
Kunstig intelligens
EfficientViT: Memory Efficient Vision Transformer for høyoppløselig datasyn

På grunn av sin høye modellkapasitet har Vision Transformer-modeller hatt stor suksess i nyere tid. Til tross for ytelsen har vision-transformatormodeller én stor feil: deres bemerkelsesverdige beregningsevne kommer til høye beregningskostnader, og det er grunnen til at vision-transformatorer ikke er førstevalget for sanntidsapplikasjoner. For å takle dette problemet lanserte en gruppe utviklere EfficientViT, en familie av høyhastighetssynstransformatorer.
Når de jobbet med EfficientViT, observerte utviklere at hastigheten til de nåværende transformatormodellene ofte er begrenset av ineffektive minneoperasjoner, spesielt elementmessige funksjoner og tensoromforming i MHSA- eller Multi-Head Self Attention-nettverk. For å takle disse ineffektive minneoperasjonene har EfficientViT-utviklere jobbet med en ny byggestein ved bruk av en sandwich-layout, dvs. at EfficientViT-modellen bruker et enkelt minnebundet Multi-Head Self Attention-nettverk mellom effektive FFN-lag som hjelper til med å forbedre minneeffektiviteten, og også forbedre den generelle kanalkommunikasjonen. Videre oppdager modellen også at oppmerksomhetskart ofte har høye likheter på tvers av hodet som fører til beregningsredundans. For å takle redundansspørsmålet presenterer EfficientViT-modellen en kaskadedelt gruppeoppmerksomhetsmodul som mater oppmerksomhetshoder med forskjellige deler av hele funksjonen. Metoden hjelper ikke bare med å spare beregningskostnader, men forbedrer også oppmerksomhetsmangfoldet til modellen.
Omfattende eksperimenter utført på EfficientViT-modellen på tvers av ulike scenarier indikerer at EfficientViT utkonkurrerer eksisterende effektive modeller for datasyn mens du oppnår en god avveining mellom nøyaktighet og hastighet. Så la oss ta et dypere dykk, og utforske EfficientViT-modellen litt mer i dybden.
En introduksjon til Vision Transformers og EfficientViT
Vision Transformers er fortsatt et av de mest populære rammeverkene i datasynsindustrien fordi de tilbyr overlegen ytelse og høye beregningsevner. Men med stadig forbedring av nøyaktigheten og ytelsen til visjonstransformatormodellene, øker også driftskostnadene og beregningsmessige overhead. For eksempel bruker nåværende modeller som er kjent for å gi toppmoderne ytelse på ImageNet-datasett som SwinV2 og V-MoE henholdsvis 3B og 14.7B parametere. Selve størrelsen på disse modellene kombinert med beregningskostnadene og kravene gjør dem praktisk talt uegnet for sanntidsenheter og -applikasjoner.
EfficientNet-modellen har som mål å utforske hvordan man kan øke ytelsen til vision transformator modeller, og finne prinsippene bak utforming av effektive og effektive transformatorbaserte rammeverkarkitekturer. EfficientViT-modellen er basert på eksisterende vision transformator-rammeverk som Swim og DeiT, og den analyserer tre essensielle faktorer som påvirker interferenshastigheter for modellene, inkludert beregningsredundans, minnetilgang og parameterbruk. Videre observerer modellen at hastigheten til vision-transformatormodeller i minnebundet, noe som betyr at full utnyttelse av datakraft i CPUer/GPUer er forbudt eller begrenset av minnetilgangsforsinkelse, som resulterer i negativ innvirkning på kjøretidshastigheten til transformatorene . Elementmessige funksjoner og omforming av tensor i MHSA- eller Multi-Head Self Attention-nettverk er de mest minneineffektive operasjonene. Modellen observerer videre at optimal justering av forholdet mellom FFN (feed forward-nettverk) og MHSA kan bidra til å redusere minnetilgangstiden betydelig uten å påvirke ytelsen. Imidlertid observerer modellen også noe redundans i oppmerksomhetskartene som et resultat av oppmerksomhetshodets tendens til å lære lignende lineære projeksjoner.
Modellen er en siste kultivering av funnene under forskningsarbeidet for EfficientViT. Modellen har en ny sort med sandwich-layout som påfører et enkelt minnebundet MHSA-lag mellom Feed Forward Network eller FFN-lagene. Tilnærmingen reduserer ikke bare tiden det tar å utføre minnebundne operasjoner i MHSA, men den gjør også hele prosessen mer minneeffektiv ved å la flere FFN-lag lette kommunikasjonen mellom ulike kanaler. Modellen bruker også en ny CGA eller Cascaded Group Attention-modul som har som mål å gjøre beregningene mer effektive ved å redusere beregningsredundansen ikke bare i oppmerksomhetshodene, men også øke dybden på nettverket, noe som resulterer i forhøyet modellkapasitet. Til slutt utvider modellen kanalbredden til viktige nettverkskomponenter inkludert verdiprojeksjoner, mens den krymper nettverkskomponenter med lav verdi som skjulte dimensjoner i feed forward-nettverkene for å omfordele parameterne i rammeverket.

