
Artificiell intelligens
AI-assisterad objektredigering med Googles Imagic och Runways "Radera och ersätt"

Den här veckan erbjuder två nya, men kontrasterande AI-drivna grafikalgoritmer nya sätt för slutanvändare att göra mycket detaljerade och effektiva ändringar av objekt i foton.
Den första är Magiskt, från Google Research, i samarbete med Israels Institute of Technology och Weizmann Institute of Science. Imagic erbjuder textkonditionerad, finkornig redigering av objekt via finjustering av diffusionsmodeller.

Ändra vad du gillar och lämna resten – Imagic lovar detaljerad redigering av endast de delar som du vill ska ändras. Källa: https://arxiv.org/pdf/2210.09276.pdf
Alla som någonsin har försökt ändra bara ett element i en stabil spridningsåtergivning vet bara alltför väl att för varje lyckad redigering kommer systemet att ändra fem saker som du gillade precis som de var. Det är en brist som för närvarande har många av de mest begåvade SD-entusiasterna som ständigt blandas mellan Stable Diffusion och Photoshop, för att fixa den här typen av "collateral damage". Bara ur denna synvinkel verkar Imagics prestationer anmärkningsvärda.
I skrivande stund saknar Imagic ännu en reklamvideo, och med tanke på Googles försiktig attityd för att släppa obundna verktyg för bildsyntes är det osäkert i vilken utsträckning, om någon, vi kommer att få en chans att testa systemet.
Det andra erbjudandet är Runway ML:s mer lättillgängliga Radera och ersätt anläggning, en ny funktion i avsnittet "AI Magic Tools" i dess exklusivt online-svit med maskininlärningsbaserade verktyg för visuella effekter.
