Bäst Av
10 bästa maskininlärningsalgoritmer
Även om vi lever genom en tid av extraordinär innovation inom GPU-accelererad maskininlärning, innehåller de senaste forskningsartiklarna ofta (och framträdande) algoritmer som är decennier, i vissa fall 70 år gamla.
Vissa kanske hävdar att många av dessa äldre metoder faller i lägret för "statistisk analys" snarare än maskininlärning, och föredrar att datera tillkomsten av sektorn så långt tillbaka som 1957, med uppfinning av Perceptron.
Med tanke på i vilken utsträckning dessa äldre algoritmer stödjer och är inblandade i de senaste trenderna och rubrikerna inom maskininlärning, är det en omtvistad hållning. Så låt oss ta en titt på några av de "klassiska" byggstenarna som ligger till grund för de senaste innovationerna, såväl som några nyare bidrag som lägger ett tidigt bud på AI Hall of Fame.
1: Transformatorer
2017 ledde Google Research ett forskningssamarbete som kulminerade i papper Uppmärksamhet är allt du behöver. Verket skisserade en ny arkitektur som främjade uppmärksamhetsmekanismer från "piping" i kodare/avkodare och återkommande nätverksmodeller till en central transformationsteknik i sin egen rätt.
Tillvägagångssättet dubbades Transformator, och har sedan dess blivit en revolutionerande metod inom Natural Language Processing (NLP), som driver, bland många andra exempel, den autoregressiva språkmodellen och AI-poster-barn GPT-3.
![]()
Transformatorer löste elegant problemet med sekvenstransduktion, även kallad 'transformation', som är upptagen med bearbetning av ingångssekvenser till utdatasekvenser. En transformator tar också emot och hanterar data på ett kontinuerligt sätt, snarare än i sekventiella batcher, vilket tillåter en "beständighet av minne" som RNN-arkitekturer inte är designade för att erhålla. För en mer detaljerad översikt av transformatorer, ta en titt på vår referensartikel.
I motsats till de återkommande neurala nätverken (RNN) som hade börjat dominera ML-forskningen under CUDA-eran, kunde transformatorarkitektur också vara lätt parallelliserad, vilket öppnar vägen för att produktivt adressera en mycket större mängd data än RNN.
Populär användning
Transformers fångade allmänhetens fantasi 2020 med lanseringen av OpenAI:s GPT-3, som stoltserade med ett då rekord 175 miljarder parametrar. Denna uppenbarligen häpnadsväckande prestation överskuggades så småningom av senare projekt, såsom 2021 frigöra av Microsofts Megatron-Turing NLG 530B, som (som namnet antyder) har över 530 miljarder parametrar.

En tidslinje av hyperscale Transformer NLP-projekt. Källa: Microsoft
Transformatorarkitektur har också gått över från NLP till datorseende, vilket driver en ny generation av ramverk för bildsyntes som OpenAI:s KLÄMMA och DALL-E, som använder text>image domänmappning för att avsluta ofullständiga bilder och syntetisera nya bilder från utbildade domäner, bland ett växande antal relaterade applikationer.

DALL-E försöker färdigställa en delbild av en byst av Platon. Källa: https://openai.com/blog/dall-e/
2: Generative Adversarial Networks (GAN)
Även om transformatorer har fått extraordinär mediebevakning genom lanseringen och adoptionen av GPT-3 Generativt Adversarial Network (GAN) har blivit ett igenkännligt varumärke i sin egen rätt och kan så småningom gå med deepfake som ett verb.
Föreslog först i 2014 och används främst för bildsyntes, ett Generative Adversarial Network arkitektur består av en Generator och en Diskriminator. Generatorn cyklar genom tusentals bilder i en datauppsättning och försöker iterativt att rekonstruera dem. För varje försök betygsätter Diskriminatorn Generatorns arbete och skickar Generatorn tillbaka för att göra det bättre, men utan någon insikt i hur den tidigare rekonstruktionen gjorde fel.

