
Artificial Intelligence
Het JPEG-artefactprobleem oplossen in Computer Vision-datasets
Een nieuwe studie van de Universiteit van Maryland en Facebook AI heeft een 'aanzienlijke prestatievermindering' gevonden voor deep learning-systemen die sterk gecomprimeerde JPEG-afbeeldingen gebruiken in hun datasets, en biedt enkele nieuwe methoden om de effecten hiervan te verzachten.
De verslag, getiteld Analyseren en beperken van JPEG-compressiedefecten in Deep Learning, beweert 'aanzienlijk uitgebreider' te zijn dan eerdere onderzoeken naar de effecten van artefacten bij het trainen van computervisiedatasets. Het artikel constateert dat '[zware] tot matige JPEG-compressie een aanzienlijke prestatievermindering oplevert op basis van standaardstatistieken', en dat neurale netwerken misschien niet zo veerkrachtig zijn tegen dergelijke verstoringen als eerder werk. suggereert.

Een foto van een hond uit de MobileNetV2018-dataset van 2. Bij kwaliteit 10 (links) slaagt een classificatiesysteem er niet in om het juiste ras 'Pembroke Welsh Corgi' te identificeren, in plaats daarvan raadt het 'Norwich terrier' (het systeem weet al dat dit een foto van een hond is, maar niet het ras); tweede van links, een kant-en-klare JPEG-artefact-gecorrigeerde versie van de afbeelding slaagt er opnieuw niet in om het juiste ras te identificeren; tweede van rechts, gerichte artefactcorrectie herstelt de juiste classificatie; en rechts, de originele foto, correct geclassificeerd. Bron: https://arxiv.org/pdf/2011.08932.pdf
Compressie-artefacten als 'gegevens'
Extreme JPEG-compressie creëert waarschijnlijk zichtbare of halfzichtbare randen rond de 8×8 blokken waaruit een JPEG wordt samengevoegd tot een pixelraster. Zodra deze blokkerende of 'rinkelende' artefacten verschijnen, zullen ze waarschijnlijk door machine learning-systemen verkeerd worden geïnterpreteerd als elementen uit de echte wereld van het onderwerp van de afbeelding, tenzij hiervoor enige compensatie wordt geboden.

Hierboven haalt een computer vision machine learning-systeem een 'schone' gradiëntafbeelding uit een afbeelding van goede kwaliteit. Hieronder 'blokkeren' artefacten in een afbeelding van lagere kwaliteit die de kenmerken van het onderwerp verdoezelen, en kunnen uiteindelijk de kenmerken 'infecteren' die zijn afgeleid van een afbeeldingsset, met name in gevallen waarin afbeeldingen van hoge en lage kwaliteit voorkomen in de gegevensset , zoals in web-geschraapte collecties waarop alleen generieke gegevensopschoning is toegepast. Bron: http://www.cs.utep.edu/ofuentes/papers/quijasfuentes2014.pdf
Zoals te zien is in de eerste afbeelding hierboven, kunnen dergelijke artefacten van invloed zijn op beeldclassificatietaken, met implicaties ook voor tekstherkenningsalgoritmen, die mogelijk niet in staat zijn om door artefacten aangetaste karakters correct te identificeren.
In het geval van trainingssystemen voor beeldsynthese (zoals deepfake-software of op GAN gebaseerde systemen voor het genereren van afbeeldingen), kan een 'schurkenstaat'-blok met sterk gecomprimeerde afbeeldingen van lage kwaliteit in een dataset ofwel de mediane reproductiekwaliteit naar beneden halen, of anders worden ondergebracht en in wezen worden overschreven door een groter aantal functies van hogere kwaliteit die worden geëxtraheerd uit betere afbeeldingen in de set. In beide gevallen zijn betere gegevens wenselijk – of in ieder geval consistente gegevens.
JPEG - Meestal 'goed genoeg'
JPEG-compressie is een onomkeerbare codec met verlies die kan worden toegepast op verschillende afbeeldingsindelingen, hoewel deze voornamelijk wordt toegepast op het JFIF-afbeeldingsbestand wikkel. Desondanks is het JPEG-formaat (.jpg) vernoemd naar de bijbehorende compressiemethode, en niet naar de JFIF-wrapper voor de afbeeldingsgegevens.
