
Umelá inteligencia
Školenie modelov počítačového videnia na náhodnom šume namiesto skutočných obrázkov

Výskumníci z MIT Computer Science & Artificial Intelligence Laboratory (CSAIL) experimentovali s použitím obrázkov náhodného šumu v súboroch údajov počítačového videnia na trénovanie modelov počítačového videnia a zistili, že namiesto produkcie odpadu je táto metóda prekvapivo účinná:

Generatívne modely z experimentu zoradené podľa výkonu. Zdroj: https://openreview.net/pdf?id=RQUl8gZnN7O
Privádzanie zjavného „vizuálneho odpadu“ do populárnych architektúr počítačového videnia by nemalo viesť k tomuto druhu výkonu. Úplne vpravo na obrázku vyššie predstavujú čierne stĺpce skóre presnosti (zap Imagenet-100) pre štyri „skutočné“ súbory údajov. Zatiaľ čo množiny údajov „náhodného šumu“, ktoré mu predchádzali (zobrazené v rôznych farbách, pozri index vľavo hore), sa s tým nemôžu zhodovať, takmer všetky sú v slušnej hornej a dolnej hranici (červené prerušované čiary) pre presnosť.
V tomto zmysle „presnosť“ neznamená, že výsledok nevyhnutne vyzerá ako a činiťsa kostolsa pizzaalebo akúkoľvek inú konkrétnu doménu, pre ktorú by ste mohli mať záujem o vytvorenie syntéza obrazu systém, ako je napríklad Generative Adversarial Network alebo rámec kódovača/dekodéra.
Skôr to znamená, že modely CSAIL odvodili široko použiteľné centrálne „pravdy“ z obrazových údajov tak zjavne neštruktúrovaných, že by ich nemali byť schopné poskytnúť.
Rozmanitosť vs. Naturalizmus