Källa: https://developers.google.com/machine-learning/gan/gan_structure
Detta tvingar Generatorn att utforska en mångfald av vägar, istället för att följa de potentiella återvändsgränderna som skulle ha uppstått om Diskriminatorn hade berättat var det gick fel (se #8 nedan). När träningen är över har Generatorn en detaljerad och heltäckande karta över relationer mellan punkter i datamängden.

Från tidningen Förbättra GAN-jämvikten genom att höja rumslig medvetenhet: ett nytt ramverk cirkulerar genom det ibland mystiska latenta utrymmet i ett GAN, vilket ger responsiv instrumentalitet för en bildsyntesarkitektur. Källa: https://genforce.github.io/eqgan/
I analogi är detta skillnaden mellan att lära sig en enkel pendling till centrala London, eller att noggrant skaffa Kunskapen.
Resultatet är en samling funktioner på hög nivå i den tränade modellens latenta utrymme. Den semantiska indikatorn för en funktion på hög nivå kan vara "person", medan en nedstigning genom specificitet relaterad till egenskapen kan avslöja andra inlärda egenskaper, såsom "man" och "kvinna". På lägre nivåer kan underfunktionerna bryta ner till 'blond', 'kaukasisk', et al.
Förveckling är en anmärkningsvärd fråga i det latenta utrymmet av GAN:er och kodar-/avkodarramverk: är leendet på ett GAN-genererat kvinnligt ansikte ett intrasslat inslag i hennes 'identitet' i det latenta utrymmet, eller är det en parallell gren?

GAN-genererade ansikten från denna person existerar inte. Källa: https://this-person-does-not-exist.com/en
De senaste åren har fört fram ett växande antal nya forskningsinitiativ i detta avseende, vilket kanske banat väg för redigering i Photoshop-stil på funktionsnivå för det latenta utrymmet i en GAN, men för närvarande är många transformationer effektivt ' allt eller inget-paket. Noterbart är att NVIDIAs EditGAN-utgåva i slutet av 2021 uppnår en hög grad av tolkningsbarhet i det latenta utrymmet genom att använda semantiska segmenteringsmasker.
Populär användning
Förutom deras (faktiskt ganska begränsade) engagemang i populära deepfake-videor, har bild-/videocentrerade GAN:er ökat under de senaste fyra åren, och fängslat både forskare och allmänheten. Att hålla jämna steg med den svindlande takten och frekvensen av nya utgåvor är en utmaning, även om GitHub-förvaret Fantastiska GAN-applikationer syftar till att ge en heltäckande lista.
Generativa kontradiktoriska nätverk kan i teorin härleda egenskaper från vilken väl inramad domän som helst, inklusive text.
3: SVM
ursprung i 1963, Stöd Vector Machine (SVM) är en kärnalgoritm som dyker upp ofta i ny forskning. Under SVM kartlägger vektorer den relativa dispositionen av datapunkter i en datamängd, medan stödja vektorer avgränsar gränserna mellan olika grupper, egenskaper eller egenskaper.
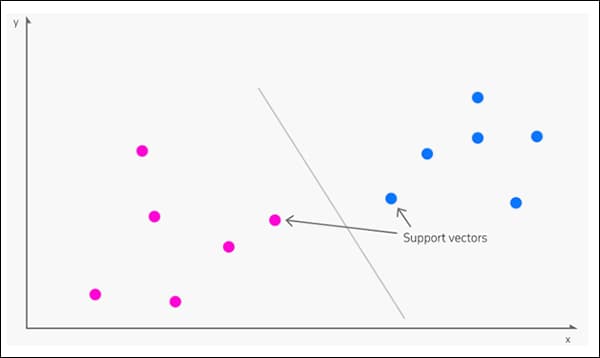
Stödvektorer definierar gränserna mellan grupper. Källa: https://www.kdnuggets.com/2016/07/support-vector-machines-simple-explanation.html
Den härledda gränsen kallas a hyperplan.
På låga funktionsnivåer är SVM tvådimensionell (bilden ovan), men där det finns ett högre antal grupper eller typer, blir det tredimensionella.

