
Umelá inteligencia
Kontrola zaujatosti riadená AI pre spravodajské články, dostupná v Pythone

Výskumníci v Kanade, Indii, Číne a Austrálii spolupracovali na vytvorení voľne dostupného balíka Python, ktorý možno efektívne použiť na rozpoznanie a nahradenie „nečestného jazyka“ v kópii správ.
Systém s názvom Dbias, využíva rôzne technológie strojového učenia a databázy na vývoj trojstupňového kruhového pracovného toku, ktorý možno spresniť neobjektívny text kým nevráti nezaujatú, alebo aspoň neutrálnejšiu verziu.

Načítaný jazyk v novinovom úryvku označenom ako „zaujatý“ Dbias pretransformuje do menej poburujúcej verzie. Zdroj: https://arxiv.org/ftp/arxiv/papers/2207/2207.03938.pdf
Systém predstavuje opakovane použiteľné a samostatné potrubie, ktoré môže byť nainštalovaný cez Pip od Hugging Face a integrovaná do existujúcich projektov ako doplnková fáza, doplnok alebo doplnok.
V apríli bola podobná funkcia implementovaná v Dokumentoch Google dostal pod kritiku, v neposlednom rade pre nedostatok upraviteľnosti. Na druhej strane Dbias môže byť selektívnejšie trénovaný na akomkoľvek korpuse správ, ktorý si koncový používateľ želá, pričom si zachováva schopnosť vypracovať na mieru šité pokyny pre spravodlivosť.
Zásadným rozdielom je, že kanál Dbias je určený na automatickú transformáciu „nabitého jazyka“ (slová, ktoré pridávajú kritickú vrstvu k faktickej komunikácii) na neutrálny alebo prozaický jazyk, namiesto toho, aby neustále učil používateľa. V podstate koncový používateľ zadefinuje etické filtre a podľa toho vyškolí systém; v prístupe Dokumentov Google systém – pravdepodobne – trénuje používateľa jednostranným spôsobom.
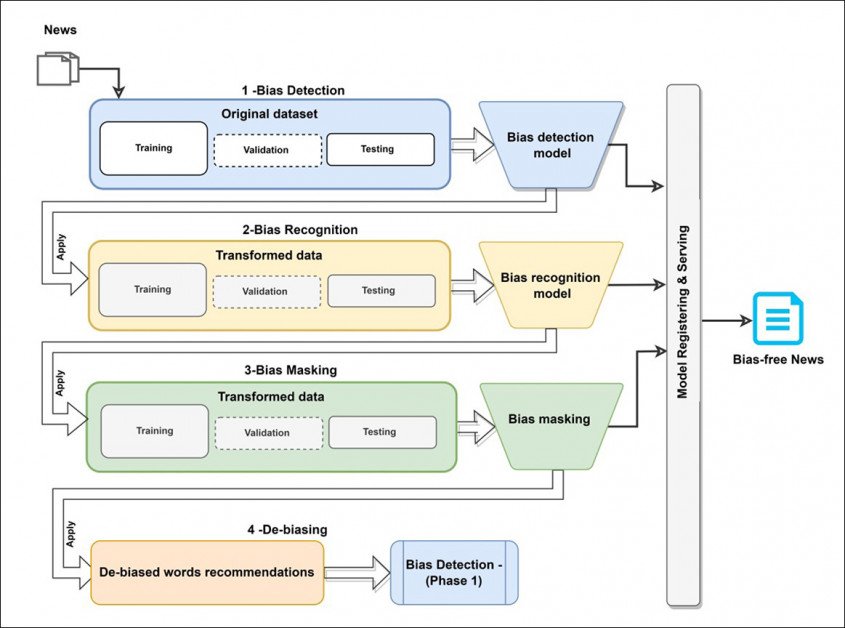
Koncepčná architektúra pre pracovný tok Dbias.
Podľa výskumníkov je Dbias prvým skutočne konfigurovateľným balíkom na detekciu zaujatosti, na rozdiel od bežných montážnych projektov, ktoré doteraz charakterizovali tento podsektor spracovania prirodzeného jazyka (NLP).
nového papiera je s názvom Prístup na zabezpečenie férovosti v spravodajských článkocha pochádza od prispievateľov z University of Toronto, Toronto Metropolitan University, Environmental Resources Management v Bangalore, DeepBlue Academy of Sciences v Číne a The University of Sydney.
Metóda
Prvý modul v Dbias je Detekcia zaujatosti, ktorý využíva DistilBERT balík – vysoko optimalizovaná verzia pomerne strojovo náročného balíka Google BERTI. Pre projekt bol DistilBERT doladený na Media Bias Annotation (MBIC) súbor údajov.

