Yapay Zekâ
%75 Tavanı: AI Modelleri Mevcut Yöntemlerle Zirve Performansa Ulaştı mı?

Anthropic ve OpenAI iki gün arayla sınır AI modellerini ortaya çıkardı ve her ikisi de endüstriyel kodlama benchmark’lerinde neredeyse aynı 74-75% doğruluk oranına ulaştı, bu da mevcut AI mimarileri için potansiyel bir performans tavanını gösteriyor ve dağıtım ve uygulama açısından dramatik olarak farklı yaklaşımlar benimsedi.
Yakın zamanda yapılan açıklamalar, AI gelişiminin mevcut eğitim yöntemleriyle bir düzleğe ulaşıp ulaşmadığını sorgulayan temel soruları gündeme getiriyor, şirketler ise bu yetenekleri dünya çapındaki kullanıcılar ve geliştiricilere nasıl sunacakları konusunda keskin bir şekilde ayrışıyor.
Benchmark Birleşme Teknik Bir Miletaşa İşaret Ediyor
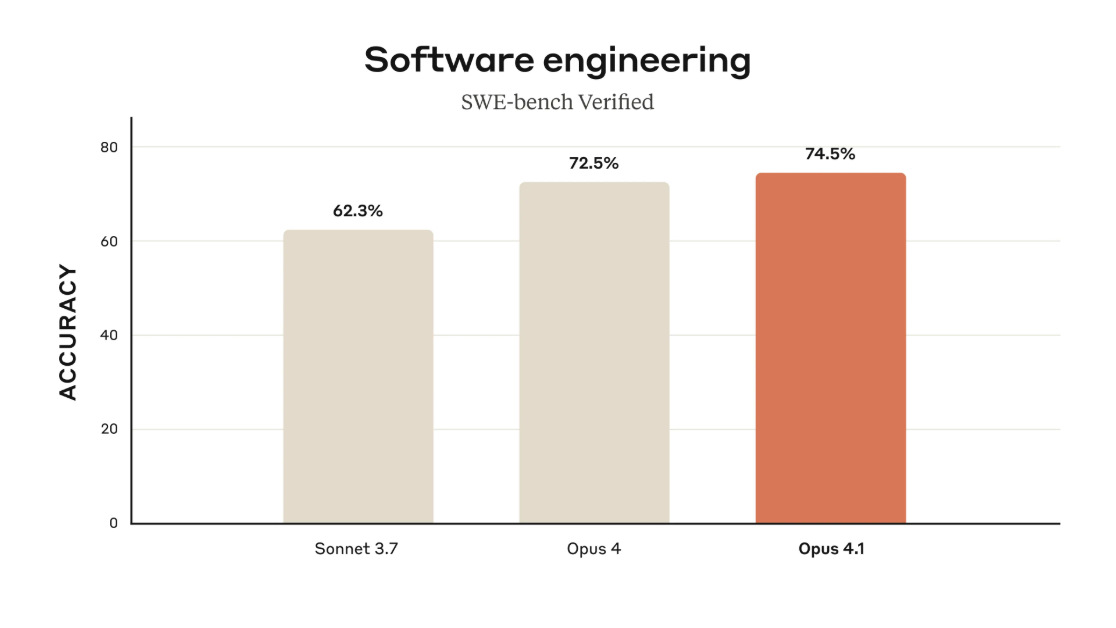
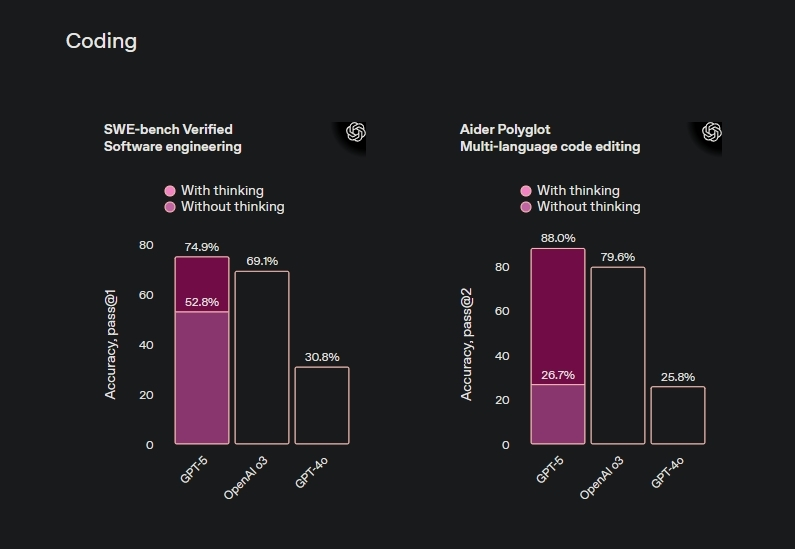
Claude Opus 4.1, 5 Ağustos’ta Anthropic tarafından yayınlandı ve endüstrinin standardı olan SWE-bench Verified’de %74,5 puan aldı. OpenAI’nin GPT-5 modeli, 7 Ağustos’ta açıklandı ve aynı testte %74,9 puan aldı – bu, her iki şirketin de bağımsız olarak çalışmasına rağmen mevcut mimarilere benzer sınırlara ulaştığını gösteren istatistiksel bir bağdır.
Modeller arasındaki %0,4’lük fark, böyle bir benchmark için istatistiksel gürültü marjı içinde kalıyor.
Mimari yaklaşımlar ise önemli ölçüde farklılaşıyor. OpenAI, GPT-5 modelini akıllı yönlendirme ile çok model sistemi olarak inşa etti – sorgular basit görevler için hızlı yanıtlayanlara, karmaşık sorunlar için akıl yürütme modellerine veya hesaplanma limitlerine ulaşıldığında mini sürümlere yönlendiriliyor. Anthropic, Opus 4.1 ile tek model yaklaşımını korudu ve uzmanlaştırılmış optimizasyondan ziyade tutarlılığı önceliklendirdi.