En djupare samling av punkter och grupper kräver en tredimensionell SVM. Källa: https://cml.rhul.ac.uk/svm.html
Populär användning
Eftersom support Vector Machines effektivt och agnostiskt kan adressera högdimensionell data av många slag, dyker de upp brett inom en mängd olika maskininlärningssektorer, inklusive deepfake-detektering, bildklassificering, klassificering av hatretorik, DNA-analys och förutsägelse av befolkningsstruktur, bland många andra.
4: K-Means Clustering
Clustering i allmänhet är en oövervakat lärande tillvägagångssätt som försöker kategorisera datapunkter genom densitetsuppskattning, skapa en karta över fördelningen av data som studeras.

K-Betyder att gruppera gudomliga segment, grupper och gemenskaper i data. Källa: https://aws.amazon.com/blogs/machine-learning/k-means-clustering-with-amazon-sagemaker/
K-Means Clustering har blivit den mest populära implementeringen av det här tillvägagångssättet, och att samla data pekar in i distinkta "K-grupper", som kan indikera demografiska sektorer, online-gemenskaper eller någon annan möjlig hemlig aggregering som väntar på att upptäckas i rå statistisk data.

Kluster bildas i K-Means-analys. Källa: https://www.geeksforgeeks.org/ml-determine-the-optimal-value-of-k-in-k-means-clustering/
K-värdet i sig är den avgörande faktorn för processens användbarhet och för att fastställa ett optimalt värde för ett kluster. Inledningsvis tilldelas K-värdet slumpmässigt och dess egenskaper och vektoregenskaper jämfört med dess grannar. De grannar som mest liknar datapunkten med det slumpmässigt tilldelade värdet tilldelas dess kluster iterativt tills data har gett alla grupperingar som processen tillåter.
Plottet för det kvadratiska felet, eller 'kostnaden' för olika värden bland klustren kommer att avslöja en armbågsspets för data:

'Armbågspunkten' i en klustergraf. Källa: https://www.scikit-yb.org/en/latest/api/cluster/elbow.html
Armbågspunkten liknar konceptet hur förlusten planar ut till minskande avkastning i slutet av ett träningspass för en datauppsättning. Det representerar den punkt då inga ytterligare skillnader mellan grupper kommer att bli uppenbara, vilket indikerar tidpunkten för att gå vidare till efterföljande faser i datapipelinen, eller annars för att rapportera fynd.
Populär användning
K-Means Clustering är av uppenbara skäl en primär teknik inom kundanalys, eftersom den erbjuder en tydlig och förklarlig metod för att översätta stora mängder kommersiella poster till demografiska insikter och "leads".
Utanför denna applikation används även K-Means Clustering för jordskred förutsägelse, medicinsk bildsegmentering, bildsyntes med GAN, dokumentklassificeringoch stadsplanering, bland många andra potentiella och faktiska användningsområden.
5: Random Forest
Random Forest är en ensembleinlärning metod som ger ett genomsnitt av resultatet från en array av beslutsträd att upprätta en övergripande förutsägelse för resultatet.

Källa: https://www.tutorialandexample.com/wp-content/uploads/2019/10/Decision-Trees-Root-Node.png
Om du har undersökt det så lite som att titta på Tillbaka till framtiden trilogin är ett beslutsträd i sig ganska lätt att konceptualisera: ett antal vägar ligger framför dig, och varje väg förgrenar sig till ett nytt resultat som i sin tur innehåller ytterligare möjliga vägar.
In förstärkning lärande, kan du dra dig tillbaka från en stig och börja om från en tidigare hållning, medan beslutsträd förbinder sig till sina resor.
Således är Random Forest-algoritmen i huvudsak spread-betting för beslut. Algoritmen kallas 'slumpmässig' eftersom den gör ad hoc urval och observationer för att förstå median summan av resultaten från beslutsträdsmatrisen.
Eftersom det tar hänsyn till en mångfald faktorer kan en Random Forest-metod vara svårare att omvandla till meningsfulla grafer än ett beslutsträd, men kommer sannolikt att vara betydligt mer produktivt.
Beslutsträd är föremål för överanpassning, där de erhållna resultaten är dataspecifika och sannolikt inte generaliserar. Random Forests godtyckliga urval av datapunkter bekämpar denna tendens, och går igenom till meningsfulla och användbara representativa trender i data.