MBIC pozostáva zo spravodajských článkov z rôznych mediálnych zdrojov vrátane Huffington Post, USA Today a MSNBC. Výskumníci použili rozšírenú verziu súboru údajov.
Hoci pôvodné údaje boli anotované pracovníkmi crowdsourcingu (metóda, ktorá dostal sa pod paľbu koncom roku 2021) boli výskumníci nového dokumentu schopní identifikovať ďalšie neoznačené prípady zaujatosti v súbore údajov a manuálne ich pridať. Zistené výskyty zaujatosti súvisiace s rasou, vzdelaním, etnickým pôvodom, jazykom, náboženstvom a pohlavím.
Ďalší modul, Rozpoznávanie zaujatosti, používa Uznanie pomenovanej entity (NER) na oddelenie skreslených slov zo vstupného textu. V papieri sa uvádza:
„Napríklad správa „Nekupujte si pseudovedecký humbuk o tornádach a klimatických zmenách“ bola predchádzajúcim modulom detekcie zaujatosti klasifikovaná ako zaujatá a modul zaujatého rozpoznávania teraz dokáže identifikovať pojem „pseudovedecký humbuk“ ako neobjektívne slovo.“
NER nie je špeciálne navrhnutý pre túto úlohu, ale bol použitý pred pre identifikáciu zaujatosti, najmä pre a Projekt 2021 z Durhamskej univerzity vo Veľkej Británii.
Pre túto fázu výskumníci použili RoBERTa v kombinácii s potrubím SpaCy English Transformer NER.

Ďalšia etapa, Maskovanie zaujatosti, zahŕňa novú viacnásobnú masku identifikovaných skreslených slov, ktorá funguje postupne v prípadoch viacerých identifikovaných skreslených slov.

Načítaný jazyk je nahradený pragmatickým jazykom v tretej fáze Dbias. Všimnite si, že „nahlasovanie“ a „používanie“ sa rovná rovnakému konaniu, hoci to prvé sa považuje za posmešné.
Ak je to potrebné, spätná väzba z tejto fázy bude odoslaná späť na začiatok procesu na ďalšie vyhodnotenie, kým sa nevygeneruje množstvo vhodných alternatívnych fráz alebo slov. Táto fáza využíva maskované jazykové modelovanie (MLM) pozdĺž línií stanovených a spolupráca v roku 2021 vedená spoločnosťou Facebook Research.
Normálne úloha MLM zakryje 15 % slov náhodne, ale pracovný tok Dbias namiesto toho povie procesu, aby vzal identifikované neobjektívne slová ako vstup.
Architektúra bola implementovaná a trénovaná na Google Colab Pro na NVIDIA P100 s 24 GB VRAM pri veľkosti dávky 16, s použitím iba dvoch štítkov (predpojatý a nestranný).
Skúšky
Výskumníci testovali Dbias proti piatim porovnateľným prístupom: LG-TFIDF s Logistická regresia a TfidfVectorizer (TFIDF) vkladanie slov; LG-ELMO; MLP-ELMO (dopredná umelá neurónová sieť obsahujúca vloženie ELMO); BERT; a RoBERTa.
Metriky použité na testy boli presnosť (ACC), presnosť (PREC), zapamätanie (Rec) a skóre F1. Keďže výskumníci nevedeli o žiadnom existujúcom systéme, ktorý by dokázal splniť všetky tri úlohy v jednom potrubí, pre konkurenčné rámce sa upustilo od vyhodnotenia iba primárnych úloh Dbias – detekcie a rozpoznávania zaujatosti.

Výsledky skúšok Dbias.
Dbias uspel v prekonaní výsledkov zo všetkých konkurenčných rámcov, vrátane tých s ťažšou spracovateľskou stopou
Príspevok uvádza:
„Výsledok tiež ukazuje, že hlboké neurálne vnorenia môžu vo všeobecnosti prekonať tradičné metódy vkladania (napr. TFIDF) v úlohe klasifikácie skreslenia. Dokazuje to lepší výkon zabudovania hlbokých neurónových sietí (tj ELMO) v porovnaní s vektorizáciou TFIDF pri použití s LG.
„Je to pravdepodobne preto, že hlboké nervové vloženia dokážu lepšie zachytiť kontext slov v texte v rôznych kontextoch. Hlboké nervové vloženie a hlboké nervové metódy (MLP, BERT, RoBERTa) tiež fungujú lepšie ako tradičná metóda ML (LG).'
Výskumníci tiež poznamenávajú, že metódy založené na transformátoroch prekonávajú konkurenčné metódy v detekcii skreslenia.
Ďalší test zahŕňal porovnanie medzi Dbias a rôznymi príchuťami SpaCy Core Web, vrátane core-sm (malý), core-md (stredný) a core-lg (veľký). Dbias bol schopný viesť predstavenstvo aj v týchto skúškach:

Vedci na záver zistili, že úlohy rozpoznávania skreslenia vo všeobecnosti vykazujú lepšiu presnosť vo väčších a drahších modeloch v dôsledku – špekulujú – v dôsledku zvýšeného počtu parametrov a údajových bodov. Poznamenávajú tiež, že účinnosť budúcej práce v tejto oblasti bude závisieť od väčšieho úsilia o anotáciu vysokokvalitných súborov údajov.
Les a stromy
Dúfajme, že tento druh jemnozrnného projektu na rozpoznávanie zaujatosti bude nakoniec začlenený do rámcov na vyhľadávanie zaujatosti, ktoré sú schopné zaujať menej krátkozraký pohľad a vziať do úvahy, že výber pokrytia akéhokoľvek konkrétneho príbehu je sám o sebe aktom zaujatosti, ktorý je potenciálne poháňané viac než len nahlásenými štatistikami sledovanosti.
Prvýkrát uverejnené 14. júla 2022.















