
AI 101
Hva er CNN-er (Convolutional Neural Networks)?
Kanskje du har lurt på hvordan Facebook eller Instagram er i stand til automatisk å gjenkjenne ansikter i et bilde, eller hvordan Google lar deg søke på nettet etter lignende bilder bare ved å laste opp et eget bilde. Disse funksjonene er eksempler på datasyn, og de drives av konvolusjonelle nevrale nettverk (CNN). Men hva er egentlig konvolusjonelle nevrale nettverk? La oss ta et dypdykk i arkitekturen til et CNN og forstå hvordan de fungerer.
Hva er nevrale nettverk?
Før vi begynner å snakke om konvolusjonelle nevrale nettverk, la oss ta et øyeblikk for å definere vanlige nevrale nettverk. Det er en annen artikkel om temaet nevrale nettverk tilgjengelig, så vi skal ikke gå for dypt inn i dem her. For å kort definere dem er de imidlertid beregningsmodeller inspirert av den menneskelige hjernen. Et nevralt nettverk opererer ved å ta inn data og manipulere dataene ved å justere "vekter", som er antakelser om hvordan inngangsfunksjonene er relatert til hverandre og objektets klasse. Etter hvert som nettverket trenes, justeres verdiene til vektene, og de vil forhåpentligvis konvergere til vekter som nøyaktig fanger forholdet mellom funksjoner.
Dette er hvordan et feed-forward-nevralt nettverk fungerer, og CNN-er består av to halvdeler: et feed-forward-nevralt nettverk og en gruppe konvolusjonslag.
Hva er Convolution Neural Networks (CNN)?
Hva er "svingningene" som skjer i et konvolusjonelt nevralt nettverk? En konvolusjon er en matematisk operasjon som skaper et sett med vekter, i hovedsak skaper en representasjon av deler av bildet. Dette settet med vekter er referert til som en kjerne eller et filter. Filteret som opprettes er mindre enn hele inndatabildet, og dekker bare en underseksjon av bildet. Verdiene i filteret multipliseres med verdiene i bildet. Filteret flyttes så over for å danne en representasjon av en ny del av bildet, og prosessen gjentas til hele bildet er dekket.
En annen måte å tenke på dette på er å forestille seg en murvegg, med klossene som representerer pikslene i inngangsbildet. Et "vindu" skyves frem og tilbake langs veggen, som er filteret. Klossene som er synlige gjennom vinduet er pikslene som har verdien multiplisert med verdiene i filteret. Av denne grunn blir denne metoden for å lage vekter med et filter ofte referert til som "skyvevinduer"-teknikken.
Utdataene fra filtrene som flyttes rundt i hele inngangsbildet er en todimensjonal matrise som representerer hele bildet. Denne matrisen kalles a "funksjonskart".
Hvorfor konvolusjoner er essensielle
Hva er hensikten med å lage konvolusjoner? Konvolusjoner er nødvendige fordi et nevralt nettverk må kunne tolke pikslene i et bilde som numeriske verdier. Funksjonen til konvolusjonslagene er å konvertere bildet til numeriske verdier som det nevrale nettverket kan tolke og deretter trekke ut relevante mønstre fra. Jobben til filtrene i det konvolusjonelle nettverket er å lage en todimensjonal rekke verdier som kan overføres til de senere lagene i et nevralt nettverk, de som vil lære mønstrene i bildet.
Filtre og kanaler
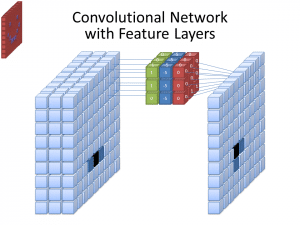
Foto: cecebur via Wikimedia Commons, CC BY SA 4.0 (https://commons.wikimedia.org/wiki/File:Convolutional_Neural_Network_NeuralNetworkFeatureLayers.gif)
CNN-er bruker ikke bare ett filter for å lære mønstre fra inngangsbildene. Det brukes flere filtre, ettersom de forskjellige matrisene som er opprettet av de forskjellige filtrene, fører til en mer kompleks, rik representasjon av inndatabildet. Vanlige antall filtre for CNN-er er 32, 64, 128 og 512. Jo flere filtre det er, jo flere muligheter har CNN til å undersøke inndataene og lære av dem.
En CNN analyserer forskjellene i pikselverdier for å bestemme grensene til objekter. I et gråtonebilde ville CNN bare se på forskjellene i svart og hvitt, lys til mørke termer. Når bildene er fargebilder, tar ikke bare CNN hensyn til mørke og lys, men det må også ta hensyn til de tre forskjellige fargekanalene – rødt, grønt og blått. I dette tilfellet har filtrene 3 kanaler, akkurat som bildet selv gjør. Antall kanaler som et filter har omtales som dets dybde, og antall kanaler i filteret må samsvare med antall kanaler i bildet.
Convolutional Neural Network (CNN) arkitektur
La oss ta en titt på den komplette arkitekturen til et konvolusjonelt nevralt nettverk. Et konvolusjonslag finnes i begynnelsen av hvert konvolusjonsnettverk, da det er nødvendig å transformere bildedataene til numeriske arrays. Imidlertid kan konvolusjonslag også komme etter andre konvolusjonslag, noe som betyr at disse lagene kan stables oppå hverandre. Å ha flere konvolusjonslag betyr at utdataene fra ett lag kan gjennomgå ytterligere konvolusjoner og grupperes sammen i relevante mønstre. I praksis betyr dette at når bildedataene fortsetter gjennom konvolusjonslagene, begynner nettverket å "gjenkjenne" mer komplekse trekk ved bildet.
De tidlige lagene i et ConvNet er ansvarlige for å trekke ut funksjonene på lavt nivå, for eksempel pikslene som utgjør enkle linjer. Senere lag av ConvNet vil knytte disse linjene sammen til former. Denne prosessen med å gå fra analyse på overflatenivå til analyse på dypt nivå fortsetter til ConvNet gjenkjenner komplekse former som dyr, menneskeansikter og biler.
Etter at dataene har passert gjennom alle konvolusjonslagene, fortsetter de inn i den tett sammenkoblede delen av CNN. De tett sammenkoblede lagene er hvordan et tradisjonelt feed-forward nevralt nettverk ser ut, en serie noder som er satt opp i lag som er koblet til hverandre. Dataene fortsetter gjennom disse tett sammenkoblede lagene, som lærer mønstrene som ble ekstrahert av konvolusjonslagene, og ved å gjøre dette blir nettverket i stand til å gjenkjenne objekter.