Regression av beslutsträd. Källa: https://scikit-learn.org/stable/auto_examples/tree/plot_tree_regression.html
Populär användning
Som med många av algoritmerna i den här listan, fungerar Random Forest vanligtvis som en "tidig" sorterare och filter av data, och som sådan dyker det konsekvent upp i nya forskningsartiklar. Några exempel på Random Forest-användning inkluderar Magnetisk resonansbildsyntes, Bitcoin prisprognos, folkräkningssegmentering, textklassificering och upptäckt av kreditkortsbedrägerier.
Eftersom Random Forest är en lågnivåalgoritm i maskininlärningsarkitekturer kan den även bidra till prestanda för andra lågnivåmetoder, samt visualiseringsalgoritmer, bl.a. Induktiv klustring, Funktionstransformationer, klassificering av textdokument använder glesa funktioneroch visar pipelines.
6: Naiv Bayes
Tillsammans med densitetsuppskattning (se 4, ovan), a naiva Bayes klassificerare är en kraftfull men relativt lätt algoritm som kan uppskatta sannolikheter baserat på de beräknade egenskaperna hos data.

Visa relationer i en naiv Bayes-klassificerare. Källa: https://www.sciencedirect.com/topics/computer-science/naive-bayes-model
Termen "naiv" syftar på antagandet i Bayes sats att funktioner inte är relaterade, känd som villkorligt oberoende. Om du intar denna ståndpunkt räcker det inte att gå och prata som en anka för att fastställa att vi har att göra med en anka, och inga "uppenbara" antaganden antas i förtid.
Denna nivå av akademisk och undersökande rigor skulle vara överdriven där "sunt förnuft" är tillgängligt, men är en värdefull standard när man korsar de många oklarheter och potentiellt orelaterade korrelationer som kan finnas i en datauppsättning för maskininlärning.
I ett original bayesiskt nätverk är funktioner föremål för poängfunktioner, inklusive minimal beskrivningslängd och Bayesiansk poäng, vilket kan införa begränsningar för data när det gäller de uppskattade kopplingarna som hittas mellan datapunkterna och i vilken riktning dessa förbindelser flyter.
En naiv Bayes-klassificerare, omvänt, fungerar genom att anta att egenskaperna hos ett givet objekt är oberoende, och sedan använder Bayes' teorem för att beräkna sannolikheten för ett givet objekt, baserat på dess egenskaper.
Populär användning
Naiva Bayes-filter är väl representerade i sjukdomsförutsägelse och dokumentkategorisering, skräppostfiltrering, sentimentklassificering, rekommendatorsystemoch spårning av bedrägerierbland andra applikationer.
7: K- Nearest Neighbors (KNN)
Först föreslogs av US Air Force School of Aviation Medicine i 1951, och måste anpassa sig till det senaste inom datorhårdvara från mitten av 20-talet, K-närmaste grannar (KNN) är en slank algoritm som fortfarande har en framträdande plats i akademiska artiklar och forskningsinitiativ för maskininlärning inom den privata sektorn.
KNN har kallats "den lata inläraren", eftersom den uttömmande skannar en datauppsättning för att utvärdera relationerna mellan datapunkter, snarare än att kräva utbildning av en fullfjädrad maskininlärningsmodell.

