Yapay Zeka
Kod Gömme: Kapsamlı Bir Kılavuz

Kod yerleştirmeleri, kod parçacıklarını sürekli bir alanda yoğun vektörler olarak temsil etmenin dönüştürücü bir yoludur. Bu yerleştirmeler, kod parçacıkları arasındaki anlamsal ve işlevsel ilişkileri yakalayarak yapay zeka destekli programlamada güçlü uygulamalara olanak tanır. Doğal dil işlemedeki (NLP) kelime yerleştirmelere benzer şekilde, kod yerleştirmeler de benzer kod parçacıklarını vektör uzayında birbirine yakın konumlandırarak makinelerin kodu daha etkili bir şekilde anlamasına ve işlemesine olanak tanır.
Kod Yerleştirmeleri nedir?
Kod yerleştirmeleri, karmaşık kod yapılarını, kodun anlamını ve işlevselliğini yakalayan sayısal vektörlere dönüştürür. Kodu karakter dizileri olarak ele alan geleneksel yöntemlerin aksine, yerleştirmeler kodun parçaları arasındaki anlamsal ilişkileri yakalar. Bu, kod arama, tamamlama, hata tespiti ve daha fazlası gibi çeşitli yapay zeka odaklı yazılım mühendisliği görevleri için çok önemlidir.
Örneğin şu iki Python fonksiyonunu göz önünde bulundurun:
def add_numbers(a, b):
return a + b
def sum_two_values(x, y):
result = x + y
return result
Bu işlevler sözdizimsel olarak farklı görünse de aynı işlemi gerçekleştirirler. İyi bir kod yerleştirme, bu iki işlevi benzer vektörlerle temsil edecek ve metinsel farklılıklarına rağmen işlevsel benzerliklerini yakalayacaktır.

Vektör Gömme
Kod Yerleştirmeleri Nasıl Oluşturulur?
Kod yerleştirmeleri oluşturmak için farklı teknikler vardır. Yaygın bir yaklaşım, bu temsilleri büyük bir kod veri kümesinden öğrenmek için sinir ağlarının kullanılmasını içerir. Ağ, farklı kod parçacıkları arasındaki ilişkileri öğrenmek için belirteçler (anahtar kelimeler, tanımlayıcılar), sözdizimi (kodun nasıl yapılandırıldığı) ve potansiyel olarak yorumlar dahil olmak üzere kod yapısını analiz eder.
Süreci parçalayalım:
- Sıra Olarak Kod: İlk olarak, kod parçacıkları jeton dizileri (değişkenler, anahtar kelimeler, operatörler) olarak ele alınır.
- Sinir Ağı Eğitimi: Bir sinir ağı bu dizileri işler ve bunları sabit boyutlu vektör temsilleriyle eşleştirmeyi öğrenir. Ağ, sözdizimi, anlambilim ve kod öğeleri arasındaki ilişkiler gibi faktörleri dikkate alır.
- Benzerlikleri Yakalamak: Eğitim, benzer kod parçacıklarını (benzer işlevselliğe sahip) vektör uzayında birbirine yakın konumlandırmayı amaçlamaktadır. Bu, benzer kodu bulma veya işlevleri karşılaştırma gibi görevlere olanak tanır.
İşte gömme işlemi için kodu nasıl ön işleyebileceğinize dair basitleştirilmiş bir Python örneği:
import ast
def tokenize_code(code_string):
tree = ast.parse(code_string)
tokens = []
for node in ast.walk(tree):
if isinstance(node, ast.Name):
tokens.append(node.id)
elif isinstance(node, ast.Str):
tokens.append('STRING')
elif isinstance(node, ast.Num):
tokens.append('NUMBER')
# Add more node types as needed
return tokens
# Example usage
code = """
def greet(name):
print("Hello, " + name + "!")
"""
tokens = tokenize_code(code)
print(tokens)
# Output: ['def', 'greet', 'name', 'print', 'STRING', 'name', 'STRING']
Bu tokenleştirilmiş temsil daha sonra yerleştirme için bir sinir ağına beslenebilir.