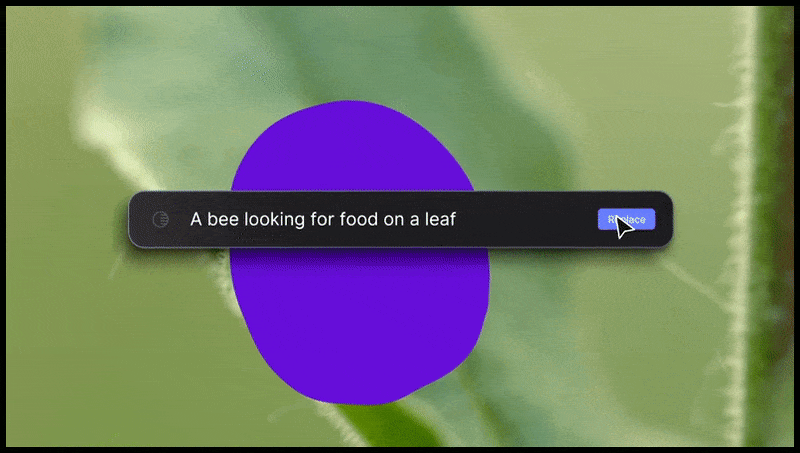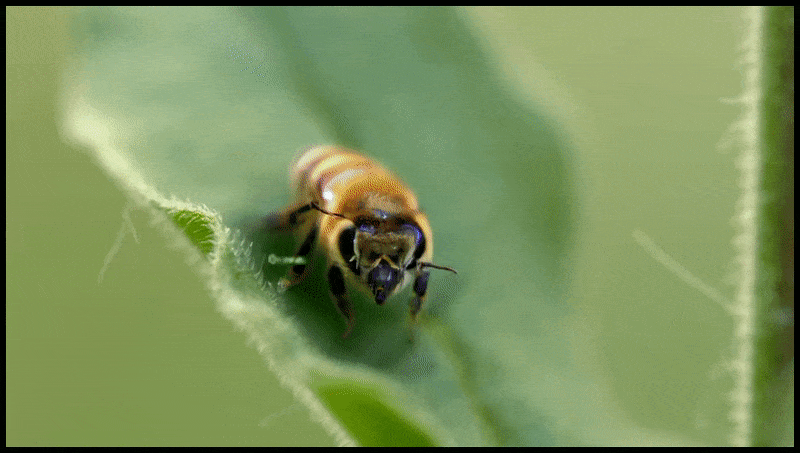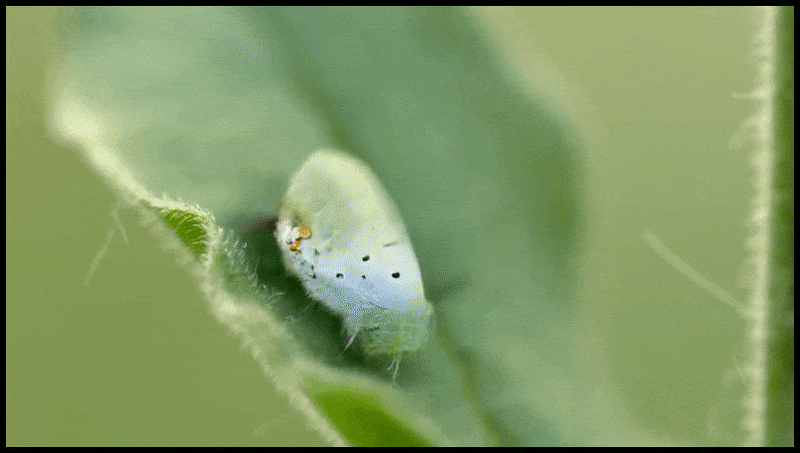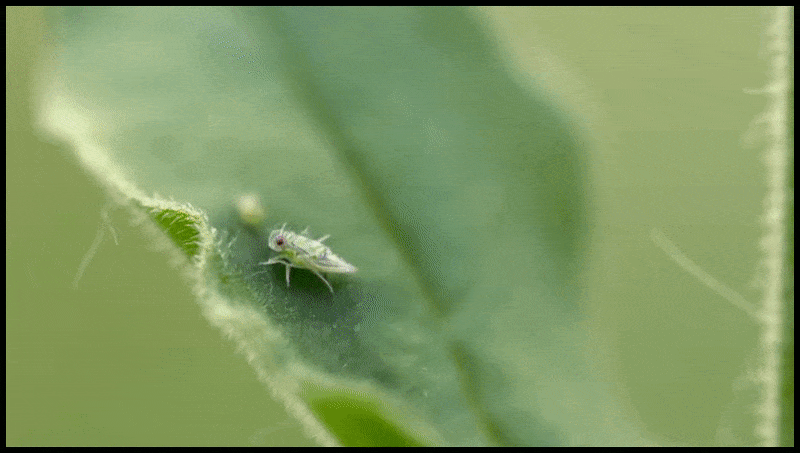
Runway ML:s radera och ersätt-funktion, redan sett i en förhandsvisning för ett text-till-video-redigeringssystem. Källa: https://www.youtube.com/watch?v=41Qb58ZPO60
Låt oss ta en titt på Runways utflykt först.
Radera och ersätt
Precis som Imagic handlar Erase and Replace uteslutande om stillbilder, även om Runway har gjort det förhandsvisas samma funktionalitet i en text-till-video-redigeringslösning som ännu inte har släppts:

Även om vem som helst kan testa den nya Radera och Ersätt på bilder, är videoversionen ännu inte tillgänglig för allmänheten. Källa: https://twitter.com/runwayml/status/1568220303808991232
Även om Runway ML inte har släppt detaljer om tekniken bakom Erase and Replace, tyder hastigheten med vilken du kan ersätta en krukväxt med en någorlunda övertygande byst av Ronald Reagan att en diffusionsmodell som Stable Diffusion (eller, mycket mindre troligt, en licensierad DALL-E 2) är motorn som återuppfinner ditt val i Radera och ersätt.

Att ersätta en krukväxt med en byst av The Gipper går inte riktigt så snabbt som det här, men det går ganska snabbt. Källa: https://app.runwayml.com/
Systemet har vissa begränsningar av DALL-E 2-typ – bilder eller text som flaggar för radera och ersätt-filtren kommer att utlösa en varning om eventuell kontoavstängning i händelse av ytterligare överträdelser – praktiskt taget en konstruktionsklon av OpenAI:s pågående Strategier för DALL-E 2 .
