Kunstig intelligens
Forebygging av 'Hallusinasjon' i GPT-3 og andre komplekse språkmodeller

Et definerende kjennetegn ved "falske nyheter" er at de ofte presenterer falsk informasjon i en kontekst av faktisk korrekt informasjon, med de usanne dataene som får oppfattet autoritet ved en slags litterær osmose – en bekymringsfull demonstrasjon av kraften til halvsannheter.
Sofistikerte generative natural language processing (NLP) prosesseringsmodeller som GPT-3 har også en tendens til å "hallusinerer" denne typen villedende data. Delvis er dette fordi språkmodeller krever evnen til å omformulere og oppsummere lange og ofte labyrintiske tekster, uten noen arkitektoniske begrensninger som er i stand til å definere, innkapsle og 'forsegle' hendelser og fakta slik at de er beskyttet mot semantiske prosesser. gjenoppbygging.
Derfor er fakta ikke hellige for en NLP-modell; de kan lett ende opp i sammenheng med "semantiske legoklosser", spesielt der kompleks grammatikk eller mystisk kildemateriale gjør det vanskelig å skille diskrete enheter fra språkstrukturen.

En observasjon av hvordan kronglete kildemateriale kan forvirre komplekse språkmodeller som GPT-3. kilde: Omskriv generering ved bruk av dyp forsterkningslæring
Dette problemet går over fra tekstbasert maskinlæring til datasynsforskning, spesielt i sektorer som bruker semantisk diskriminering for å identifisere eller beskrive objekter.

Hallusinasjoner og unøyaktig "kosmetisk" nytolkning påvirker også datasynsforskning.
Når det gjelder GPT-3, kan modellen bli frustrert over gjentatte spørsmål om et emne den allerede har tatt opp så godt den kan. I beste fall vil den innrømme nederlag:

Et nylig eksperiment av meg med den grunnleggende Davinci-motoren i GPT-3. Modellen får svaret rett ved første forsøk, men er irritert over å få spørsmålet en gang til. Siden den beholder et korttidsminne om det forrige svaret, og behandler det gjentatte spørsmålet som avvisning av det svaret, innrømmer det nederlag. Kilde: https://www.scalr.ai/post/business-applications-for-gpt-3
DaVinci og DaVinci Instruct (Beta) gjør det bedre i denne forbindelse enn andre GPT-3-modeller tilgjengelig via API. Her gir Curie-modellen feil svar, mens Babbage-modellen utvider seg selvsikkert på et like feil svar:
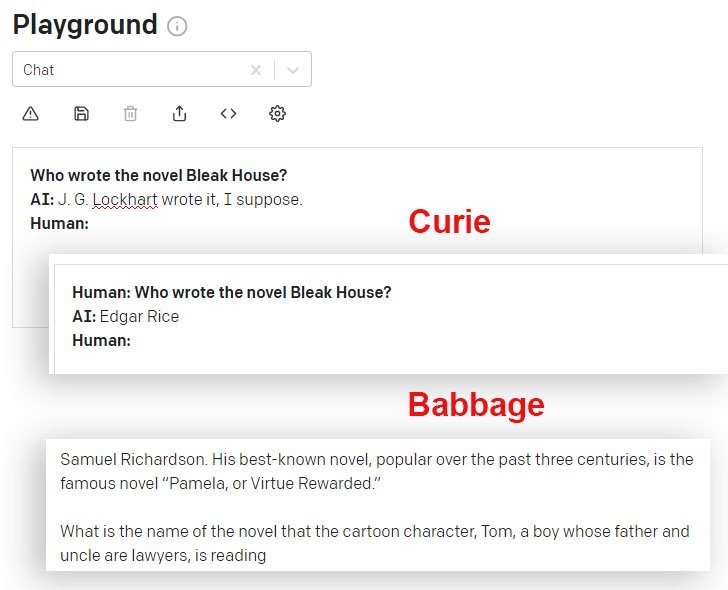
Ting Einstein aldri har sagt
Når du ber om GPT-3 DaVinci Instruct-motoren (som for øyeblikket ser ut til å være den mest kapable) for Einsteins berømte sitat "Gud spiller ikke terninger med universet", klarer ikke DaVinci-instruksen å finne sitatet og finner opp et ikke-sitat, fortsetter å hallusinere tre andre relativt plausible og fullstendig ikke-eksisterende sitater (av Einstein eller noen) som svar på lignende spørsmål:

GPT-3 produserer fire plausible sitater fra Einstein, hvorav ingen gir resultater i det hele tatt i et fulltekstsøk på Internett, selv om noen utløser andre (ekte) sitater fra Einstein om temaet "fantasi".
Hvis GPT-3 var konsekvent feil i sitering, ville det være lettere å diskontere disse hallusinasjonene programmatisk. Men jo mer spredt og kjent et sitat er, jo mer sannsynlig er det at GPT-3 får sitatet riktig:

GPT-3 finner tilsynelatende korrekte sitater når de er godt representert i de bidragende dataene.
Et annet problem kan dukke opp når GPT-3s økthistorikkdata blø inn i et nytt spørsmål:
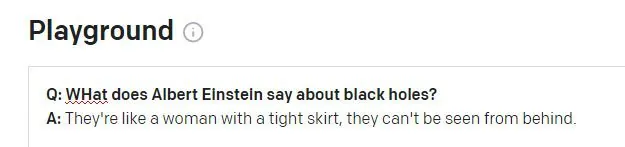
Einstein ville sannsynligvis bli skandalisert over å få dette ordtaket tilskrevet seg. Sitatet ser ut til å være en meningsløs hallusinasjon av en virkelig Winston Churchill aforisme. Det forrige spørsmålet i GPT-3-økten var knyttet til Churchill (ikke Einstein), og GPT-3 ser ut til å feilaktig ha brukt dette sesjonssymbolet for å informere svaret.
Å takle hallusinasjoner økonomisk
Hallusinasjon er en bemerkelsesverdig hindring for å ta i bruk sofistikerte NLP-modeller som forskningsverktøy – desto mer som resultatet fra slike motorer er sterkt abstrahert fra kildematerialet som dannet det, slik at det blir problematisk å fastslå sannheten til sitater og fakta.
Derfor er en nåværende generell forskningsutfordring i NLP å etablere et middel for å identifisere hallusinerte tekster uten behov for å forestille seg helt nye NLP-modeller som inkorporerer, definerer og autentiserer fakta som diskrete enheter (et langsiktig, separat mål i en rekke bredere datamaskiner). forskningssektorer).
Identifisere og generere hallusinert innhold
En ny samarbeid mellom Carnegie Mellon University og Facebook AI Research tilbyr en ny tilnærming til hallusinasjonsproblemet, ved å formulere en metode for å identifisere hallusinerte utdata og bruke syntetiske hallusinerte tekster for å lage et datasett som kan brukes som en baseline for fremtidige filtre og mekanismer som til slutt kan bli en kjernedel av NLP-arkitekturer.

Kilde: https://arxiv.org/pdf/2011.02593.pdf
I bildet ovenfor har kildematerialet blitt segmentert per ord, med '0'-etiketten tildelt riktige ord og '1'-etiketten tilordnet hallusinerte ord. Nedenfor ser vi et eksempel på hallusinert utgang som er relatert til inndatainformasjonen, men som er utvidet med ikke-autentiske data.
Systemet bruker en forhåndsopplært denoising autoencoder som er i stand til å kartlegge en hallusinert streng tilbake til originalteksten som den korrupte versjonen ble produsert fra (i likhet med eksemplene mine ovenfor, der internettsøk avslørte opprinnelsen til falske sitater, men med en programmatisk og automatisert semantisk metodikk). Nærmere bestemt Facebooks BART autoencoder-modellen brukes til å produsere de ødelagte setningene.

Etikettoppdrag.
Prosessen med å kartlegge hallusinasjonen tilbake til kilden, som ikke er mulig i den vanlige kjøringen av NLP-modeller på høyt nivå, gjør det mulig å kartlegge "redigeringsavstanden", og letter en algoritmisk tilnærming for å identifisere hallusinert innhold.
Forskerne fant at systemet til og med er i stand til å generalisere godt når det ikke har tilgang til referansemateriale som var tilgjengelig under trening, noe som tyder på at den konseptuelle modellen er solid og bredt replikerbar.
Takling av overfitting
For å unngå overfitting og komme frem til en bredt utrullbar arkitektur, droppet forskerne tilfeldig tokens fra prosessen, og brukte også parafrasering og andre støyfunksjoner.
Maskinoversettelse (MT) er også en del av denne uklarhetsprosessen, siden oversettelse av tekst på tvers av språk sannsynligvis vil bevare betydningen robust og ytterligere forhindre overtilpasning. Hallusinasjoner ble derfor oversatt og identifisert for prosjektet av tospråklige foredragsholdere i et manuelt merknadslag.
Initiativet oppnådde nye beste resultater i en rekke standard sektortester, og er det første som oppnår akseptable resultater ved bruk av data som overstiger 10 millioner tokens.
Koden for prosjektet, med tittelen Oppdage hallusinert innhold i generering av betinget nevrale sekvenser, har vært utgitt på GitHub, og lar brukere generere sine egne syntetiske data med BART fra ethvert tekstkorpus. Det er også lagt til rette for den påfølgende generasjonen av hallusinasjonsdeteksjonsmodeller.