Som det kan sees i bildet ovenfor, yter EfficientViT-rammeverket bedre enn dagens moderne CNN- og ViT-modeller når det gjelder både nøyaktighet og hastighet. Men hvordan klarte EfficientViT-rammeverket å utkonkurrere noen av dagens rammeverk? La oss finne ut av det.
EfficientViT: Forbedring av effektiviteten til Vision Transformers
EfficientViT-modellen har som mål å forbedre effektiviteten til de eksisterende vision transformator-modellene ved å bruke tre perspektiver,
- Beregningsredundans.
- Minnetilgang.
- Parameterbruk.
Modellen har som mål å finne ut hvordan parametrene ovenfor påvirker effektiviteten til vision transformator-modeller, og hvordan de kan løses for å oppnå bedre resultater med bedre effektivitet. La oss snakke om dem litt mer i dybden.
Minnetilgang og effektivitet
En av de vesentlige faktorene som påvirker hastigheten til en modell er minnetilgang overhead eller MAO. Som det kan sees på bildet nedenfor, er flere operatører i transformator inkludert elementvis addisjon, normalisering og hyppig omforming minneineffektive operasjoner, fordi de krever tilgang til forskjellige minneenheter, noe som er en tidkrevende prosess.
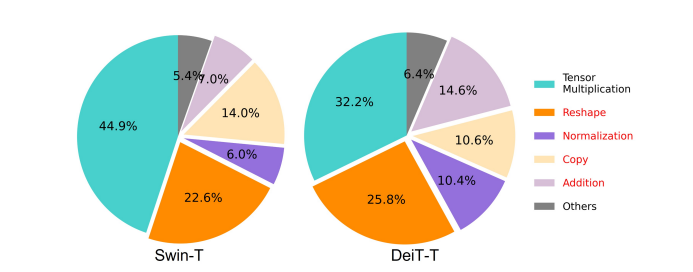
Selv om det finnes noen eksisterende metoder som kan forenkle standard softmax selvoppmerksomhetsberegninger som lav rangering og sparsom oppmerksomhet, tilbyr de ofte begrenset akselerasjon og forringer nøyaktigheten.
På den annen side har EfficientViT-rammeverket som mål å kutte ned kostnadene for minnetilgang ved å redusere mengden minneineffektive lag i rammeverket. Modellen skalerer ned DeiT-T og Swin-T til små undernettverk med en høyere interferensgjennomstrømning på 1.25X og 1.5X, og sammenligner ytelsen til disse undernettverkene med proporsjoner av MHSA-lagene. Som det kan sees på bildet nedenfor, når den implementeres, øker tilnærmingen nøyaktigheten til MHSA-lagene med omtrent 20 til 40 %.