En KNN-gruppering. Källa: https://scikit-learn.org/stable/modules/neighbors.html
Även om KNN är arkitektoniskt smal, ställer dess systematiska tillvägagångssätt ett anmärkningsvärt krav på läs-/skrivoperationer, och dess användning i mycket stora datamängder kan vara problematisk utan tilläggsteknologier som Principal Component Analysis (PCA), som kan transformera komplexa och stora datamängder. in i representativa grupperingar att KNN kan korsa med mindre ansträngning.
A färsk studie utvärderade effektiviteten och ekonomin hos ett antal algoritmer med uppgift att förutsäga om en anställd kommer att lämna ett företag, och fann att den sjuåriga KNN förblev överlägsen mer moderna utmanare när det gäller noggrannhet och prediktiv effektivitet.
Populär användning
Trots all sin populära enkelhet i koncept och utförande har KNN inte fastnat på 1950-talet – det har anpassats till ett mer DNN-fokuserat tillvägagångssätt i ett förslag från 2018 från Pennsylvania State University, och förblir en central process i tidigt skede (eller analytiskt verktyg efter bearbetning) i många mycket mer komplexa ramverk för maskininlärning.
I olika konfigurationer har KNN använts eller för signaturverifiering online, bildklassificering, textbrytning, förutsägelse av skördoch ansiktsigenkänning, förutom andra tillämpningar och införlivningar.

Ett KNN-baserat ansiktsigenkänningssystem under träning. Source: https://pdfs.semanticscholar.org/6f3d/d4c5ffeb3ce74bf57342861686944490f513.pdf
8: Markov Decision Process (MDP)
Ett matematiskt ramverk introducerat av den amerikanske matematikern Richard Bellman i 1957, Markov Decision Process (MDP) är en av de mest grundläggande blocken av förstärkning lärande arkitekturer. En konceptuell algoritm i sin egen rätt, den har anpassats till ett stort antal andra algoritmer och återkommer ofta i den nuvarande skörden av AI/ML-forskning.
MDP utforskar en datamiljö genom att använda dess utvärdering av dess nuvarande tillstånd (dvs. "var" den är i data) för att bestämma vilken nod av data som ska utforskas härnäst.

Källa: https://www.sciencedirect.com/science/article/abs/pii/S0888613X18304420
En grundläggande Markov-beslutsprocess kommer att prioritera kortsiktiga fördelar framför mer önskvärda långsiktiga mål. Av denna anledning är det vanligtvis inbäddat i en mer omfattande policyarkitektur inom förstärkt lärande, och är ofta föremål för begränsande faktorer som rabatterad belöning och andra modifierande miljövariabler som kommer att hindra den från att skynda till ett omedelbart mål utan hänsyn. av det bredare önskade resultatet.
Populär användning
MDP:s lågnivåkoncept är utbrett inom både forskning och aktiva implementeringar av maskininlärning. Det har föreslagits för IoT säkerhetsförsvarssystem, skörd av fiskoch marknadsprognoser.
Förutom dess uppenbar tillämplighet till schack och andra strikt sekventiella spel är MDP också en naturlig utmanare för procedurutbildning av robotsystem, som vi kan se i videon nedan.

9: Term Frequency-Invers Document Frequency
Term Frequency (TF) dividerar antalet gånger ett ord förekommer i ett dokument med det totala antalet ord i det dokumentet. Alltså ordet försegla som förekommer en gång i en tusenordsartikel har en termfrekvens på 0.001. I och för sig är TF i stort sett värdelös som en indikator på termens betydelse, på grund av att meningslösa artiklar (t.ex. a, och, doch it) dominerar.
För att få ett meningsfullt värde för en term, beräknar Inverse Document Frequency (IDF) TF för ett ord över flera dokument i en datamängd, vilket ger lågt betyg till mycket hög frekvens stoppord, såsom artiklar. De resulterande egenskapsvektorerna normaliseras till hela värden, med varje ord tilldelad en lämplig vikt.

