüzyon Birkaç hafta önceki görüntü sentezi modeli, en önemli teknolojik açıklamalardan biri olabilir. 1999'da DeCSS'den beri; bu kesinlikle 2017'den bu yana yapay zeka tarafından üretilen görüntülerdeki en büyük olay derin sahte kod GitHub'a kopyalandı ve ne olacağı için çatallandı Derin Yüz Laboratuvarı ve Yüz nakli, gerçek zamanlı akışlı deepfake yazılımının yanı sıra DerinYüzCanlı.
Bir vuruşta, kullanıcı hayal kırıklığı üzerinde içerik kısıtlamaları DALL-E 2'nin görüntü sentezleme API'si bir kenara itildi, çünkü Stable Diffusion'ın NSFW filtresinin bir filtreyi değiştirerek devre dışı bırakılabileceği ortaya çıktı tek kod satırı. Porno merkezli Stable Diffusion Reddit'ler neredeyse anında ortaya çıktı ve bir o kadar da hızla kesildi, geliştirici ve kullanıcı kampı Discord'u resmi ve NSFW toplulukları olarak ikiye ayırdı ve Twitter fantastik Stable Diffusion kreasyonlarıyla dolmaya başladı.
Şu anda, her gün, sistemi benimseyen geliştiricilerden bazı şaşırtıcı yenilikler getiriyor gibi görünüyor, eklentiler ve üçüncü taraf ekleri alelacele yazılıyor. Krita, Photoshop, Cinema4D, karıştırıcıve diğer birçok uygulama platformu.
Bu arada, hızlı zanaat – artık profesyonel hale gelen ve 'Filofax klasörü'nden bu yana en kısa kariyer seçeneği olabilecek 'Yapay Zeka fısıldama' sanatı – şimdiden yaygınlaşıyor ticarileşmeden rahatsız oldu., Stable Difusion'ın erken para kazanma özelliği şu aşamada gerçekleşirken: Patreon seviyesi, gezinmek istemeyenler için daha sofistike tekliflerin geleceğinden emin olarak Conda tabanlı kaynak kodunun yüklemeleri veya web tabanlı uygulamaların yasaklayıcı NSFW filtreleri.
Geliştirme hızı ve kullanıcıların özgür keşif hissi o kadar baş döndürücü bir hızla ilerliyor ki, çok ileriyi görmek zor. Esasen, henüz tam olarak neyle karşı karşıya olduğumuzu veya tüm sınırlamaların veya olasılıkların ne olabileceğini bilmiyoruz.
Bununla birlikte, hızla oluşan ve hızla büyüyen Stable Diffusion topluluğunun karşılaşabileceği ve umarız üstesinden gelebileceği en ilginç ve zorlu engellerden üçüne bir göz atalım.
1: Döşeme Tabanlı İşlem Hatlarını Optimize Etme
Sınırlı donanım kaynakları ve eğitim görüntülerinin çözünürlüğüne ilişkin katı sınırlamalar ile birlikte, geliştiricilerin Stable Diffusion çıktısının hem kalitesini hem de çözünürlüğünü iyileştirmek için geçici çözümler bulması muhtemel görünmektedir. Bu projelerin çoğu, yalnızca 512×512 piksellik doğal çözünürlüğü gibi sistemin sınırlamalarından yararlanmayı içerecek şekilde ayarlanmıştır.
Bilgisayarlı görme ve görüntü sentezi girişimlerinde her zaman olduğu gibi, Stabil Difüzyon, kare oranlı görüntüler üzerinde eğitildi; bu durumda 512x512 olarak yeniden örneklendi, böylece kaynak görüntüler düzenlenebildi ve GPU'ların kısıtlamalarına uyabildi. modeli eğittim.
Bu nedenle, Stable Diffusion (eğer düşünüyorsa) 512x512 piksel cinsinden ve kesinlikle kare cinsinden 'düşünür'. Sistemin sınırlarını araştıran birçok kullanıcı, Stable Diffusion'ın bu oldukça kısıtlı en boy oranında en güvenilir ve en az sorunlu sonuçları ürettiğini bildiriyor (aşağıdaki 'uç noktalara değinme' bölümüne bakın).
Çeşitli uygulamalarda yükseltme özelliği olsa da gerçekESRGAN (ve kötü oluşturulmuş yüzleri GPGAN) birkaç kullanıcı şu anda görüntüleri 512x512 piksellik bölümlere ayırmak ve daha büyük kompozit işler oluşturmak için görüntüleri birleştirmek için yöntemler geliştiriyor.

Bu 1024×576 işleme, tek bir Kararlı Difüzyon oluşturmada genellikle imkansız olan bir çözünürlük, dikkat.py Python dosyasının kopyalanıp yapıştırılmasıyla oluşturuldu. DoggettX Kararlı Difüzyon çatalı (karo tabanlı yükseltme uygulayan bir sürüm) başka bir çatala. Kaynak: https://old.reddit.com/r/StableDiffusion/comments/x6yeam/1024x576_with_6gb_nice/
Bu türden bazı girişimler orijinal kod veya diğer kitaplıkları kullanıyor olsa da, txt2imghd bağlantı noktası GOBIG (VRAM'e aç ProgRockDiffusion'daki bir mod), bu işlevselliği yakında ana şubeye sağlayacak şekilde ayarlanmıştır. txt2imghd, GOBIG'in özel bir bağlantı noktası olsa da, topluluk geliştiricilerinin diğer çabaları, GOBIG'in farklı uygulamalarını içerir.

