
Umelá inteligencia
Google predpokladá systém dopytov podobný GPT-3 bez výsledkov vyhľadávania

Nový dokument od štyroch výskumníkov spoločnosti Google navrhuje „expertný“ systém schopný autoritatívne odpovedať na otázky používateľov bez toho, aby predložil zoznam možných výsledkov vyhľadávania, podobne ako paradigma otázok a odpovedí, ktorá sa dostala do pozornosti verejnosti po príchode GPT-3 v minulosti. rok.
papier, oprávnený Prehodnotenie vyhľadávania: Urobte z diletantov odborníkovnavrhuje, že súčasný štandard poskytovania zoznamu výsledkov vyhľadávania používateľovi v odpovedi na dopyt predstavuje „kognitívnu záťaž“, a navrhuje zlepšenie schopnosti systému spracovania prirodzeného jazyka (NLP) poskytnúť smerodajnú a definitívnu odpoveď. .
Podľa navrhovaného modelu „expertného“ orákula z viacerých domén budú tisíce možných zdrojov výsledkov vyhľadávania zapečatené do jazykového modelu namiesto toho, aby boli explicitne dostupné ako prieskumný zdroj pre používateľov, aby ich mohli sami hodnotiť a navigovať. Zdroj: https://arxiv.org/pdf/2105.02274.pdf
Dokument vedený Donaldom Metzlerom z Google Research navrhuje vylepšenia typu multidoménových odpovedí Oracle, ktoré je možné v súčasnosti získať z autoregresívnych jazykových modelov hlbokého učenia, ako je GPT-3. Hlavnými predpokladanými zlepšeniami sú a) že model bude schopný presne citovať zdroje, ktoré informovali o odpovedi, a b) že modelu by sa zabránilo „halucinácie' odpovede alebo vymýšľanie neexistujúceho zdrojového materiálu, čo je v súčasnosti pri takýchto architektúrach problém.
Školenie a schopnosti viacerých domén
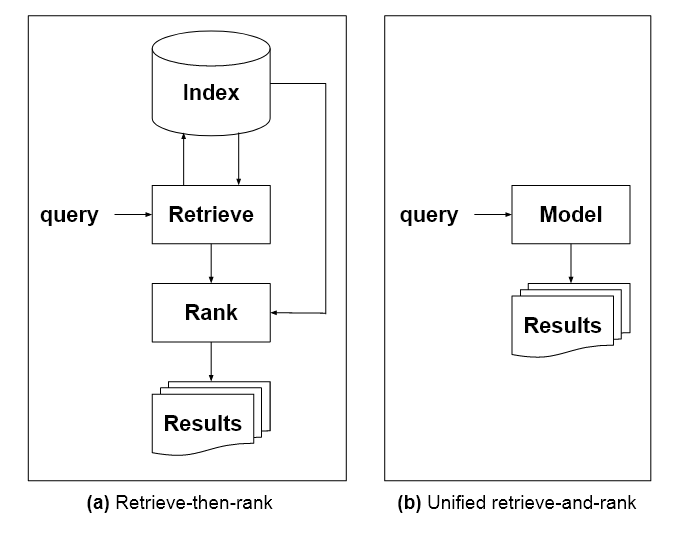
Okrem toho by sa navrhovaný jazykový model, charakterizovaný v článku ako „Jednotný model pre všetky úlohy získavania informácií“, trénoval v rôznych oblastiach vrátane obrázkov a textu. Potrebovalo by to aj pochopenie pôvodu vedomostí, ktoré v architektúrach štýlu GPT-3 chýbajú.
„Na nahradenie indexov jediným zjednoteným modelom musí byť možné, aby samotný model mal znalosti o vesmíre identifikátorov dokumentov, rovnako ako tradičné indexy. Jedným zo spôsobov, ako to dosiahnuť, je posunúť sa od tradičných LM smerom ku korpusovým modelom, ktoré spoločne modelujú vzťahy termín-pojem, termín-dokument a dokument-dokument.'

Na obrázku vyššie z dokumentu sú tri prístupy ako odpoveď na otázku používateľa: vľavo, jazykové modely zahrnuté vo výsledkoch algoritmického vyhľadávania Google si vybrali a uprednostnili „najlepšiu odpoveď“, ale ponechali ju ako najlepší výsledok z mnohých. Center, konverzačná odpoveď v štýle GPT-3, ktorá hovorí s autoritou, ale neospravedlňuje svoje tvrdenia ani neuvádza zdroje. Správne, navrhovaný expertný systém zahŕňa „najlepšiu odozvu“ zo zaradených výsledkov vyhľadávania priamo do didaktickej odpovede, pričom citácie poznámok pod čiarou v akademickom štýle (nie sú zobrazené na pôvodnom obrázku) označujú zdroje, ktoré informujú o odpovedi.
Odstránenie jedovatých a nepresných výsledkov
Výskumníci poznamenávajú, že dynamická a neustále aktualizovaná povaha vyhľadávacích indexov je výzvou na úplnú replikáciu v modeli strojového učenia tohto charakteru. Napríklad tam, kde bol kedysi dôveryhodný zdroj zaškolený priamo do modelového chápania sveta, odstránenie jeho vplyvu (napríklad po jeho zdiskreditovaní) môže byť zložitejšie ako len odstránenie adresy URL zo SERP, pretože koncepty údajov sa môžu stať abstraktné a široko zastúpené počas asimilácie v tréningu.
