
Umelá inteligencia
Nebezpečenstvo používania cenových ponúk na overenie obsahu NLG

Názor Modely generovania prirodzeného jazyka ako GPT-3 sú náchylný na „halucinácie“ materiál, ktorý prezentujú v kontexte faktických informácií. V ére, ktorá je mimoriadne znepokojená rastom textových falošných správ, tieto fantazijné úlety „chtivé potešiť“ predstavujú existenčnú prekážku pre rozvoj automatizovaného písania a súhrnných systémov a pre budúcnosť Žurnalistika riadená AI, medzi rôznymi ďalšími podsektormi spracovania prirodzeného jazyka (NLP).
Hlavným problémom je, že jazykové modely v štýle GPT odvodzujú kľúčové vlastnosti a triedy veľmi veľké korpusy školiacich textov a naučiť sa používať tieto funkcie ako stavebné kamene jazyka obratne a autenticky, bez ohľadu na presnosť generovaného obsahu alebo dokonca jeho prijateľnosť.
Systémy NLG sa preto v súčasnosti spoliehajú na overenie faktov človekom jedným z dvoch prístupov: že modely sa buď používajú ako generátory počiatočných textov, ktoré sa okamžite odovzdávajú ľudským používateľom, či už na overenie alebo inú formu úpravy alebo prispôsobenia; alebo že ľudia sa používajú ako drahé filtre na zlepšenie kvality súborov údajov určených na informovanie menej abstraktných a „kreatívnych“ modelov (ktoré samy osebe sú nevyhnutne stále ťažko dôveryhodné z hľadiska faktickej presnosti a ktoré si budú vyžadovať ďalšie úrovne ľudského dohľadu) .
Staré správy a falošné fakty
Modely generovania prirodzeného jazyka (NLG) sú schopné produkovať presvedčivý a hodnoverný výstup, pretože sa naučili sémantickú architektúru, a nie abstraktnejšie asimilovať skutočnú históriu, vedu, ekonómiu alebo akúkoľvek inú tému, ku ktorej by sa od nich mohlo vyžadovať. účinne zapletení ako „cestujúci“ do zdrojových údajov.
Faktická presnosť informácií, ktoré modely NLG generujú, predpokladá, že vstup, na základe ktorého sú trénované, je sám osebe spoľahlivý a aktuálny, čo predstavuje mimoriadnu záťaž z hľadiska predbežného spracovania a ďalšieho overovania na ľudskom základe – nákladného kameň úrazu, ktorý v súčasnosti rieši výskumný sektor NLP na mnohých frontoch.
Systémy v mierke GPT-3 si vyžadujú mimoriadne veľa času a peňazí na trénovanie a po naučení je ťažké ich aktualizovať na úrovni, ktorú možno považovať za „úroveň jadra“. Hoci lokálne modifikácie založené na reláciách a na používateľoch môžu zvýšiť užitočnosť a presnosť implementovaných modelov, tieto užitočné výhody je ťažké a niekedy nemožné preniesť späť do základného modelu bez potreby úplného alebo čiastočného preškolenia.
Z tohto dôvodu je ťažké vytvoriť trénované jazykové modely, ktoré dokážu využiť najnovšie informácie.

Text-davinci-002 – iterácia GPT-3, ktorú jeho tvorca OpenAI považuje za „najschopnejšiu“, vycvičený ešte pred príchodom COVID-u – dokáže spracovať 4000 19 tokenov na žiadosť, ale nevie nič o COVID-2022 alebo ukrajinskej invázii v roku 5. (tieto výzvy a odpovede sú z 2022. apríla 3). Je zaujímavé, že „neznáme“ je v skutočnosti prijateľnou odpoveďou v oboch prípadoch zlyhania, ale ďalšie výzvy ľahko ukazujú, že GPT-XNUMX o týchto udalostiach nevie. Zdroj: https://beta.openai.com/playground
Trénovaný model má prístup iba k „pravdám“, ktoré si osvojil v čase tréningu, a je ťažké získať presný a príslušnú cenovú ponuku štandardne, keď sa pokúšate získať model na overenie svojich tvrdení. Skutočným nebezpečenstvom získania cenových ponúk z predvoleného GPT-3 (napríklad) je to, že niekedy vytvára správne cenové ponuky, čo vedie k falošnej dôvere v tento aspekt jeho schopností:

Najlepšie, tri presné citácie získané v roku 2021 davinci-instruct-text GPT-3. Center, GPT-3 neuvádza jeden z najslávnejších Einsteinových citátov („Boh nehrá kocky s vesmírom“), a to napriek nekryptickej výzve. Dole, GPT-3 priraďuje Albertovi Einsteinovi škandalózny a fiktívny citát, zjavne presahujúci predchádzajúce otázky o Winstonovi Churchillovi v tej istej relácii. Zdroj: Vlastný článok autora z roku 2021 na https://www.width.ai/post/business-applications-for-gpt-3
GopherCite
Spoločnosť Google DeepMind nedávno navrhla vyriešiť tento všeobecný nedostatok v modeloch NLG GopherCite, model s 280 miliardami parametrov, ktorý je schopný citovať konkrétne a presné dôkazy na podporu generovaných reakcií na výzvy.


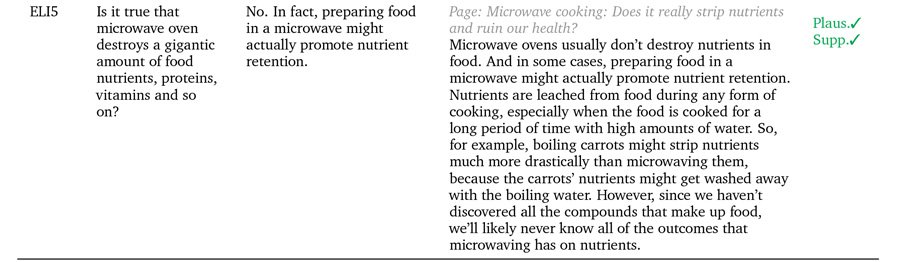
Tri príklady GopherCite podloženého svojimi tvrdeniami skutočnými citáciami. Zdroj: https://arxiv.org/pdf/2203.11147.pdf
GopherCite využíva posilňovanie učenia sa z ľudských preferencií (RLHP) na trénovanie modelov dopytov schopných citovať skutočné citácie ako podporné dôkazy. Citácie sú kreslené naživo z viacerých zdrojov dokumentov získaných z vyhľadávačov alebo z konkrétneho dokumentu poskytnutého používateľom.
Výkon GopherCite bol meraný prostredníctvom ľudského hodnotenia modelových odpovedí, o ktorých sa zistilo, že sú „vysoko kvalitné“ v 80 % prípadov na stránkach Google. NaturalQuestions a 67 % času na EL5 súbor údajov.
Citovanie klamstiev
Avšak pri testovaní proti Oxfordskej univerzite Pravdivá QA benchmarku, odpovede GopherCite boli len zriedka hodnotené ako pravdivé v porovnaní so „správnymi“ odpoveďami, ktoré vymysleli ľudia.
Autori tvrdia, že je to preto, lebo koncept „podporovaných odpovedí“ žiadnym objektívnym spôsobom nepomáha definovať pravdu ako takú, keďže užitočnosť zdrojových citácií môže byť ohrozená inými faktormi, ako je možnosť, že autor citátu je samo osebe „halucinujúce“ (tj písanie o fiktívnych svetoch, produkcia reklamného obsahu alebo inak fantastický neautentický materiál.