Många av resultaten saknar de typiska grova kanterna för stabil diffusion. Runway ML är investerare och forskningspartner i SD, och det är möjligt att de har tränat en egen modell som är överlägsen den öppen källkod 1.4 checkpoint-vikter som vi andra för närvarande brottas med (eftersom många andra utvecklingsgrupper, både amatörer och professionella, för närvarande tränar eller finjusterar Stabila diffusionsmodeller).
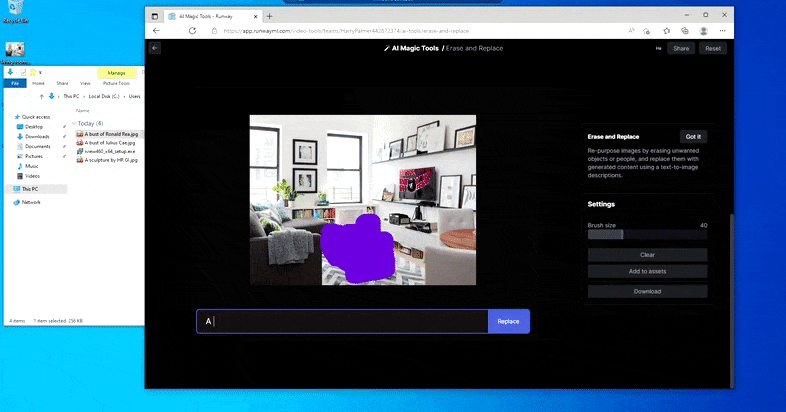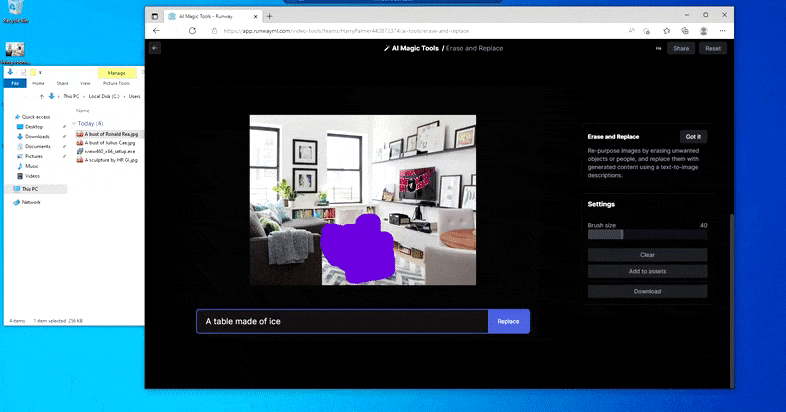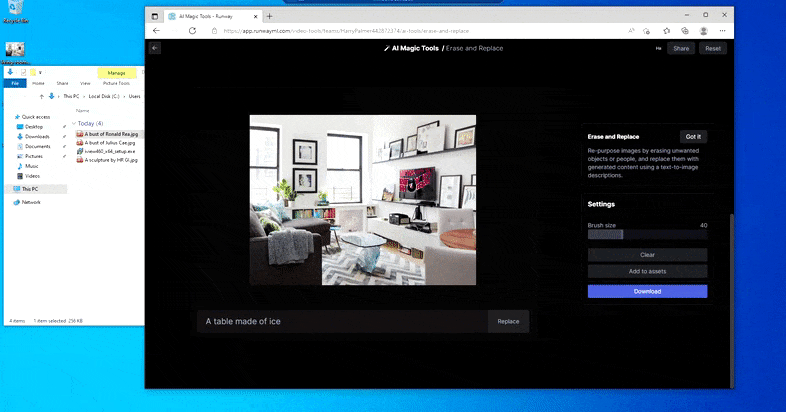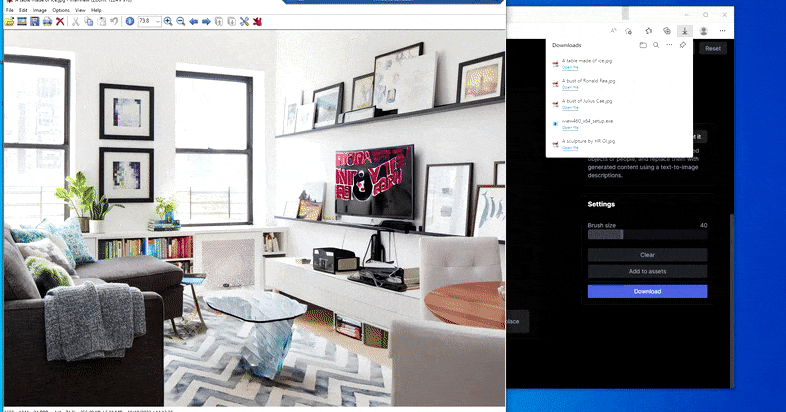
Ersätter ett inhemskt bord med ett "bord gjort av is" i Runway ML:s Erase and Replace.