Kod Yerleştirmeye İlişkin Mevcut Yaklaşımlar
Kod yerleştirmeye yönelik mevcut yöntemler üç ana kategoriye ayrılabilir:
Token Tabanlı Yöntemler
Belirteç tabanlı yöntemler, kodu bir dizi sözcüksel belirteç olarak ele alır. Terim Frekansı-Ters Belge Frekansı (TF-IDF) gibi teknikler ve derin öğrenme modelleri CodeBERT bu kategoriye girer.
Ağaç Tabanlı Yöntemler
Ağaç tabanlı yöntemler, kodu soyut sözdizimi ağaçlarına (AST'ler) veya diğer ağaç yapılarına ayrıştırarak kodun sözdizimsel ve anlamsal kurallarını yakalar. Örnekler arasında ağaç tabanlı sinir ağları ve aşağıdaki modeller yer alır: code2vec ve ASTNN.
Grafik Tabanlı Yöntemler
Grafik tabanlı yöntemler, kodun dinamik davranışını ve bağımlılıklarını temsil etmek için kontrol akış grafikleri (CFG'ler) ve veri akış grafikleri (DFG'ler) gibi koddan grafikler oluşturur. GrafikKoduBERT dikkate değer bir örnektir.
TransformCode: Kod Yerleştirmeye Yönelik Bir Çerçeve
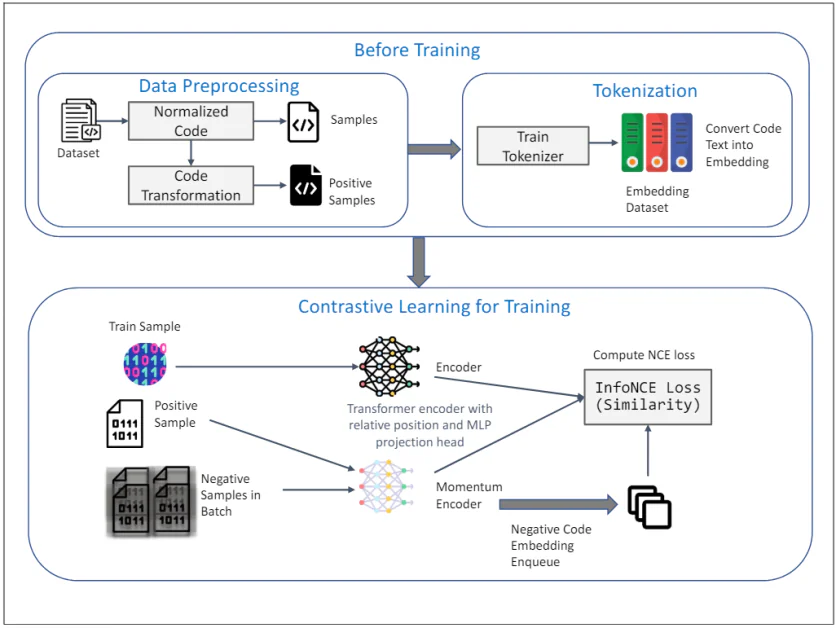
TransformCode: Kod yerleştirmenin denetimsiz öğrenimi
Dönüşüm Kodu kod yerleştirmelerini karşılaştırmalı bir öğrenme yöntemiyle öğrenerek mevcut yöntemlerin sınırlamalarını ele alan bir çerçevedir. Kodlayıcıdan ve dilden bağımsızdır; yani her kodlayıcı modelinden yararlanabilir ve her programlama dilini işleyebilir.
Yukarıdaki diyagram, karşılaştırmalı öğrenmeyi kullanarak kod yerleştirmenin denetimsiz öğrenimine yönelik TransformCode'un çerçevesini göstermektedir. İki ana aşamadan oluşur: Eğitimden Önce ve Eğitim için Karşılaştırmalı Öğrenmeİşte her bir bileşenin detaylı açıklaması:
Eğitimden Önce
1. Veri Ön İşleme:
- Veri kümesi: İlk girdi, kod parçacıklarını içeren bir veri kümesidir.