Ani tieto výsledky nemožno pripísať nadmerne padnúci: živý diskusia medzi autormi a recenzentmi na Open Review odhaľuje, že miešanie rôzneho obsahu z vizuálne odlišných súborov údajov (ako sú „mŕtve listy“, „fraktály“ a „procedurálny šum“ – pozri obrázok nižšie) do tréningového súboru údajov skutočne zlepšuje presnosť v týchto experimentoch.
To naznačuje (a je to trochu revolučný pojem) nový typ „nedostatočnej výbavy“, kde „rozmanitosť“ prevažuje nad „naturalizmom“.
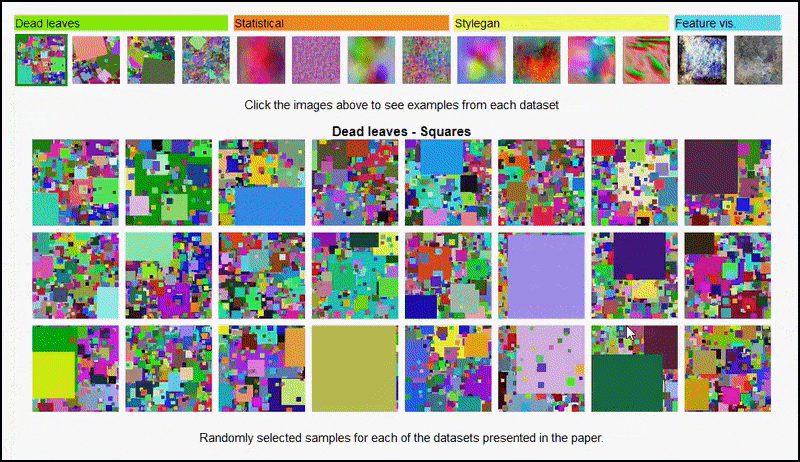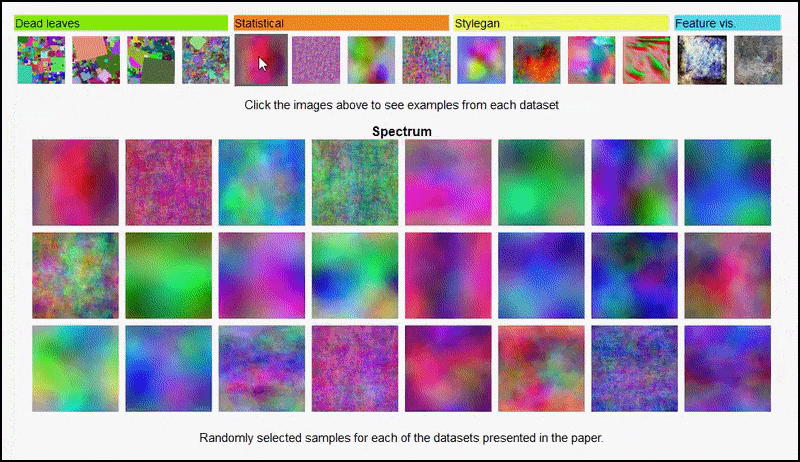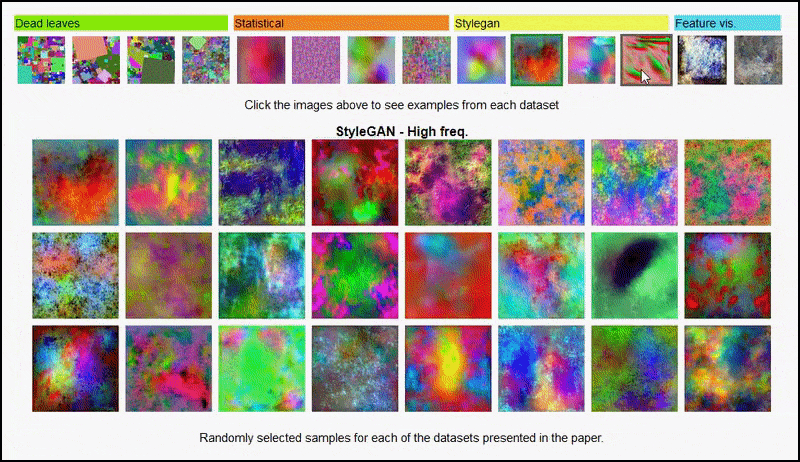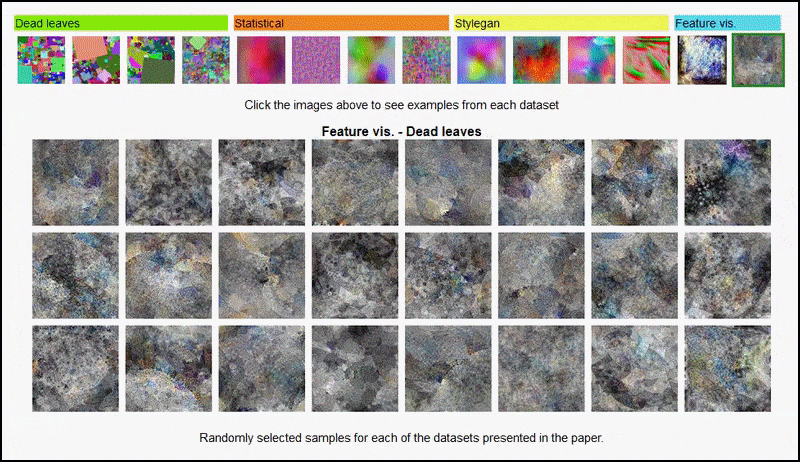
Stránka projektu pre iniciatívu vám umožňuje interaktívne prezerať rôzne typy náhodných súborov údajov obrázkov použitých v experimente. Zdroj: https://mbaradad.github.io/learning_with_noise/
Výsledky získané výskumníkmi spochybňujú základný vzťah medzi neurónovými sieťami založenými na obrázkoch a obrázkami „skutočného sveta“, ktoré sa na nich znepokojivo vrhajú. väčšie objemy každý rok, a naznačujú, že je potrebné získať, liečiť a inak sa hádať hyperškálové obrazové množiny údajov sa nakoniec môže stať nadbytočným. Autori uvádzajú:
„Súčasné systémy videnia sú trénované na obrovských súboroch údajov a tieto súbory údajov sú spojené s nákladmi: liečba je drahá, dedia ľudské predsudky a existujú obavy týkajúce sa súkromia a práv na používanie. S cieľom čeliť týmto nákladom vzrástol záujem o učenie sa z lacnejších zdrojov údajov, ako sú napríklad neoznačené obrázky.