Som med Imagic (se nedan), är Erase and Replace så att säga "objektorienterat" - du kan inte bara radera en "tom" del av bilden och måla in den med resultatet av din textuppmaning; i det scenariot kommer systemet helt enkelt att spåra det närmaste synliga föremålet längs maskens siktlinje (som en vägg eller en TV) och tillämpa transformationen där.
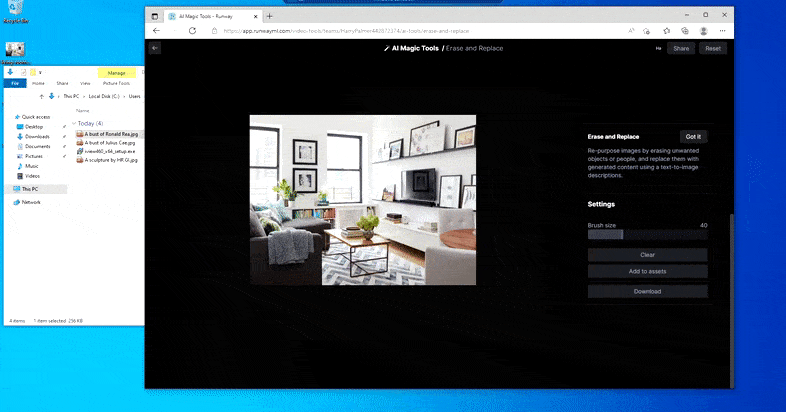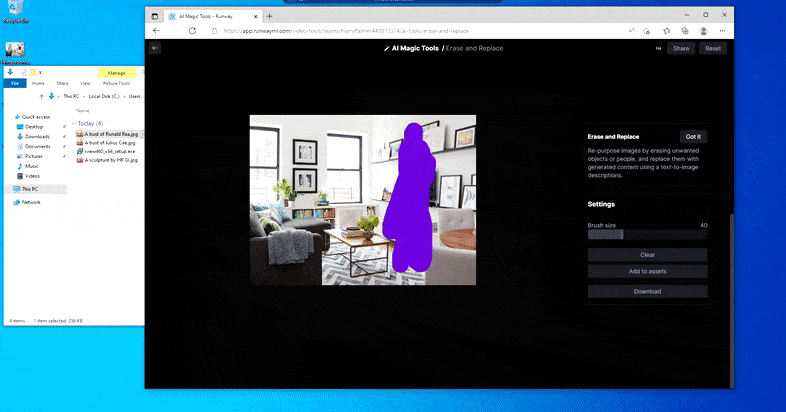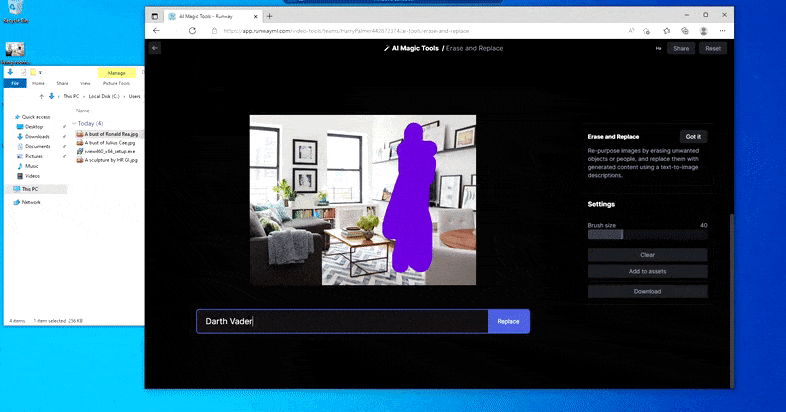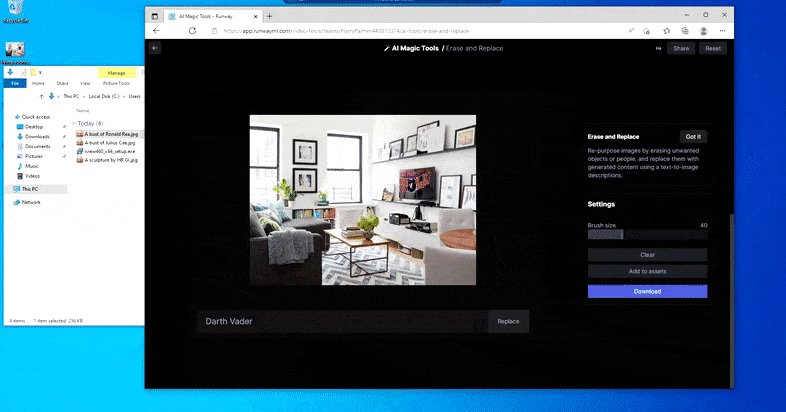
Som namnet antyder kan du inte injicera objekt i ett tomt utrymme i Radera och ersätt. Här resulterar ett försök att sammankalla de mest kända av Sith-herrarna i en konstig Vader-relaterad väggmålning på TV:n, ungefär där "ersätt"-området ritades.
Det är svårt att säga om Erase and Replace är undvikande när det gäller användningen av upphovsrättsskyddade bilder (som fortfarande till stor del är blockerade, om än med varierande framgång, i DALL-E 2), eller om modellen som används i backend-renderingsmotorn är helt enkelt inte optimerad för sånt.

Den något NSFW "Mural of Nicole Kidman" indikerar att den (förmodligen) spridningsbaserade modellen som finns till hands saknar DALL-E 2:s tidigare systematiska avvisande av att återge realistiska ansikten eller rasistiskt innehåll, medan resultaten för försök att bevisa upphovsrättsskyddade verk sträcker sig från det tvetydiga ('xenomorph') till det absurda ('järntronen'). Infälld längst ner till höger, källbilden.
Det skulle vara intressant att veta vilka metoder Erase and Replace använder för att isolera de objekt som den kan ersätta. Förmodligen körs bilden genom någon härledning av KLÄMMA, med de diskreta objekten individuella genom objektigenkänning och efterföljande semantisk segmentering. Ingen av dessa operationer fungerar i närheten av lika bra i en gemensam-eller-trädgårdsinstallation av Stable Diffusion.
Men ingenting är perfekt – ibland verkar systemet radera och inte ersätta, även när (som vi har sett i bilden ovan), den underliggande renderingsmekanismen definitivt vet vad en textuppmaning betyder. I det här fallet visar det sig omöjligt att förvandla ett soffbord till en xenomorf – snarare försvinner bordet bara.