- Normalleştirilmiş Kod: Kod parçacıkları, yorumları kaldırmak ve değişkenleri standart bir biçimde yeniden adlandırmak için normalleştirmeye tabi tutulur. Bu, değişken adlandırmanın öğrenme süreci üzerindeki etkisini azaltmaya yardımcı olur ve modelin genelleştirilebilirliğini artırır.
- Kod Dönüşümü: Normalleştirilmiş kod daha sonra pozitif örnekler oluşturmak için çeşitli sözdizimsel ve anlamsal dönüşümler kullanılarak dönüştürülür. Bu dönüşümler, kodun anlamsal anlamının değişmeden kalmasını sağlayarak karşılaştırmalı öğrenme için çeşitli ve sağlam örnekler sağlar.
2. Simgeleştirme:
- Tren Tokenizer'ı: Kod metnini yerleştirmelere dönüştürmek için kod veri kümesi üzerinde bir tokenizer eğitilir. Bu, kodun model tarafından işlenebilecek jetonlar gibi daha küçük birimlere bölünmesini içerir.
- Veri Kümesini Gömme: Eğitilmiş tokenizer, tüm kod veri kümesini karşılaştırmalı öğrenme aşaması için girdi görevi gören yerleştirmelere dönüştürmek için kullanılır.
Eğitim için Karşılaştırmalı Öğrenme
3. Eğitim Süreci:
- Tren Örneği: Eğitim veri kümesinden bir örnek, sorgu kodu gösterimi olarak seçilir.
- Olumlu Örnek: Karşılık gelen pozitif örnek, veri ön işleme aşamasında elde edilen sorgu kodunun dönüştürülmüş versiyonudur.
- Toplu Negatif Örnekler: Negatif numuneler, mevcut mini serideki pozitif numuneden farklı olan diğer tüm kod numuneleridir.
4. Kodlayıcı ve Momentum Kodlayıcı:
- Göreceli Konum ve MLP Projeksiyon Kafasına Sahip Transformatör Kodlayıcı: Hem sorgu hem de pozitif örnekler bir Transformer kodlayıcıya beslenir. Kodlayıcı, sözdizimsel yapıyı ve koddaki simgeler arasındaki ilişkileri yakalamak için göreceli konum kodlamasını içerir. Kodlanmış gösterimleri, karşılaştırmalı öğrenme hedefinin uygulandığı daha düşük boyutlu bir alana eşlemek için bir MLP (Çok Katmanlı Algılayıcı) projeksiyon kafası kullanılır.
- Momentum Kodlayıcı: Sorgu kodlayıcısının parametrelerinin hareketli ortalaması ile güncellenen bir momentum kodlayıcı da kullanılır. Bu, temsillerin tutarlılığını ve çeşitliliğini koruyarak, karşılaştırma kaybının çökmesini önler. Negatif örnekler bu momentum kodlayıcı kullanılarak kodlanır ve karşılaştırma öğrenme süreci için sıraya alınır.
5. Karşılaştırmalı Öğrenme Hedefi:
- Compute InfoNCE Kaybı (Benzerlik): MKS InfoNCE (Gürültü Karşılaştırmalı Tahmini) kaybı sorgu ile pozitif örnekler arasındaki benzerliği en üst düzeye çıkarırken, sorgu ile negatif örnekler arasındaki benzerliği en aza indirecek şekilde hesaplanır. Bu amaç, öğrenilen yerleştirmelerin ayırt edici ve sağlam olmasını ve kod parçacıklarının anlamsal benzerliğini yakalamasını sağlar.
Çerçevenin tamamı, etiketlenmemiş verilerden anlamlı ve sağlam kod yerleştirmeleri öğrenmek için karşılaştırmalı öğrenmenin güçlü yönlerinden yararlanır. AST dönüşümlerinin ve momentum kodlayıcının kullanılması, öğrenilen gösterimlerin kalitesini ve verimliliğini daha da artırarak TransformCode'u çeşitli yazılım mühendisliği görevleri için güçlü bir araç haline getirir.
