AI 101
Hva er RNNs og LSTMs i dypt læring?
Mange av de mest imponerende fremstegene i naturlig språkbehandling og AI-chatbots er drevet av Recurrent Neural Networks (RNNs) og Long Short-Term Memory (LSTM) nettverk. RNNs og LSTMs er spesialne neurale nettverksarkitekturer som kan prosessere sekvensiell data, data hvor kronologisk rekkefølge betyr noe. LSTMs er i hovedsak forbedrede versjoner av RNNs, i stand til å tolke lengre sekvenser av data. La oss se på hvordan RNNs og LSTMS er strukturert og hvordan de muliggjør opprettelsen av sofistikerte naturlig språkbehandlingsystemer.
Hva er Feed-Forward Neural Networks?
Så før vi snakker om hvordan Long Short-Term Memory (LSTM) og Convolutional Neural Networks (CNN) fungerer, bør vi diskutere formatet på et neuralt nettverk generelt.
En neuralt nettverk er ment å undersøke data og lære relevante mønster, så disse mønster kan brukes på andre data og nye data kan klassifiseres. Neurale nettverk er delt inn i tre seksjoner: en inndata-lag, en skjult lag (eller flere skjulte lag), og en utdata-lag.
Inndata-laget er det som tar inn data i neuralt nettverk, mens de skjulte lagene er det som lærer mønster i data. De skjulte lagene i datasett er koblet til inndata- og utdata-lagene med “vekt” og “forvrengning” som bare er antagelser om hvordan datapunktene er relatert til hverandre. Disse vektene justeres under trening. Mens nettverket trener, sammenlignes modellens gjettinger om treningdata (utdata-verdier) mot de faktiske treningsetikettene. Under treningens løp, bør nettverket (håper) bli mer nøyaktig i å forutsi relasjoner mellom datapunkt, så det kan nøyaktig klassifisere nye datapunkt. Dybe neurale nettverk er nettverk som har flere lag i midten/flere skjulte lag. Jo flere skjulte lag og noder modellen har, jo bedre kan modellen gjenkjenne mønster i data.
Vanlige, feed-forward neurale nettverk, som de jeg har beskrevet ovenfor, kalles ofte “tette neurale nettverk”. Disse tette neurale nettverk kombineres med forskjellige nettverksarkitekturer som spesialiserer seg i å tolke forskjellige typer data.
Hva er RNNs (Recurrent Neural Networks)?

Recurrent Neural Networks tar det generelle prinsippet til feed-forward neurale nettverk og muliggjør dem å håndtere sekvensiell data ved å gi modellen en intern minne. “Recurrent”-delen av RNN-navnet kommer fra det faktum at inndata og utdata løkkes. Når utdata fra nettverket produseres, kopieres utdata og returneres til nettverket som inndata. Når det gjøres en avgjørelse, analyseres ikke bare det nåværende inndata og utdata, men også det forrige inndata. For å si det på en annen måte, hvis det opprinnelige inndata for nettverket er X og utdata er H, føres både H og X1 (neste inndata i datasekvensen) inn i nettverket for neste runde med læring. På denne måten bevares konteksten til data (de forrige inndata) mens nettverket trener.
Resultatet av denne arkitekturen er at RNNs er i stand til å håndtere sekvensiell data. Imidlertid lider RNNs av noen problemer. RNNs lider av forsvinnende gradient og eksploderende gradient-problemer.
Lengden på sekvenser som en RNN kan tolke er ganske begrenset, spesielt i sammenligning med LSTMs.
Hva er LSTMs (Long Short-Term Memory Networks)?