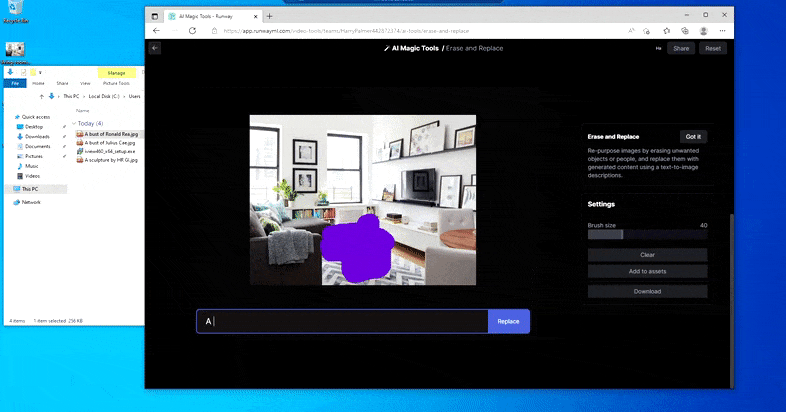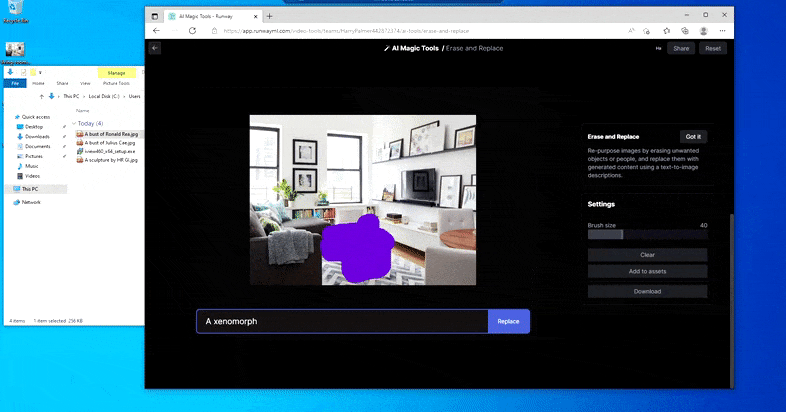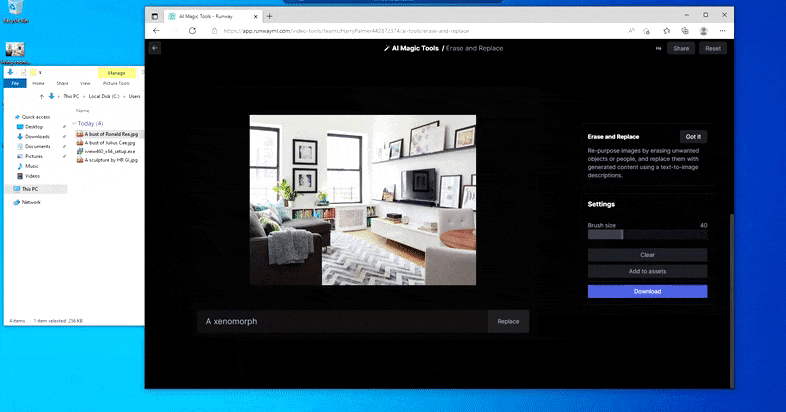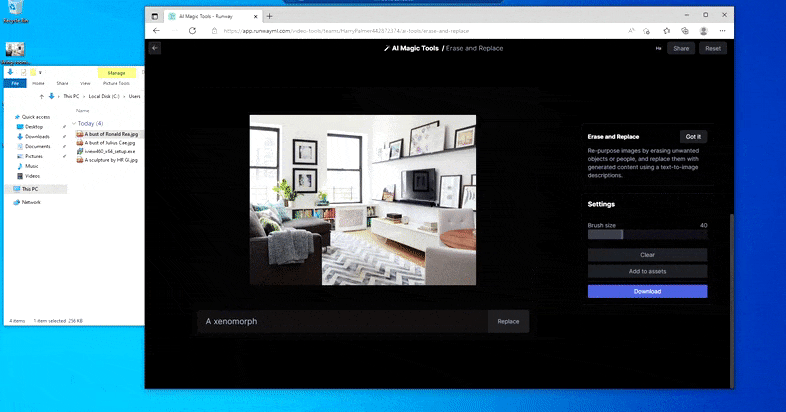
En mer läskig upprepning av "Where's Waldo", eftersom Erase and Replace misslyckas med att producera en utomjording.
Erase and Replace verkar vara ett effektivt objektersättningssystem, med utmärkt inmålning. Den kan dock inte redigera befintliga uppfattade objekt, utan bara ersätta dem. Att faktiskt ändra befintligt bildinnehåll utan att kompromissa med omgivande material är utan tvekan en mycket svårare uppgift, kopplat till datorseendeforskningssektorns långa kamp mot lösgöring i de populära ramarnas olika latenta utrymmen.
Magiskt
Det är en uppgift som Imagic tar upp. De nytt papper erbjuder många exempel på redigeringar som framgångsrikt ändrar enskilda aspekter av ett foto samtidigt som resten av bilden lämnas orörd.