Kaynak: Anthropic
Dağıtım Stratejileri Rekabetçi Felsefeleri Açığa Vuruyor
OpenAI, GPT-5 modelini hemen tüm ChatGPT kullanıcılarının erişimine açtı, bu da ücretsiz katmana sahip yaklaşık 700 milyon haftalık aktif kullanıcıya ulaşıyor. Microsoft aynı zamanda GPT-5 modelini GitHub Copilot, Visual Studio Code, M365 Copilot ve Azure platformları genelinde entegre etti.
Anthropic, daha geleneksel erişim kısıtlamalarını koruyor ve Opus 4.1 modelini yalnızca ücretli Claude kullanıcılarına sunuyor, geliştiriciler için Claude Code aracılığıyla ve API erişimini sağlıyor. Şirket, güvenilir ve tutarlı performans gerektiren geliştiriciler ve şirketlere hizmet vermeye odaklanmış görünüyor.
GPT-5’in fiyatlandırması agresif görünüyor ve geliştiriciler, rekabetçileri fiyatlandırma stratejilerini ayarlamaya zorlayabilecek olumlu maliyet-kapasite oranları olduğunu belirtiyorlar.
Altyapı Talepleri Endüstri Ekonomisini Yeniden Şekillendiriyor
Hesaplanma gereksinimleri, ön cephe AI gelişiminin devasa ölçekliğini ortaya koyuyor. OpenAI’nin Oracle ile yıllık 30 milyar dolarlık bir kapasite sözleşmesi olduğu bildiriliyor ve GPT-5 modelini Microsoft Azure’da NVIDIA H200 GPU’ları kullanarak eğitti. Meta, 2025 yılında alone AI altyapısı için 72 milyar dolar harcama yapma planlarını açıkladı.
Her iki şirket de, ham benchmark’lerin ötesinde pratik uygulamalarda önemli iyileştirmeler olduğunu bildiriyor. OpenAI, GPT-5 modelinin web araması etkinleştirildiğinde “GPT-4o” modeline göre yaklaşık %45 daha az hata gösterdiğini belirtiyor ve düşünme modu, daha az token kullanarak o3 modeline benzer sonuçlar elde ediyor – bu, önemli bir verimlilik kazancı anlamına geliyor.
GitHub, Opus 4.1 modelinin “çok dosyalı kod yeniden düzenlemede önemli performans kazançları” gösterdiğini bildirirken, popüler bir AI kod asistanı olan Cursor, GPT-5 modelini “şaşırtıcı derecede zeki ve yönlendirmesi kolay” olarak tanımlıyor – bu, OpenAI’nin geliştirici belgelerine göre bir açıklama.
Kaynak: OpenAI
Teknik Tavan Paradigma Değişimini Öne Sürüyor
Benzer performans metriklerine ulaşan şirketlerin birleşmesi, mevcut eğitim paradigmalarının sınırlarına yaklaştığını gösteriyor. Farklı şirketlerin %74-75% doğruluk oranına ulaşması, kodlama benchmark’lerinde next büyük iyileştirmelerin temel yenilikler gerektirebileceğini gösteriyor.
OpenAI’nin karmaşık yönlendirme sistemi ile Anthropic’in birleşik yaklaşımı arasındaki mimari ticaret, net bir kazanan olmadan farklı felsefeleri yansıtıyor. GPT-5 modelinin çok model sistemi esneklik sunuyor ancak potansiyel hata noktaları tanıyor, Claude modelinin tutarlılığı ise uzmanlaştırılmış performans için güvenilirlikten fedakarlık ediyor.
Ön cephe AI yeteneklerinin demokratikleştirilmesi – iki yıl önce yıllık binlerce dolar maliyeti olan özellikler artık ücretsiz olarak sunuluyor – endüstriler genelinde benimsenmeyi hızlandırıyor. AI’nin premium hizmetten altyapıya dönüşümü, tamamen yeni uygulama kategorilerini mümkün kılabilir.
Pazar İmpilikasyonları ve Sonraki Adımlar
Sektör gözlemcileri, Anthropic’in OpenAI’nin fiyatlandırma stratejisine yanıt vereceğini bekliyor, ancak muhtemelen doğrudan fiyat eşleştirmesi yoluyla değil. Google’ın DeepMind ve Meta, bu açıklamalar sırasında nispeten sessiz kaldı ve önümüzdeki aylarda hamleler yapacakları öngörülüyor.
48 saatlik açıklama penceresi, AI’nin deneysel teknolojisinden güvenilir altyapıya geçişini ortaya koydu. Şirketler benchmark skorlarında neredeyse aynı olduğunda, rekabet ham performans metriklerinden dağıtım verimliliği, entegrasyon kalitesi ve hizmet güvenilirliğine kayıyor.
Pratik iyileştirmeler benchmark üstünlüğünden daha önemli hale geliyor. SWE-bench Verified, bir AI’nin açık kaynaklı yazılımlardaki gerçek hataları tanıma ve düzeltme yeteneğini ölçüyor ve her iki modelin puanları, otonom kodlama yeteneklerinde önemli ilerlemeleri temsil ediyor.
AI modelleri, akıl yürütme ve kodlama yeteneklerinde giderek daha sofistike hale geldikçe, rekabet ham performans metriklerinden pratik uygulamaya ve üretim ortamlarındaki güvenilirliğe kayıyor. Şaşırtıcı gerçek, bu istikrarın bir başka đột phádan daha fazla dönüşümsel değişiklik ermögelayabilir.