Prípady GopherCite, kde sa hodnovernosť nemusí nevyhnutne rovnať „pravde“.
V takýchto prípadoch je skutočne potrebné rozlišovať medzi „podporovaným“ a „pravdivým“. Ľudská kultúra je v súčasnosti ďaleko pred strojovým učením, pokiaľ ide o používanie metodológií a rámcov určených na získanie objektívnych definícií pravdy, a dokonca aj tam sa zdá, že pôvodný stav „dôležitej“ pravdy je spor a okrajové popieranie.
Problém je rekurzívny v architektúrach NLG, ktoré sa snažia navrhnúť definitívne „potvrdzujúce“ mechanizmy: ľudsky riadený konsenzus sa používa ako meradlo pravdy prostredníctvom outsourcingu, AMT-modely štýlu, v ktorých sú ľudskí hodnotitelia (a tí iní ľudia, ktorí sprostredkúvajú spory medzi nimi). samy o sebe čiastočné a zaujaté.
Napríklad počiatočné experimenty GopherCite používajú model „super hodnotiteľa“ na výber najlepších ľudských subjektov na vyhodnotenie výstupu modelu, pričom sa vyberú iba hodnotitelia, ktorí dosiahli aspoň 85 % v porovnaní so súborom zabezpečenia kvality. Nakoniec bolo do úlohy vybraných 113 superhodnotiteľov.
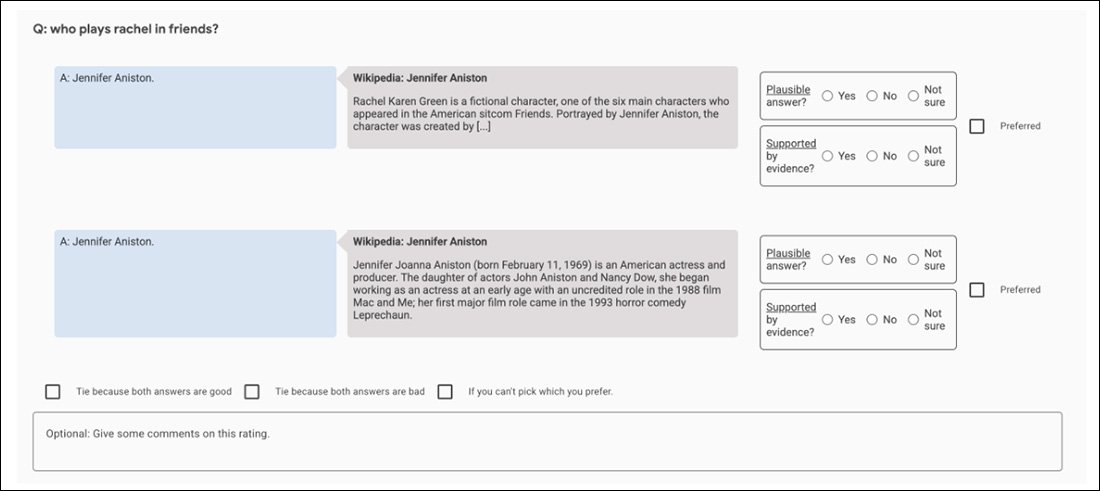
Snímka obrazovky porovnávacej aplikácie, ktorá pomáha vyhodnotiť výstup GopherCite.
Pravdepodobne ide o dokonalý obraz nevyhrateľného hľadania fraktálov: súbor zabezpečenia kvality používaný na hodnotenie hodnotiteľov je sám osebe ďalšou „ľudsky definovanou“ metrikou pravdy, rovnako ako súbor Oxford TruthfulQA, s ktorým GopherCite podľa zistení chýba.
Pokiaľ ide o podporovaný a „overený“ obsah, všetko, čo môžu systémy NLG syntetizovať zo školenia o ľudských údajoch, je ľudská disparita a rozmanitosť, ktorá je sama osebe zle položený a nevyriešený problém. Máme vrodenú tendenciu citovať zdroje, ktoré podporujú naše stanoviská, a vyjadrovať sa autoritatívne a presvedčivo v prípadoch, keď naše zdrojové informácie môžu byť neaktuálne, úplne nepresné alebo inak zámerne nesprávne prezentované iným spôsobom; a dispozíciu šíriť tieto názory priamo do voľnej prírody v rozsahu a účinnosti neprekonanej v histórii ľudstva, priamo na cestu rámcov na získavanie znalostí, ktoré kŕmia nové rámce NLG.
Preto sa zdá, že nebezpečenstvo spojené s vývojom systémov NLG podporovaných citáciami je spojené s nepredvídateľnou povahou zdrojového materiálu. Akýkoľvek mechanizmus (napríklad priame citovanie a úvodzovky), ktorý zvyšuje dôveru používateľov vo výstup NLG, pri súčasnom stave techniky nebezpečne pridáva na autenticite, ale nie na pravdivosti výstupu.
Takéto techniky budú pravdepodobne dostatočne užitočné, keď NLP konečne obnoví „kaleidoskopy“ Orwellovho písania beletrie. Devätnásť osemdesiatštyri; predstavujú však nebezpečnú snahu o objektívnu analýzu dokumentov, žurnalistiku zameranú na umelú inteligenciu a ďalšie možné aplikácie „nefikcie“ strojového súhrnu a spontánneho alebo riadeného generovania textu.
Prvýkrát zverejnené 5. apríla 2022. Aktualizované o 3:29 EET o opravu termínu.