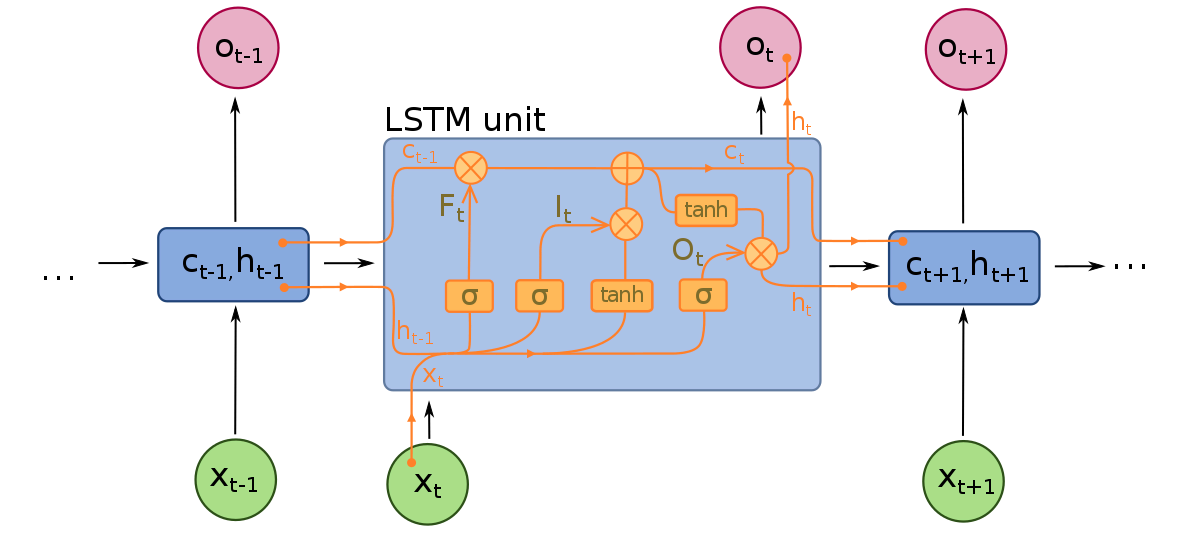
Long Short-Term Memory nettverk kan betraktes som utvidelser av RNNs, en gang til åpne konseptet med å bevare konteksten til inndata. Imidlertid har LSTMs blitt modifisert på noen viktige måter som tillater dem å tolke tidligere data med overlegne metoder. Endringene som er gjort til LSTMs omhandler forsvinnende gradient-problemet og muliggjør LSTMs å vurdere mye lengre inndata-sekvenser.

LSTM-modeller består av tre forskjellige komponenter, eller porter. Det finnes en inndata-port, en utdata-port og en glemme-port. Liksom RNNs, tar LSTMs inndata fra den forrige tidssteg i betraktning når de modifiserer modellens minne og inndata-vekt. Inndata-porten tar beslutninger om hvilke verdier som er viktige og bør slippes gjennom modellen. En sigmoid-funksjon brukes i inndata-porten, som avgjør hvilke verdier som skal slippe gjennom den rekurrerte nettverket. Null dropper verdien, mens 1 bevarer den. En TanH-funksjon brukes her også, som avgjør hvor viktig inndata-verdiene er for modellen, fra -1 til 1.
Etter at de nåværende inndata og minnestatene er tatt i betraktning, avgjør utdata-porten hvilke verdier som skal skyves til neste tidssteg. I utdata-porten analyseres verdiene og tildeles en viktighet fra -1 til 1. Dette regulrerer data før den bringes videre til neste tidssteg-beregning. Til slutt er glemme-portens jobb å droppe informasjon som modellen anser som unødvendig for å ta en avgjørelse om naturen til inndata-verdiene. Glemme-porten bruker en sigmoid-funksjon på verdiene, og utgangen er tall mellom 0 (glem dette) og 1 (bevare dette).
Et LSTM neuralt nettverk består av både spesial-LSTM-lag som kan tolke sekvensiell ord-data og tett koblet lag som de beskrevet ovenfor. Når data flyter gjennom LSTM-lagene, går den videre inn i de tett koblet lagene.