Orijinal 512x512 piksellik render'da (solda ve soldan ikinci) kullanışlı bir soyut görüntü; artık tüm Stable Diffusion dağıtımlarında az çok yerel olan ESGRAN tarafından ölçeklendirilmiş; ve GOBIG'in bir uygulaması aracılığıyla 'özel ilgi' görmüş, en azından görüntü bölümünün sınırları içinde daha iyi ölçeklendirilmiş gibi görünen ayrıntılar üretmiş.kaynak: https://old.reddit.com/r/StableDiffusion/comments/x72460/stable_diffusion_gobig_txt2imghd_easy_mode_colab/
Yukarıda yer alan soyut örnek türü, ölçeklemeye yönelik bu bencil yaklaşıma uyan birçok 'küçük krallık' ayrıntısına sahiptir, ancak tekrarlanmayan, tutarlı bir ölçekleme üretmek için daha zorlu kod odaklı çözümler gerektirebilir. bak Sanki birçok parçadan bir araya getirilmiş gibi. Özellikle de insan yüzleri söz konusu olduğunda, anormalliklere veya 'uyumsuz' eserlere alışılmadık derecede duyarlıyız. Bu nedenle, yüzler sonunda özel bir çözüme ihtiyaç duyabilir.
Stable Diffusion, şu anda insanların yüz bilgilerine öncelik vermesi gibi, bir render sırasında dikkati yüze odaklamak için bir mekanizmaya sahip değil. Discord topluluklarındaki bazı geliştiriciler bu tür bir "gelişmiş dikkat"i uygulamak için yöntemler düşünse de, ilk render tamamlandıktan sonra yüzü manuel olarak (ve nihayetinde otomatik olarak) geliştirmek şu anda çok daha kolay.
İnsan yüzünün, (örneğin) bir binanın alt köşesindeki bir 'karoda' bulunamayacak içsel ve tam bir semantik mantığı vardır ve bu nedenle şu anda Stable Diffusion çıktısında 'taslak' bir yüzü çok etkili bir şekilde 'yakınlaştırmak' ve yeniden oluşturmak mümkündür.