TransformCode'un Temel Özellikleri
- Esneklik ve uyarlanabilirlik: Kod gösterimi gerektiren çeşitli aşağı akış görevlerine genişletilebilir.
- Verimlilik ve Ölçeklenebilirlik: Herhangi bir programlama dilini destekleyen, büyük bir model veya kapsamlı eğitim verileri gerektirmez.
- Denetimsiz ve Denetimli Öğrenme: Göreve özgü etiketler veya hedefler dahil edilerek her iki öğrenme senaryosuna da uygulanabilir.
- Ayarlanabilir Parametreler: Kodlayıcı parametrelerinin sayısı mevcut bilgi işlem kaynaklarına göre ayarlanabilir.
TransformCode, orijinal kod parçacıklarına sözdizimsel ve anlamsal dönüşümler uygulayan, AST dönüşümü adı verilen bir veri artırma tekniği sunar. Bu, karşılaştırmalı öğrenme için çeşitli ve sağlam örnekler üretir.
Kod Gömme Uygulamaları
Kod yerleştirmeler, kodu metin biçiminden makine öğrenimi modelleri tarafından kullanılabilen sayısal bir gösterime dönüştürerek yazılım mühendisliğinin çeşitli yönlerinde devrim yarattı. İşte bazı önemli uygulamalar:
Geliştirilmiş Kod Arama
Geleneksel olarak kod arama, anahtar kelime eşleştirmeye dayanıyordu ve bu da çoğu zaman alakasız sonuçlara yol açıyordu. Kod yerleştirmeler, farklı anahtar kelimeler kullansalar bile kod parçacıklarının işlevsellikteki benzerliklerine göre sıralandığı anlamsal aramayı etkinleştirir. Bu, büyük kod tabanlarında ilgili kodu bulmanın doğruluğunu ve verimliliğini önemli ölçüde artırır.
Daha Akıllı Kod Tamamlama
Kod tamamlama araçları, mevcut bağlama göre ilgili kod parçacıkları önerir. Kod yerleştirmelerden yararlanan bu araçlar, yazılan kodun anlamsal anlamını anlayarak daha doğru ve yararlı öneriler sağlayabilir. Bu, daha hızlı ve daha verimli kodlama deneyimleri anlamına gelir.
Otomatik Kod Düzeltme ve Hata Tespiti
Kod yerleştirmeleri, genellikle koddaki hataları veya verimsizlikleri gösteren kalıpları tanımlamak için kullanılabilir. Bu sistemler, kod parçacıkları ile bilinen hata modelleri arasındaki benzerliği analiz ederek otomatik olarak düzeltmeler önerebilir veya daha fazla inceleme gerektirebilecek alanları vurgulayabilir.
Gelişmiş Kod Özetleme ve Dokümantasyon Oluşturma
Büyük kod tabanları genellikle uygun belgelerden yoksundur ve bu da yeni geliştiricilerin bunların işleyişini anlamasını zorlaştırır. Kod yerleştirmeleri, kodun işlevselliğinin özünü yakalayan kısa özetler oluşturabilir. Bu yalnızca kodun sürdürülebilirliğini artırmakla kalmaz, aynı zamanda geliştirme ekipleri içinde bilgi aktarımını da kolaylaştırır.
Geliştirilmiş Kod İncelemeleri
Kod incelemeleri, kod kalitesini korumak için çok önemlidir. Kod yerleştirmeler, potansiyel sorunları vurgulayarak ve iyileştirmeler önererek incelemecilere yardımcı olabilir. Ek olarak, farklı kod sürümleri arasındaki karşılaştırmaları kolaylaştırarak inceleme sürecini daha verimli hale getirebilirler.
Diller Arası Kod İşleme
Yazılım geliştirme dünyası tek bir programlama diliyle sınırlı değildir. Kod yerleştirmeler, diller arası kod işleme görevlerini kolaylaştırmak için umut vaat ediyor. Farklı dillerde yazılan kodlar arasındaki anlamsal ilişkileri yakalayan bu teknikler, programlama dilleri arasında kod arama ve analiz gibi görevleri mümkün kılabilir.