Beregningseffektivitet
MHSA-lag har en tendens til å bygge inn inngangssekvensen i flere underrom eller hoder, og beregner oppmerksomhetskartene individuelt, en tilnærming som er kjent for å øke ytelsen. Imidlertid er oppmerksomhetskart ikke beregningsmessig billig, og for å utforske beregningskostnadene, utforsker EfficientViT-modellen hvordan man kan redusere overflødig oppmerksomhet i mindre ViT-modeller. Modellen måler den maksimale cosinuslikheten til hvert hode og de gjenværende hodene innenfor hver blokk ved å trene de breddenedskalerte DeiT-T- og Swim-T-modellene med 1.25× inferenshastighet. Som det kan observeres på bildet nedenfor, er det et stort antall likheter mellom oppmerksomhetshoder som antyder at modellen pådrar seg beregningsredundans fordi mange hoder har en tendens til å lære lignende projeksjoner av den nøyaktige fullfunksjonen.

For å oppmuntre hodene til å lære forskjellige mønstre, bruker modellen eksplisitt en intuitiv løsning der hvert hode bare mates med en del av hele funksjonen, en teknikk som ligner ideen om gruppekonvolusjon. Modellen trener forskjellige aspekter av de nedskalerte modellene som har modifiserte MHSA-lag.
Parameter Effektivitet
Gjennomsnittlige ViT-modeller arver designstrategiene sine, som å bruke en ekvivalent bredde for projeksjoner, sette ekspansjonsforholdet til 4 i FFN og øke nivåene over trinnene fra NLP-transformatorer. Konfigurasjonene til disse komponentene må re-designes nøye for lette moduler. EfficientViT-modellen distribuerer Taylor-strukturert beskjæring for å finne de essensielle komponentene i Swim-T- og DeiT-T-lagene automatisk, og utforsker videre de underliggende parametertildelingsprinsippene. Under visse ressursbegrensninger fjerner beskjæringsmetodene uviktige kanaler, og beholder de kritiske for å sikre høyest mulig nøyaktighet. Figuren nedenfor sammenligner forholdet mellom kanaler og inngangs-innstøpingen før og etter beskjæring på Swin-T-rammeverket. Det ble observert at: Grunnlinjenøyaktighet: 79.1 %; beskjæringsnøyaktighet: 76.5 %.

Bildet ovenfor indikerer at de to første stadiene av rammeverket bevarer flere dimensjoner, mens de to siste stadiene bevarer mye mindre dimensjoner. Det kan bety at en typisk kanalkonfigurasjon som dobler kanalen etter hvert trinn eller bruker tilsvarende kanaler for alle blokker, kan resultere i betydelig redundans i de siste blokkene.
Efficient Vision Transformer: Arkitektur
På grunnlag av læringen som ble oppnådd under analysen ovenfor, jobbet utviklere med å lage en ny hierarkisk modell som tilbyr høye interferenshastigheter, EffektivViT modell. La oss ta en detaljert titt på strukturen til EfficientViT-rammeverket. Figuren nedenfor gir deg en generisk idé om EfficientViT-rammeverket.
Byggesteiner i EfficientViT Framework
Byggesteinen for det mer effektive synstransformatornettverket er illustrert i figuren nedenfor.

Rammeverket består av en kaskadedelt gruppeoppmerksomhetsmodul, minneeffektiv sandwich-layout og en parameteromfordelingsstrategi som fokuserer på å forbedre effektiviteten til modellen med hensyn til henholdsvis beregning, minne og parameter. La oss snakke om dem mer detaljert.
Sandwich layout
Modellen bruker en ny sandwich-layout for å bygge en mer effektiv og effektiv minneblokk for rammeverket. Sandwich-oppsettet bruker mindre minnebundne selvoppmerksomhetslag, og benytter seg av mer minneeffektive feed forward-nettverk for kanalkommunikasjon. For å være mer spesifikk bruker modellen et enkelt selvoppmerksomhetslag for romlig blanding som er klemt mellom FFN-lagene. Designet hjelper ikke bare med å redusere minnetidsforbruket på grunn av selvoppmerksomhetslag, men tillater også effektiv kommunikasjon mellom forskjellige kanaler i nettverket takket være bruken av FFN-lag. Modellen bruker også et ekstra interaksjonstokenlag før hvert feed forward-nettverkslag ved å bruke en DWConv eller Deceptive Convolution, og forbedrer modellkapasiteten ved å introdusere induktiv skjevhet av den lokale strukturelle informasjonen.
Kaskadert gruppeoppmerksomhet
Et av hovedproblemene med MHSA-lag er redundansen i oppmerksomhetshoder som gjør beregningene mer ineffektive. For å løse problemet foreslår modellen CGA eller Cascaded Group Attention for synstransformatorer, en ny oppmerksomhetsmodul som henter inspirasjon fra gruppekonvolusjoner i effektive CNN-er. I denne tilnærmingen mater modellen individuelle hoder med splittelser av alle funksjonene, og dekomponerer derfor oppmerksomhetsberegningen eksplisitt på tvers av hoder. Å dele opp funksjonene i stedet for å mate alle funksjoner til hvert hode sparer beregninger og gjør prosessen mer effektiv, og modellen fortsetter å jobbe med å forbedre nøyaktigheten og kapasiteten ytterligere ved å oppmuntre lagene til å lære projeksjoner på funksjoner som har rikere informasjon.