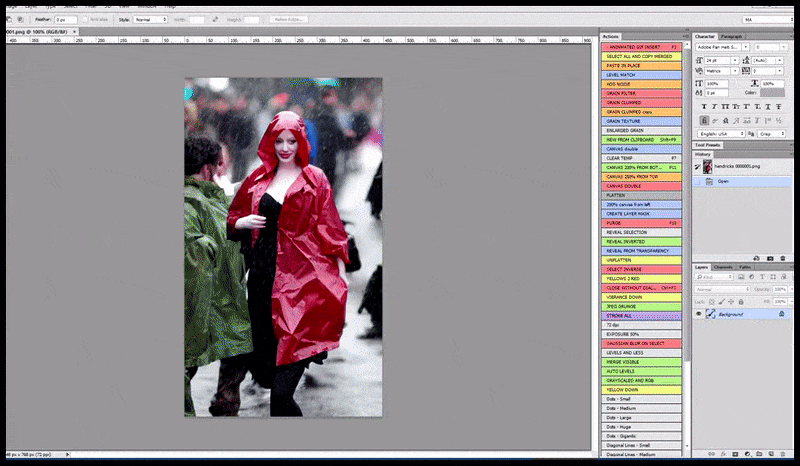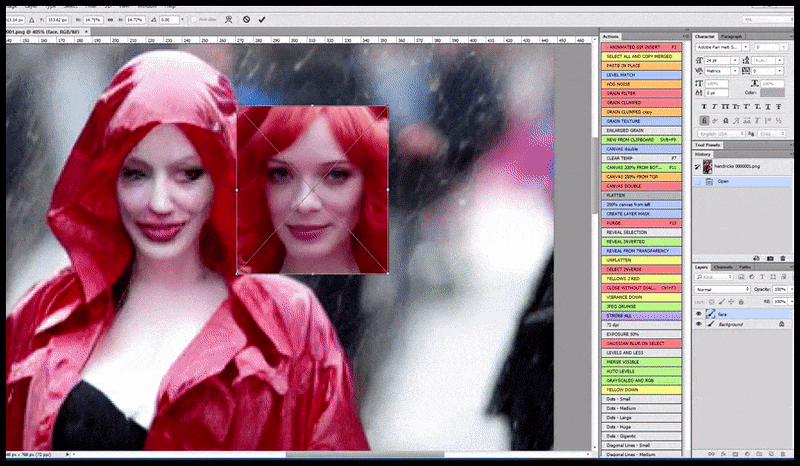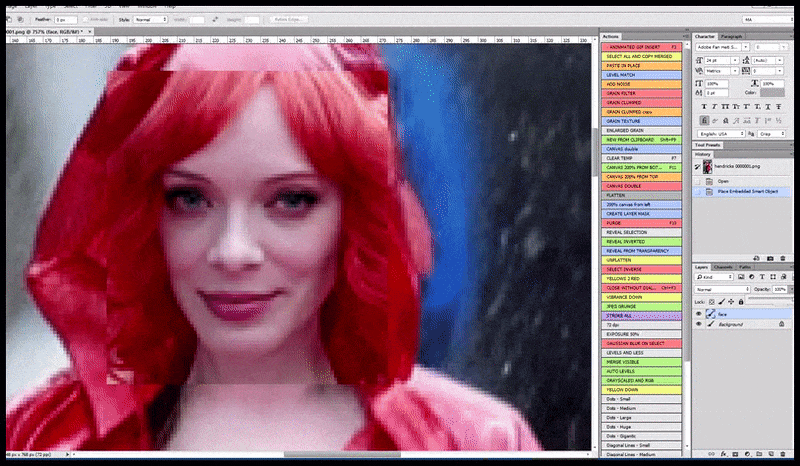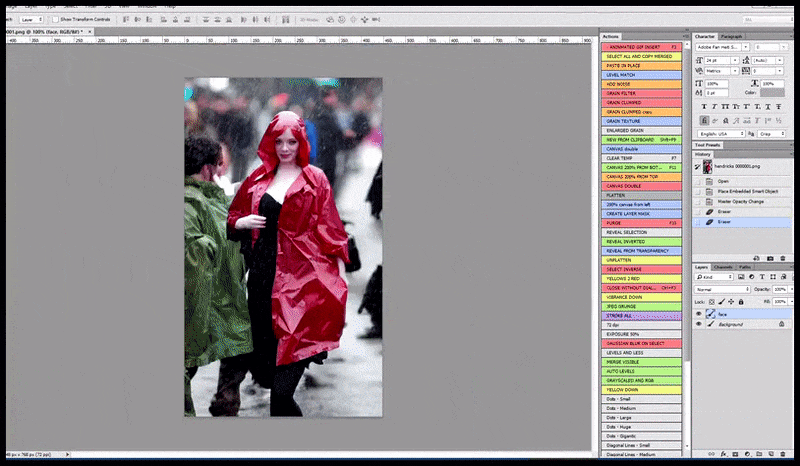
Solda, Stable Diffusion'ın "Kalabalık bir yere giren Christina Hendricks'in yağmurluk giymiş haldeki tam boy renkli fotoğrafı; Canon50, göz teması, yüksek detay, yüksek yüz detayı" komut istemiyle ilk çalışması. Sağda, ilk render'daki bulanık ve taslak yüzün Img2Img kullanılarak Stable Diffusion'ın tüm dikkatine geri gönderilmesiyle elde edilen iyileştirilmiş bir yüz (aşağıdaki hareketli görsellere bakın).
Özel bir Metinsel Tersine Çevirme çözümünün yokluğunda (aşağıya bakın), bu yalnızca söz konusu kişinin Stable Difusion'ı eğiten LAION veri altkümelerinde zaten iyi bir şekilde temsil edildiği ünlü resimleri için işe yarayacaktır. Bu