I Imagic lider inte de ändrade bilderna av den karakteristiska töjningen, förvrängningen och "ocklusionsgissningen" som är karakteristiska för deepfake dockteater, som använder begränsade prioriteringar som härrör från en enda bild.
Systemet använder en process i tre steg – textinbäddningsoptimering; modellfinjustering; och slutligen genereringen av den ändrade bilden.

Imagic kodar måltextprompten för att hämta den ursprungliga textinbäddningen och optimerar sedan resultatet för att få ingångsbilden. Därefter finjusteras den generativa modellen till källbilden och lägger till en rad parametrar innan den utsätts för den begärda interpoleringen.
Föga överraskande är ramverket baserat på Googles Bild text-till-video-arkitektur, även om forskarna säger att systemets principer är brett tillämpliga på latenta diffusionsmodeller.
Imagen använder en arkitektur i tre nivåer, snarare än den sju-nivåer som används för företagets nyare text-till-video iteration av programvaran. De tre distinkta modulerna består av en generativ diffusionsmodell som arbetar med en upplösning på 64x64px; en superupplöst modell som uppskalar denna utdata till 256x256px; och en extra superupplösningsmodell för att ta utdata hela vägen upp till 1024×1024 upplösning.
Imagic ingriper i det tidigaste skedet av denna process och optimerar den begärda textinbäddningen vid 64px-stadiet på en Adam-optimerare med en statisk inlärningshastighet på 0.0001.

En mästarklass i disentanglement: de slutanvändare som har försökt ändra något så enkelt som färgen på ett renderat objekt i en diffusions-, GAN- eller NeRF-modell kommer att veta hur viktigt det är att Imagic kan utföra sådana transformationer utan att "rivas isär" ' konsistensen av resten av bilden.
Finjustering sker sedan på Imagens basmodell, för 1500 steg per ingångsbild, beroende på den reviderade inbäddningen. Samtidigt optimeras det sekundära 64px>256px lagret parallellt på den konditionerade bilden. Forskarna noterar att en liknande optimering för det slutliga lagret på 256px>1024px har "liten eller ingen effekt" på de slutliga resultaten och har därför inte implementerat detta.
Tidningen anger att optimeringsprocessen tar cirka åtta minuter för varje bild på tvilling TPUV4 pommes frites. Den slutliga renderingen sker i kärnbilden under DDIM provtagningsschema.
Gemensamt med liknande finjusteringsprocesser för Googles drömbås, kan de resulterande inbäddningarna dessutom användas för att driva stilisering, såväl som fotorealistiska redigeringar som innehåller information hämtad från den bredare underliggande databasen som driver Imagen (eftersom, som den första kolumnen nedan visar, källbilderna inte har något av det nödvändiga innehållet för att påverka dessa omvandlingar).

Flexibla fotorealistiska rörelser och redigeringar kan framkallas via Imagic, medan de härledda och distrasslade koderna som erhålls i processen lika lätt kan användas för stiliserad produktion.
Forskarna jämförde Imagic med tidigare verk SDEdit, ett GAN-baserat tillvägagångssätt från 2021, ett samarbete mellan Stanford University och Carnegie Mellon University; och Text2Live, ett samarbete, från april 2022, mellan Weizmann Institute of Science och NVIDIA.

En visuell jämförelse mellan Imagic, SDEdit och Text2Live.
Det är uppenbart att de tidigare tillvägagångssätten kämpar, men på den nedre raden, som innebär att man skjuter in en massiv förändring av posen, misslyckas de sittande makthavarna helt med att omforma källmaterialet, jämfört med en anmärkningsvärd framgång från Imagic.
Imagics resurskrav och utbildningstid per bild, även om de är korta enligt standarden för sådana sysselsättningar, gör den till en osannolik inkludering i en lokal bildredigeringsprogram på persondatorer – och det är inte klart i vilken utsträckning finjusteringsprocessen kan vara skalas ner till konsumentnivå.
Som det ser ut är Imagic ett imponerande erbjudande som är mer lämpat för API:er – en miljö som Google Research, som är mycket kritiserad när det gäller att underlätta deepfaking, i alla fall kan vara mest bekväm med.
Första gången publicerad 18 oktober 2022.