TF-IDF väger relevansen av termer baserat på frekvens i ett antal dokument, med sällsynta förekomst en indikator på framträdande. Källa: https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Även om detta tillvägagångssätt förhindrar semantiskt viktiga ord från att gå förlorade outliers, invertering av frekvensvikten betyder inte automatiskt att en lågfrekvent term är det inte en outlier, eftersom vissa saker är sällsynta och värdelös. Därför kommer en lågfrekvent term att behöva bevisa sitt värde i det bredare arkitektoniska sammanhanget genom att presentera (även med en låg frekvens per dokument) i ett antal dokument i datamängden.
Trots det ålder, TF-IDF är en kraftfull och populär metod för initiala filtreringspass i Natural Language Processing-ramverk.
Populär användning
Eftersom TF-IDF har spelat åtminstone en viss roll i utvecklingen av Googles till stor del ockulta PageRank-algoritm under de senaste tjugo åren, har det blivit mycket allmänt antagen som en manipulativ SEO-taktik, trots John Muellers 2019 förnekande om dess betydelse för sökresultaten.
På grund av sekretessen kring PageRank finns det inga tydliga bevis för att TF-IDF är det inte för närvarande en effektiv taktik för att ta sig upp i Googles ranking. Upphetsande diskussion bland IT-proffs på senare tid indikerar en populär förståelse, korrekt eller inte, att termmissbruk fortfarande kan resultera i förbättrad SEO-placering (även om ytterligare anklagelser om monopolmissbruk och överdriven reklam sudda ut gränserna för denna teori).
10: Stokastisk Gradient Descent
Stokastisk Gradient Descent (SGD) är en alltmer populär metod för att optimera utbildningen av maskininlärningsmodeller.
Gradient Descent i sig är en metod för att optimera och därefter kvantifiera den förbättring som en modell gör under träning.
I denna mening indikerar 'gradient' en lutning nedåt (snarare än en färgbaserad gradering, se bilden nedan), där den högsta punkten på 'kullen', till vänster, representerar början av träningsprocessen. I detta skede har modellen ännu inte sett hela datan en enda gång, och har inte lärt sig tillräckligt om relationer mellan data för att producera effektiva transformationer.

En lutning nedstigning på ett FaceSwap-träningspass. Vi kan se att träningen har platåerat ett tag i andra halvlek, men har så småningom återhämtat sig nerför lutning mot en acceptabel konvergens.
Den lägsta punkten, till höger, representerar konvergens (den punkt där modellen är lika effektiv som den någonsin kommer att hamna under de pålagda begränsningarna och inställningarna).
Gradienten fungerar som en post och prediktor för skillnaden mellan felfrekvensen (hur exakt modellen för närvarande har kartlagt datarelationerna) och vikterna (inställningarna som påverkar hur modellen kommer att lära sig).
Denna registrering av framsteg kan användas för att informera en schema för inlärningstakt, en automatisk process som säger åt arkitekturen att bli mer detaljerad och exakt när de tidiga vaga detaljerna förvandlas till tydliga relationer och kartläggningar. I själva verket ger gradientförlust en just-in-time-karta över vart träningen ska gå härnäst och hur den ska fortsätta.
Innovationen med Stochastic Gradient Descent är att den uppdaterar modellens parametrar på varje träningsexempel per iteration, vilket generellt sett snabbar på resan mot konvergens. På grund av tillkomsten av hyperskaliga datauppsättningar de senaste åren har SGD vuxit i popularitet på sistone som en möjlig metod för att ta itu med de efterföljande logistikproblemen.
Å andra sidan har SGD negativa konsekvenser för funktionsskalning, och kan kräva fler iterationer för att uppnå samma resultat, vilket kräver ytterligare planering och ytterligare parametrar, jämfört med vanlig Gradient Descent.
Populär användning
På grund av dess konfigurerbarhet, och trots dess brister, har SGD blivit den mest populära optimeringsalgoritmen för att passa neurala nätverk. En konfiguration av SGD som blir dominerande i nya AI/ML-forskningsartiklar är valet av Adaptive Moment Estimation (ADAM, introducerad i 2015) optimerare.
ADAM anpassar inlärningshastigheten för varje parameter dynamiskt ('adaptiv inlärningshastighet'), samt införlivar resultat från tidigare uppdateringar i den efterföljande konfigurationen ('momentum'). Dessutom kan den konfigureras för att använda senare innovationer, som t.ex Nesterov Momentum.
Vissa hävdar dock att användningen av momentum också kan påskynda ADAM (och liknande algoritmer) till en suboptimal slutsats. Som med det mesta av spetsen inom maskininlärningsforskningssektorn är SGD ett pågående arbete.
Första gången publicerad 10 februari 2022. Ändrad 10 februari 20.05 EET – formatering.