nedenle, Tom Cruise, Brad Pitt, Jennifer Lawrence ve kaynak verilerde çok sayıda görüntüde bulunan sınırlı sayıda gerçek medya aydınları üzerinde çalışacaktır.
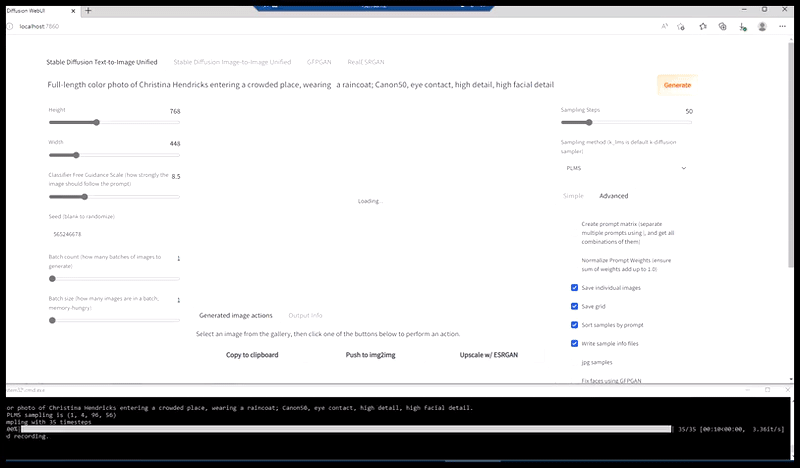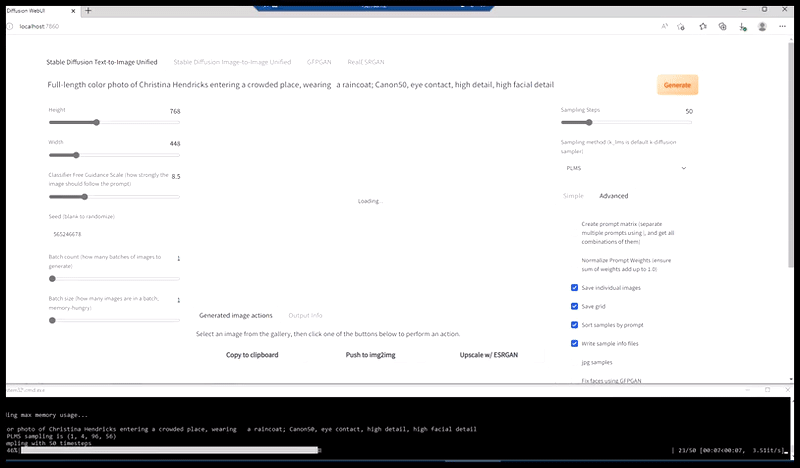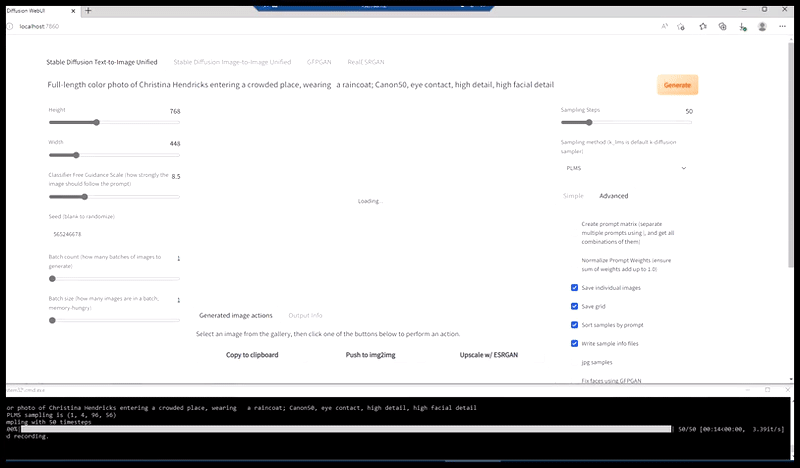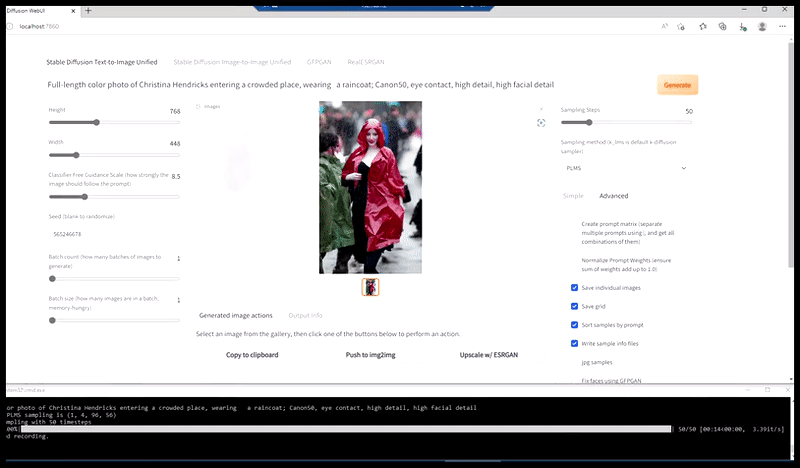
Christina Hendricks'in kalabalık bir yere girerken yağmurluk giydiği tam boy renkli fotoğraf; Canon50, göz teması, yüksek detay, yüksek yüz detayı' şeklinde bir mesajla makul bir basın fotoğrafı oluşturmak.
Uzun ve kalıcı bir kariyere sahip ünlüler için, Stable Difusion genellikle kişinin yakın tarihli (yani daha yaşlı) bir görüntüsünü oluşturur ve aşağıdaki gibi hızlı eklerin eklenmesi gerekir. 'genç' or 'yıl [YIL]'da' Daha genç görünen görüntüler elde etmek için.