Okrem toho, takýto model by bolo potrebné neustále trénovať, aby poskytoval rovnakú úroveň odozvy na nové články a publikácie, akú v súčasnosti poskytuje neustále prekrývanie zdrojov Google. V skutočnosti to znamená nepretržité a automatizované zavádzanie, na rozdiel od súčasného režimu, kde sa vykonávajú menšie úpravy váh a nastavení algoritmu vyhľadávania vo voľnom formáte, ale samotný algoritmus sa zvyčajne aktualizuje len zriedka.
Útočné povrchy pre centralizovaný expertný Oracle
Centralizovaný model, ktorý neustále asimiluje a zovšeobecňuje nové údaje, by mohol zmeniť povrch útoku na vyhľadávanie.
V súčasnosti môže útočník získať výhodu dosiahnutím vysokého hodnotenia pre domény alebo stránky, ktoré obsahujú dezinformácie alebo škodlivý kód. Pod záštitou neprehľadnejšieho „expertného“ orákula sa výrazne zmenšila možnosť presmerovania používateľov na útočné domény, ale výrazne sa zvýšila možnosť vstrekovania jedovatých dátových útokov.
Je to preto, že navrhovaný systém neodstraňuje algoritmus hodnotenia vyhľadávania, ale skrýva ho pred používateľom, čím efektívne automatizuje prioritu najlepších výsledkov a spracuje ich (alebo ich) do didaktického vyhlásenia. Používatelia so zlými úmyslami boli už dlho schopní organizovať útoky proti vyhľadávaciemu algoritmu Google predávať falošné výrobky, priamych používateľov do domén šíriacich malvéralebo na účely politická manipulácia, okrem mnohých iných prípadov použitia.
Nie AGI
Výskumníci zdôrazňujú, že je nepravdepodobné, že by sa takýto systém kvalifikoval ako umelá všeobecná inteligencia (AGI) a umiestnil perspektívu univerzálneho expertného respondenta do kontextu spracovania prirodzeného jazyka, ktorý by podliehal všetkým výzvam, ktorým takéto modely v súčasnosti čelia.
Dokument načrtáva päť požiadaviek na „vysokokvalitnú“ odpoveď:
1: Autorita
Rovnako ako v prípade súčasných algoritmov hodnotenia sa zdá, že „autorita“ je odvodená od citácií z domén vysokej kvality, ktoré sa samy osebe považujú za autoritatívne. Výskumníci pozorujú:
„Odpovede by mali generovať obsah čerpaním z vysoko dôveryhodných zdrojov. To je ďalší dôvod, prečo je vytvorenie explicitnejších spojení medzi sekvenciami pojmov a metadátami dokumentu také kľúčové. Ak sú všetky dokumenty v korpuse anotované skóre hodnovernosti, toto skóre by sa malo brať do úvahy pri trénovaní modelu, generovaní odpovedí alebo pri oboch.'
Hoci výskumníci nenaznačujú, že by sa tradičné výsledky SERP stali nedostupnými, ak by sa zistilo, že expertné orákulum tohto typu je výkonné a populárne, celý dokument predstavuje tradičný systém hodnotenia a zoznamy výsledkov vyhľadávania vo svetle „desaťročí“. starý“ a zastaraný systém na vyhľadávanie informácií.
„Samotná skutočnosť, že klasifikácia je kritickým komponentom tejto paradigmy, je symptómom systému vyhľadávania, ktorý používateľom poskytuje výber potenciálnych odpovedí, čo u používateľa vyvoláva pomerne značnú kognitívnu záťaž. Túžba vrátiť odpovede namiesto zoradených zoznamov výsledkov bola jedným z motivačných faktorov pre vývoj systémov odpovedí na otázky. '
2: Transparentnosť
Vedci komentujú:
„Vždy, keď je to možné, mal by sa používateľovi sprístupniť pôvod informácií, ktoré sa predkladajú. Je toto primárny zdroj informácií? Ak nie, aký je primárny zdroj?“
3: Manipulačná zaujatosť
Článok poznamenáva, že vopred pripravené jazykové modely nie sú navrhnuté tak, aby hodnotili empirickú pravdu, ale aby zovšeobecňovali a uprednostňovali dominantné trendy v údajoch. Pripúšťa, že táto smernica otvára model pre útok (ako sa to stalo v prípade Microsoftu neúmyselne rasistický chatbot v roku 2016) a že budú potrebné pridružené systémy na ochranu pred takýmito zaujatými systémovými reakciami.
4: Povolenie rôznych uhlov pohľadu
Dokument tiež navrhuje mechanizmy na zabezpečenie viacerých uhlov pohľadu:
„Vygenerované odpovede by mali predstavovať škálu rôznych perspektív, ale nemali by byť polarizujúce. Napríklad v prípade otázok o kontroverzných témach by mali byť obe strany témy pokryté spravodlivým a vyváženým spôsobom. Toto má očividne úzky súvis so zaujatosťou modelu.“
5: Prístupný jazyk
Okrem poskytovania presných prekladov v prípadoch, keď je považovaná za smerodajnú odpoveď v inom jazyku, dokument navrhuje, že zapuzdrené odpovede by mali byť „napísané čo najjasnejšími výrazmi“.