Parameteromfordeling
For å forbedre effektiviteten til parametere, omdisponerer modellen parameterne i nettverket ved å utvide bredden på kanalen til kritiske moduler mens den krymper kanalbredden til ikke så viktige moduler. Basert på Taylor-analysen, setter modellen enten små kanaldimensjoner for projeksjoner i hvert hode under hvert trinn, eller modellen lar projeksjonene ha samme dimensjon som inngangen. Utvidelsesforholdet til feed forward-nettverket er også redusert til 2 fra 4 for å hjelpe med parameterredundansen. Den foreslåtte omfordelingsstrategien som EfficientViT-rammeverket implementerer, tildeler flere kanaler til viktige moduler for å la dem lære representasjoner i et høydimensjonalt rom bedre som minimerer tap av funksjonsinformasjon. For å fremskynde interferensprosessen og øke effektiviteten til modellen ytterligere, fjerner modellen automatisk de overflødige parametrene i uviktige moduler.

Oversikten over EfficientViT-rammeverket kan forklares i bildet ovenfor der delene,
- Arkitektur av EfficientViT,
- Sandwich Layout blokk,
- Kaskadert gruppeoppmerksomhet.
EfficientViT: Nettverksarkitekturer

Bildet ovenfor oppsummerer nettverksarkitekturen til EfficientViT-rammeverket. Modellen introduserer en overlappende patch-innbygging [20,80] som bygger inn 16×16 patcher i C1-dimensjonstokener som forbedrer modellens kapasitet til å yte bedre i visuell representasjonslæring på lavt nivå. Arkitekturen til modellen består av tre stadier der hvert trinn stabler de foreslåtte byggeklossene til EfficientViT-rammeverket, og antall tokens ved hvert subsamplinglag (2× subsampling av oppløsningen) reduseres med 4X. For å gjøre subsampling mer effektiv, foreslår modellen en subsample-blokk som også har den foreslåtte sandwich-layouten med unntak av at en invertert restblokk erstatter oppmerksomhetslaget for å redusere tap av informasjon under sampling. Videre, i stedet for konvensjonell LayerNorm(LN), bruker modellen BatchNorm(BN) fordi BN kan brettes inn i de foregående lineære eller konvolusjonelle lagene som gir den en kjøretidsfordel i forhold til LN.
EfficientViT modellfamilie
EfficientViT-modellfamilien består av 6 modeller med forskjellige dybde- og breddeskalaer, og et bestemt antall hoder er tildelt for hvert trinn. Modellene bruker færre blokker i de innledende stadiene sammenlignet med de siste stadiene, en prosess som ligner på den som følges av MobileNetV3-rammeverket fordi prosessen med tidlig prosessering med større oppløsninger er tidkrevende. Bredden økes over etapper med en liten faktor for å redusere redundans i de senere trinn. Tabellen vedlagt nedenfor gir de arkitektoniske detaljene til EfficientViT-modellfamilien der C, L og H refererer til bredde, dybde og antall hoder i det bestemte stadiet.