Yaklaşık 40 yıla yayılan önemli, çok fotoğraflanan ve tutarlı bir kariyere sahip olan aktris Jennifer Connelly, LAION'da Stable Diffusion'ın bir yaş aralığını temsil etmesine izin veren bir avuç ünlüden biridir. Kaynak: önceden paketlenmiş Kararlı Difüzyon, yerel, v1.4 kontrol noktası; yaşla ilgili istemler.
Bunun başlıca nedeni, 2000'lerin ortalarından itibaren dijital (pahalı, emülsiyon tabanlı değil) basın fotoğrafçılığının çoğalması ve daha sonra artan geniş bant hızları nedeniyle görüntü çıktı hacmindeki büyümedir.
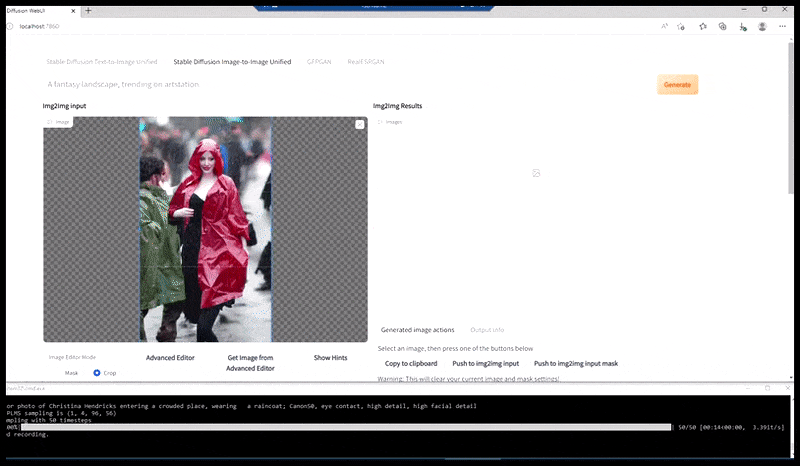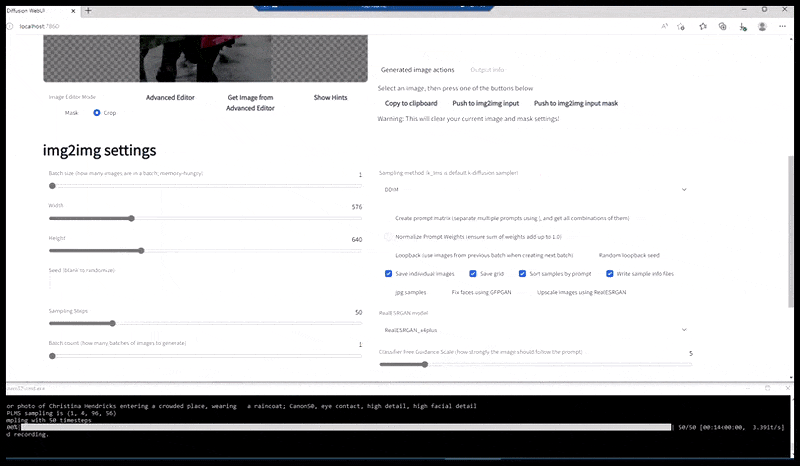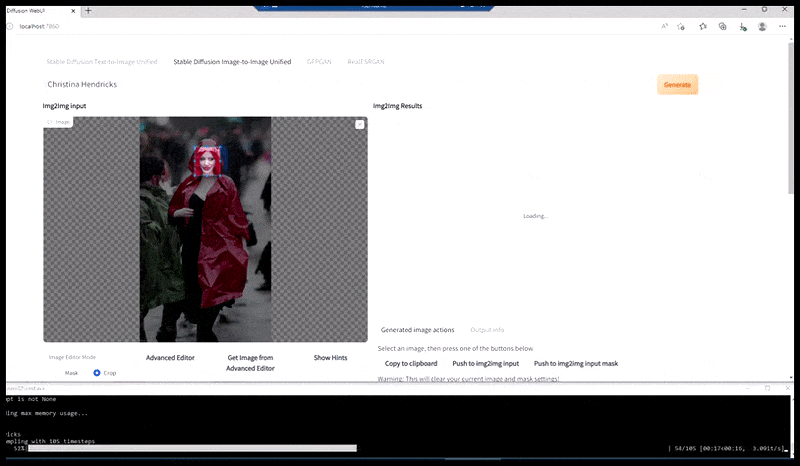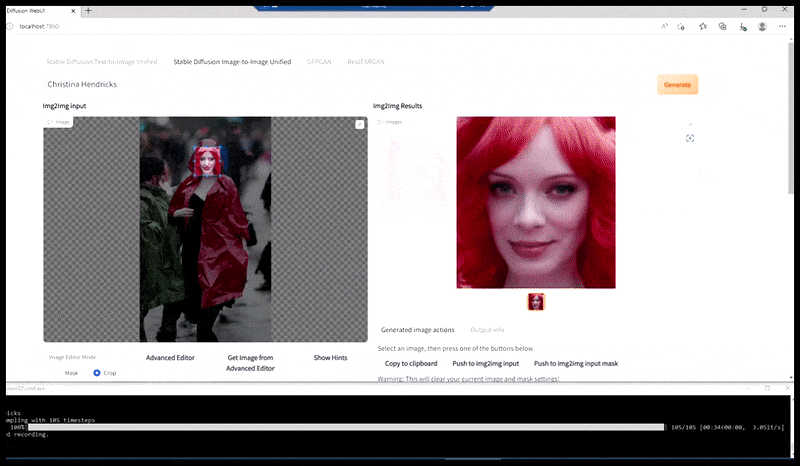
İşlenen görüntü, Stable Diffusion'daki Img2Img'ye aktarılır, burada bir 'odak alanı' seçilir ve yalnızca o alandan yeni, maksimum boyutlu bir işleme yapılır. Bu, Stable Diffusion'ın tüm mevcut kaynaklarını yüzü yeniden oluşturmaya yoğunlaştırmasına olanak tanır.
'Yüksek dikkat' gerektiren yüzün orijinal render'a geri eklenmesi. Bu işlem, yüzlerin yanı sıra, yalnızca potansiyel olarak bilinen, tutarlı ve bütünsel bir görünüme sahip varlıklarla, örneğin orijinal fotoğrafın saat veya araba gibi belirgin bir nesneye sahip bir bölümüyle çalışır. Örneğin, bir duvarın bir bölümünün boyutunu büyütmek, çok tuhaf görünümlü, yeniden birleştirilmiş bir duvara yol açacaktır, çünkü fayans render'ları render edilirken bu 'yapboz parçası' için daha geniş bir bağlam sunmamıştır.
Veritabanındaki bazı ünlüler, ya erken yaşta öldükleri (Marilyn Monroe gibi) ya da yalnızca kısa süreli bir popülerlik kazandıkları için zaman içinde 'önceden dondurulmuş' halde gelir ve sınırlı bir süre içinde çok sayıda görüntü üretirler. Polling Stable Diffusion, tartışmasız bir şekilde modern ve yaşlı yıldızlar için bir tür 'güncel' popülerlik endeksi sağlar. Bazı yaşlı ve güncel ünlüler için, kaynak verilerde çok iyi bir benzerlik elde etmeye yetecek kadar görüntü bulunmazken, uzun zaman önce ölmüş veya başka bir şekilde sönmüş belirli yıldızların kalıcı popülaritesi, sistemden makul bir benzerlik elde edilebilmesini sağlar.