"V tomto dokumente ideme o krok ďalej a pýtame sa, či sa môžeme úplne zbaviť skutočných obrazových súborov údajov tým, že sa poučíme z procesov procesného šumu."
Výskumníci naznačujú, že súčasná úroda architektúr strojového učenia môže z obrázkov vyvodzovať niečo oveľa zásadnejšie (alebo prinajmenšom neočakávané), ako sa predtým myslelo, a že „nezmyselné“ obrázky môžu potenciálne poskytnúť oveľa viac týchto vedomostí. lacno, dokonca aj s možným použitím ad hoc syntetických údajov, prostredníctvom architektúr na generovanie množín údajov, ktoré generujú náhodné obrázky v čase tréningu:
"Identifikujeme dve kľúčové vlastnosti, ktoré vytvárajú dobré syntetické údaje pre tréningové systémy videnia: 1) naturalizmus, 2) rozmanitosť. Je zaujímavé, že najprirodzenejšie údaje nie sú vždy najlepšie, pretože naturalizmus môže prísť na úkor rozmanitosti.
„Skutočnosť, že naturalistické údaje pomáhajú, nemusí byť prekvapujúca a naznačuje, že skutočne veľké údaje majú hodnotu. Zistili sme však, že rozhodujúce nie je to, aby údaje boli skutočný ale aby to bolo naturalistický, teda musí zachytávať určité štrukturálne vlastnosti reálnych dát.
"Mnohé z týchto vlastností možno zachytiť v jednoduchých modeloch hluku."

Vizualizácie funkcií, ktoré sú výsledkom kodéra odvodeného od AlexNet, na niektorých rôznych súboroch údajov „náhodného obrázka“, ktoré používajú autori, a pokrývajú 3. a 5. (finálnu) konvolučnú vrstvu. Tu použitá metodika zodpovedá metodológii uvedenej v Výskum Google AI z roku 2017.
papier, prezentovaný na 35. konferencii o systémoch spracovania neurálnych informácií (NeurIPS 2021) v Sydney, má názov Naučte sa vidieť pohľadom na hluka pochádza od šiestich výskumníkov z CSAIL s rovnakým príspevkom.
Práca bola odporúča na základe konsenzu pre výber pozornosti na NeurIPS 2021, pričom kolegovia komentujúci dokument charakterizujú ako „vedecký prelom“, ktorý otvára „veľkú oblasť štúdia“, aj keď vyvoláva toľko otázok, koľko odpovedí.
V príspevku autori uzatvárajú:
„Ukázali sme, že keď sú navrhnuté s použitím výsledkov z minulých výskumov o štatistike prirodzených obrázkov, tieto súbory údajov môžu úspešne trénovať vizuálne reprezentácie. Dúfame, že tento článok bude motivovať k štúdiu nových generatívnych modelov schopných produkovať štruktúrovaný šum dosahujúci ešte vyšší výkon pri použití v rôznorodom súbore vizuálnych úloh.
„Bolo by možné porovnať výkon získaný s predbežným školením ImageNet? Možno pri absencii veľkého tréningového súboru špecifického pre konkrétnu úlohu nemusí byť najlepším predškolením použitie štandardného skutočného súboru údajov, ako je ImageNet.'