EfficientViT: Modellimplementering og resultater
EfficientViT-modellen har en total batchstørrelse på 2,048 300, er bygget med Timm & PyTorch, er trent fra bunnen av i 8 epoker ved bruk av 100 Nvidia V1 GPUer, bruker en cosinus-læringshastighetsplanlegger, en AdamW-optimaliserer og utfører sitt bildeklassifiseringseksperiment på ImageNet -224K. Inngangsbildene beskjæres tilfeldig og endres til en oppløsning på 224×300. For eksperimentene som involverer nedstrøms bildeklassifisering, finjusterer EfficientViT-rammeverket modellen for 256 epoker, og bruker AdamW optimizer med en batchstørrelse på 12. Modellen bruker RetineNet for objektdeteksjon på COCO, og fortsetter med å trene modellene i ytterligere XNUMX epoker med identiske innstillinger.
Resultater på ImageNet
For å analysere ytelsen til EfficientViT, sammenlignes den med gjeldende ViT- og CNN-modeller på ImageNet-datasettet. Resultatene fra sammenligningen er rapportert i følgende figur. Ettersom det kan sees at EfficientViT-modellfamilien overgår gjeldende rammeverk i de fleste tilfeller, og klarer å oppnå en ideell avveining mellom hastighet og nøyaktighet.

Sammenligning med effektive CNN-er og effektive ViT-er
Modellen sammenligner først ytelsen med Efficient CNN-er som EfficientNet og vanilla CNN-rammeverk som MobileNets. Som det kan sees at sammenlignet med MobileNet-rammeverk, oppnår EfficientViT-modellene en bedre topp-1-nøyaktighetsscore, mens de kjører 3.0X og 2.5X raskere på henholdsvis Intel CPU og V100 GPU.
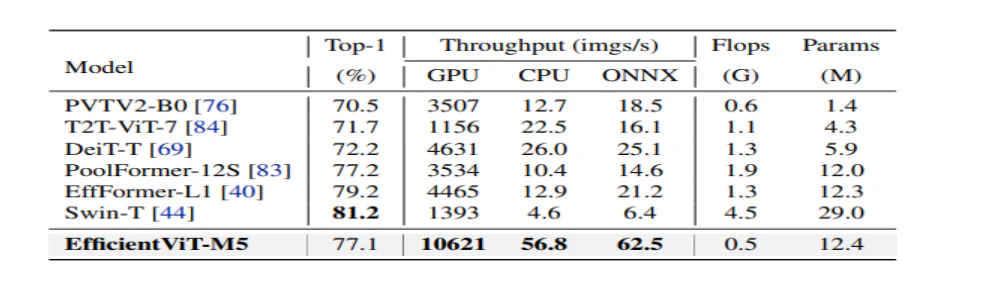
Figuren ovenfor sammenligner EfficientViT-modellytelsen med toppmoderne storskala ViT-modeller som kjører på ImageNet-1K-datasettet.
Nedstrøms bildeklassifisering
EfficientViT-modellen brukes på ulike nedstrømsoppgaver for å studere modellens overføringslæringsevner, og bildet nedenfor oppsummerer resultatene av eksperimentet. Som det kan observeres, klarer EfficientViT-M5-modellen å oppnå bedre eller lignende resultater på tvers av alle datasett samtidig som den opprettholder en mye høyere gjennomstrømning. Det eneste unntaket er Cars-datasettet, der EfficientViT-modellen ikke klarer å levere nøyaktig.

Objektdeteksjon
For å analysere EfficientViTs evne til å oppdage objekter, sammenlignes den med effektive modeller på COCO objektdeteksjonsoppgaven, og bildet nedenfor oppsummerer resultatene av sammenligningen.

Final Thoughts
I denne artikkelen har vi snakket om EfficientViT, en familie av transformatormodeller for hurtigsyn som bruker kaskadet gruppeoppmerksomhet og gir minneeffektive operasjoner. Omfattende eksperimenter utført for å analysere ytelsen til EfficientViT har vist lovende resultater ettersom EfficientViT-modellen i de fleste tilfeller overgår gjeldende CNN- og vision-transformatormodeller. Vi har også forsøkt å gi en analyse av faktorene som spiller en rolle for å påvirke interferenshastigheten til synstransformatorer.