Kararlı Difüzyon oluşturmaları, eğitim verilerinde hangi ünlü yüzlerin iyi temsil edildiğini hızla ortaya çıkarır. Yazma sırasında daha yaşlı bir genç olarak muazzam popülaritesine rağmen, Millie Bobby Brown daha gençti ve LAION kaynak veri kümeleri web'den kazındığında daha az tanınıyordu, bu da şu anda Stable Difüzyon ile yüksek kaliteli bir benzerliği sorunlu hale getiriyordu.
Verilerin mevcut olduğu yerlerde, Stable Diffusion'daki karo tabanlı yüksek çözünürlüklü çözümler yüze odaklanmaktan daha ileri gidebilir: yüz hatlarını kırarak ve yerel GPU'nun tüm gücünü çevirerek potansiyel olarak daha da doğru ve ayrıntılı yüzler sağlayabilirler. Yeniden birleştirmeden önce, göze çarpan özelliklerle ilgili kaynaklar, şu anda yine manuel olan bir süreçtir.

Bu, yüzlerle sınırlı değildir, ancak ana nesnenin daha geniş bağlamına en azından öngörülebilir şekilde yerleştirilmiş ve hiper ölçekte bulmayı makul bir şekilde bekleyebileceğimiz üst düzey katıştırmalara uyan nesnelerin parçalarıyla sınırlıdır. veri kümesi.
Gerçek sınır, veri setinde mevcut referans verisinin miktarıdır, çünkü sonunda, derinlemesine yinelenen ayrıntılar tamamen 'halüsinasyon' (yani kurgusal) haline gelecek ve daha az gerçekçi olacaktır.
Jennifer Connelly'nin durumunda bu tür üst düzey ayrıntılı genişlemeler işe yarıyor çünkü o, çeşitli yaşlarda iyi bir şekilde temsil ediliyor. LAION estetiği (birincil altkümesi LAYON 5B Kararlı Yayılımın kullandığı) ve genel olarak LAION genelinde; diğer birçok durumda, doğruluk veri eksikliğinden etkilenecek ve bu da ya ince ayar (ek eğitim, aşağıdaki 'Özelleştirme'ye bakın) ya da Metinsel Tersine Çevirme (aşağıya bakın) gerektirecektir.
Döşemeler, Stable Difüzyon'un yüksek çözünürlüklü çıktı üretmesini sağlamak için güçlü ve nispeten ucuz bir yoldur, ancak bu türden algoritmik döşemeli yükseltme, bir tür daha geniş, daha yüksek seviyeli dikkat mekanizmasından yoksunsa, umulan- çeşitli içerik türlerinde standartlar için.
2: İnsan Uzuvlarıyla İlgili Sorunları Ele Alma
Kararlı Difüzyon, insan uzuvlarının karmaşıklığını tasvir ederken ismine yakışmıyor. Eller rastgele çoğalabilir, parmaklar birleşebilir, üçüncü bacaklar kendiliğinden ortaya çıkabilir ve mevcut uzuvlar iz bırakmadan yok olabilir. Savunmasında, Kararlı Difüzyon bu sorunu ahır arkadaşlarıyla ve kesinlikle DALL-E 2 ile paylaşıyor.

Ağustos 2 sonu itibarıyla DALL-E 1.4 ve Stable Diffusion (2022)'dan elde edilen düzenlenmemiş sonuçlar, her ikisi de uzuvlarla ilgili sorunlar gösteriyor. Komut "Bir erkeğe sarılan bir kadın"
Yaklaşan 1.5 kontrol noktasının (modelin geliştirilmiş parametrelerle daha yoğun bir şekilde eğitilmiş bir versiyonu) uzuv karışıklığını çözeceğini uman Kararlı Difüzyon hayranları muhtemelen hayal kırıklığına uğrayacaklar. XNUMX yılında piyasaya sürülecek olan yeni model yaklaşık iki hafta içinde, şu anda ticari stable.ai portalında prömiyeri yapılıyor Rüya Stüdyosu, varsayılan olarak 1.5 kullanan ve kullanıcıların yeni çıktıyı yerel veya diğer 1.4 sistemlerindeki işlemelerle karşılaştırabileceği yer:

Kaynak: Yerel 1.4 ön paketi ve https://beta.dreamstudio.ai/

Kaynak: Yerel 1.4 ön paketi ve https://beta.dreamstudio.ai/

Kaynak: Yerel 1.4 ön paketi ve https://beta.dreamstudio.ai/
Çoğu zaman olduğu gibi, veri kalitesi buna katkıda bulunan birincil neden olabilir.
Stable Diffusion ve DALL-E 2 gibi görüntü sentez sistemlerini besleyen açık kaynaklı veritabanları, hem bireysel insanlar hem de insanlar arası eylem için birçok etiket sağlayabilir. Bu etiketler, ilişkili görüntüleri veya görüntü segmentleri ile simbiyotik olarak eğitilirler.

Stable Diffusion kullanıcıları, sisteme güç sağlayan daha büyük LAION 5B veri setinin bir alt kümesi olan LAION-estetik veri setini sorgulayarak modele entegre edilen kavramları keşfedebilirler. Görüntüler alfabetik etiketlerine göre değil, "estetik puanlarına" göre sıralanır. Kaynak: https://rom1504.github.io/clip-retrieval/
A iyi hiyerarşi Bir insan kolunun tasvirine katkıda bulunan Bireysel etiketlerin ve sınıfların sayısı, şuna benzer bir şey olurdu: vücut>kol>el>parmaklar>[alt basamaklar + başparmak]> [rakam bölümleri]>Tırnaklar.

Bir elin bölümlerinin ayrıntılı anlamsal bölümlenmesi. Bu alışılmadık derecede ayrıntılı yapıbozumu bile, her bir 'parmağı' tek bir varlık olarak bırakıyor; bir parmağın üç bölümünü ve bir başparmağın iki bölümünü hesaba katmıyor. Kaynak: https://athitsos.utasites.cloud/publications/rezaei_petra2021.pdf
Gerçekte, kaynak görüntülerin tüm veri kümesi boyunca bu kadar tutarlı bir şekilde açıklanması olası değildir ve denetimsiz etiketleme algoritmaları muhtemelen en son noktada duracaktır. daha yüksek Örneğin, 'el' seviyesinde, iç pikselleri (teknik olarak 'parmak' bilgisini içeren) özelliklerin keyfi olarak türetileceği ve daha sonraki renderlarda uyumsuz bir öğe olarak ortaya çıkabilecek etiketlenmemiş bir piksel kütlesi olarak bırakın.

Etiketleme için sınırlı kaynaklar veya veri kümesinde varsa bu tür etiketlerin mimari kullanımı nedeniyle nasıl olması gerektiği (üst kesim değilse sağ üst) ve nasıl olma eğiliminde olduğu (sağ alt).
Bu nedenle, gizli bir yayılma modeli bir kolun görüntüsünü oluşturmaya kadar giderse, o kolun ucunda bir el görüntüsü oluşturmayı da neredeyse kesinlikle deneyecektir, çünkü kol>el mimarlığın 'insan anatomisi' hakkında bildikleri arasında oldukça yukarıda yer alan asgari gereklilik hiyerarşisidir.
İnsan ellerini tasvir ederken dikkate alınması gereken 14 tane daha parmak/başparmak alt parçası olmasına rağmen, bundan sonra en küçük gruplama 'parmaklar' olabilir.
Bu teori geçerliyse, manuel açıklama için sektör çapında bütçe eksikliği ve düşük hata oranları üretirken etiketlemeyi otomatikleştirebilecek yeterince etkili algoritmaların olmaması nedeniyle gerçek bir çare yoktur. Gerçekte, model şu anda üzerinde eğitildiği veri kümesinin eksikliklerini gidermek için insan anatomik tutarlılığına güveniyor olabilir.
Bunun olası bir nedeni yapamaz buna güven, son zamanlarda önerilen Kararlı Difüzyon Uyuşmazlığında, modelin (gerçekçi) bir insan elinin sahip olması gereken doğru parmak sayısı konusunda kafasının karışabilmesidir, çünkü ona güç veren LAION'dan türetilmiş veri tabanı, daha az parmağa sahip olabilecek çizgi film karakterleri içerir (ki bu kendi içindedir) emek tasarrufu sağlayan bir kısayol).

Kararlı Difüzyon ve benzeri modellerde 'eksik parmak' sendromunun potansiyel suçlularından ikisi. Aşağıda, Kararlı Difüzyon'u destekleyen LAION estetik veri setinden çizgi film el örnekleri yer almaktadır. Kaynak: https://www.youtube.com/watch?v=0QZFQ3gbd6I
Bu doğruysa, o zaman tek bariz çözüm, modeli yeniden eğitmek, gerçekçi olmayan insan temelli içeriği hariç tutmak ve gerçek ihmal vakalarının (örn. amputeler) istisnalar olarak uygun bir şekilde etiketlenmesini sağlamaktır. Yalnızca bir veri düzenleme noktasından bakıldığında, bu, özellikle kaynak sıkıntısı çeken topluluk çabaları için oldukça zor olacaktır.
İkinci yaklaşım, OpenAI'nin bir dereceye kadar yaptığı gibi, bu tür içeriğin (yani 'üç/beş parmaklı el') render zamanında ortaya çıkmasını engelleyen filtreler uygulamak olacaktır. süzülmüş GPT-3 ve DALL-E2, böylece kaynak modelleri yeniden eğitmeye gerek kalmadan çıktıları düzenlenebilir.

Stable Diffusion'da parmaklar ve hatta uzuvlar arasındaki anlamsal ayrım korkunç derecede bulanıklaşabiliyor ve bu da David Cronenberg gibi yönetmenlerin 1980'lerdeki korku filmlerindeki 'vücut korkusu' akımını akla getiriyor. Kaynak: https://old.reddit.com/r/StableDiffusion/comments/x6htf6/a_study_of_stable_diffusions_strange_relationship/
Ancak, yine, bu, etkilenen tüm görüntülerde bulunmayabilecek etiketleri gerektirecek ve bizi aynı lojistik ve bütçesel zorluklarla karşı karşıya bırakacaktır.
İleriye doğru atılacak iki adım olduğu söylenebilir: soruna daha fazla veri göndermek ve burada anlatılan türden fiziksel hatalar son kullanıcıya sunulduğunda müdahale edebilecek üçüncü taraf yorumlayıcı sistemler kullanmak (en azından ikincisi, şirketin bunu yapmaya motive olması durumunda OpenAI'ye 'vücut korkusu' render'ları için para iadesi sağlama yöntemi sunacaktır).
3: Özelleştirme
Stable Difusion'ın geleceği için en heyecan verici olasılıklardan biri, gözden geçirilmiş sistemler geliştiren kullanıcıların veya kuruluşların olasılığıdır; önceden eğitilmiş LAION alanının dışındaki içeriğin sisteme entegre edilmesine izin veren modifikasyonlar - ideal olarak, tüm modeli yeniden eğitmenin yönetilemeyen masrafı veya mevcut, olgun ve yetenekli bir görüntüye büyük hacimli yeni görüntülerde eğitim yaparken ortaya çıkan risk olmadan. modeli.
Benzer şekilde: Daha az yetenekli iki öğrenci otuz kişilik ileri seviye bir sınıfa katılırsa, ya uyum sağlayıp yetişecekler ya da aykırı olarak başarısız olacaklar; her iki durumda da sınıf ortalaması muhtemelen etkilenmeyecektir. Ancak, 15 daha az yetenekli öğrenci katılırsa, tüm sınıfın not eğrisi muhtemelen olumsuz etkilenecektir.
Aynı şekilde, uzun süreli ve pahalı model eğitimi üzerine kurulan sinerjik ve oldukça hassas ilişkiler ağı, aşırı yeni veriler tarafından tehlikeye atılabilir, bazı durumlarda etkili bir şekilde yok edilebilir ve modelin çıktı kalitesini genel olarak düşürür.
Bunu yapmanın temel nedeni, modelin ilişkiler ve nesneler hakkındaki kavramsal anlayışını tamamen ele geçirip, eklediğiniz ek materyale benzer içeriklerin özel üretimi için kullanmak istemenizdir.
Böylece 500,000 eğitim Simpsonlar çerçeveleri mevcut bir Kararlı Difüzyon kontrol noktasına dönüştürmek, sonunda size daha iyi bir Simpsonlar Yeterince geniş semantik ilişkilerin süreçten sağ çıktığı varsayıldığında (örn. Homer Simpson sosisli sandviç yiyor(ek materyalinizde olmayan ancak kontrol noktasında zaten mevcut olan sosisli sandviçlerle ilgili materyal gerektirebilir) ve aniden kontrol noktasından geçiş yapmak istemediğinizi varsayarak Simpsonlar oluşturulacak içerik Greg Rutkowski'den muhteşem manzara – çünkü eğittiğiniz modelin dikkati büyük ölçüde dağılmış olacak ve artık eskisi kadar iyi olmayacak.
Bunun dikkate değer bir örneği, waifu-difüzyon, başarılı bir şekilde eğitim sonrası 56,000 anime görüntüsü Tamamlanmış ve eğitilmiş bir Kararlı Difüzyon kontrol noktasına dönüştürmek. Ancak bu, bir hobi meraklısı için zorlu bir ihtimal, çünkü model, NVIDIA'nın önümüzdeki 30XX serisi sürümlerinde tüketici seviyesinde bulunması muhtemel olanın çok ötesinde, göz yaşartıcı bir minimum 40 GB VRAM gerektiriyor.

Waifu-difüzyon yoluyla Stable Diffusion'a özel içeriğin eğitimi: modelin bu seviyede bir çizim çıkarması için iki haftalık eğitim sonrası eğitim aldı. Soldaki altı resim, eğitim ilerledikçe modelin yeni eğitim verilerine dayalı konu tutarlı çıktılar elde etmedeki ilerlemesini gösterir. Kaynak: https://gigazine.net/gsc_news/en/20220121-how-waifu-labs-create/
Kararlı Difüzyon kontrol noktalarının bu tür "çatallarına" büyük çaba harcanabilir, ancak teknik borçlar nedeniyle bu çabalar engellenebilir. Resmi Discord'daki geliştiriciler, daha sonraki kontrol noktası sürümlerinin, önceki bir sürümle çalışmış olabilecek hızlı mantıkla bile, geriye dönük uyumlu olmayacağını belirttiler; çünkü onların öncelikli amacı, eski uygulamaları ve süreçleri desteklemek yerine mümkün olan en iyi modeli elde etmek.
Dolayısıyla bir kontrol noktasını ticari bir ürüne dönüştürmeye karar veren bir şirket veya bireyin geri dönüşü yoktur; bu noktada onların model versiyonu bir 'sert çatallanma'dır ve stability.ai'nin sonraki sürümlerinden gelen yukarı akış faydalarını elde edemeyecektir; bu da oldukça büyük bir taahhüttür.
Kararlı Difüzyonun özelleştirilmesi için mevcut ve daha büyük umut, Metin Tersine Çevirme, kullanıcının küçük bir avuç içinde eğittiği CLIPhizalanmış görüntüler.

Tel Aviv Üniversitesi ile NVIDIA arasındaki bir işbirliği olan metinsel ters çevirme, kaynak modelin yeteneklerini yok etmeden ayrık ve yeni varlıkların eğitimine olanak tanır. Kaynak: https://textual-inversion.github.io/
Metni tersine çevirmenin birincil belirgin sınırlaması, çok az sayıda görüntünün önerilmesidir - beş kadar az. Bu, fotogerçekçi nesnelerin eklenmesinden ziyade stil aktarma görevleri için daha yararlı olabilecek sınırlı bir öğeyi etkili bir şekilde üretir.
Bununla birlikte, şu anda çok daha fazla sayıda eğitim görüntüsü kullanan çeşitli Kararlı Difüzyon Uyuşmazlıklarında deneyler yapılıyor ve yöntemin ne kadar verimli olacağını göreceğiz. Yine, teknik çok fazla VRAM, zaman ve sabır gerektirir.
Bu sınırlayıcı faktörler nedeniyle, Stable Diffusion meraklılarının daha gelişmiş metinsel ters çevirme deneylerinden bazılarını görmek için bir süre beklememiz gerekebilir - ve bu yaklaşımın, resmi kontrol noktalarının şaşırtıcı işlevselliğini korurken, Photoshop'ta kes-yapıştır yapmaktan daha iyi görünen bir şekilde sizi 'resmin içine' yerleştirip yerleştiremeyeceğini görmek için.
İlk olarak 6 Eylül 2022'de yayınlandı.