In de afgelopen jaren zijn complete machine learning-architecturen ontstaan die artefactbeperking in JPEG-stijl omvatten als onderdeel van AI-gestuurde opschalings-/herstelroutines, en op AI gebaseerde verwijdering van compressie-artefacten is nu opgenomen in een aantal commerciële producten, zoals de Topaz-afbeelding/ video suiteEn neurale kenmerken van recente versies van Adobe Photoshop.
Aangezien de 1986 Het JPEG-schema dat momenteel algemeen wordt gebruikt, was in het begin van de jaren negentig vrijwel vergrendeld, het is niet mogelijk om metagegevens aan een afbeelding toe te voegen die aangeven op welk kwaliteitsniveau (1990-1) een JPEG-afbeelding is opgeslagen - tenminste, niet zonder wijzigingen aan te brengen dertig jaar verouderde consumenten-, professionele en academische softwaresystemen die niet verwachtten dat dergelijke metadata beschikbaar zouden zijn.
Bijgevolg is het niet ongebruikelijk om machine learning-trainingsroutines af te stemmen op de geëvalueerde of bekende kwaliteit van JPEG-beeldgegevens, zoals de onderzoekers hebben gedaan voor het nieuwe artikel (zie hieronder). Bij gebrek aan een metadata-invoer van 'kwaliteit', is het momenteel noodzakelijk om de details te kennen van hoe de afbeelding is gecomprimeerd (dwz gecomprimeerd vanuit een bron zonder verlies), of om de kwaliteit te schatten door middel van perceptuele algoritmen of handmatige classificatie.
Een economisch compromis
JPEG is niet de enige lossy compressiemethode die de kwaliteit van machine learning datasets kan beïnvloeden; compressie-instellingen in PDF-bestanden kunnen op deze manier ook informatie weggooien en op zeer lage kwaliteitsniveaus worden ingesteld om schijfruimte te besparen voor lokale of netwerkarchiveringsdoeleinden.
Dit blijkt uit verschillende pdf's op archive.org, waarvan sommige zo sterk zijn gecomprimeerd dat ze een behoorlijke uitdaging vormen voor beeld- of tekstherkenningssystemen. In veel gevallen, zoals bij boeken waarop auteursrechten rusten, lijkt deze intense compressie te zijn toegepast als een vorm van goedkope DRM, net zoals auteursrechthouders ervoor kunnen kiezen om de resolutie van door gebruikers geüploade YouTube-video's waarvan zij het IP-adres hebben, te verlagen. de 'blokkerige' video's achterlaten als promotionele tokens om 'full res'-aankopen te stimuleren, in plaats van ze te laten verwijderen.
In veel andere gevallen is de resolutie of beeldkwaliteit laag, simpelweg omdat de gegevens erg oud zijn en afkomstig zijn uit een tijdperk waarin lokale opslag en netwerkopslag duurder waren, en toen beperkte netwerksnelheden de voorkeur gaven aan sterk geoptimaliseerde en draagbare beelden boven reproductie van hoge kwaliteit. .
Er is beweerd dat JPEG, hoewel niet de beste oplossing nu, is 'verankerd' als onverwijderbare verouderde infrastructuur die in wezen verweven is met de fundamenten van het internet.
Legacy last
Hoewel latere innovaties zoals JPEG 2000, PNG en (meest recentelijk) het .webp-formaat superieure kwaliteit bieden, zou het opnieuw bemonsteren van oudere, zeer populaire datasets voor machine learning aantoonbaar de continuïteit en geschiedenis van jaarlijkse uitdagingen op het gebied van computervisie 'resetten' in de academische gemeenschap - een belemmering die ook zou gelden in het geval van het opnieuw opslaan van PNG-gegevenssetafbeeldingen met hogere kwaliteitsinstellingen. Dit kan worden beschouwd als een soort technische schuld.
Hoewel eerbiedwaardige servergestuurde beeldverwerkingsbibliotheken zoals ImageMagick betere formaten ondersteunen, waaronder .webp, komen er vaak vereisten voor beeldtransformatie voor in verouderde systemen die niet zijn ingesteld voor iets anders dan JPG of PNG (wat compressie zonder verlies biedt, maar ten koste van latentie en schijfruimte). Zelfs WordPress, de drijvende kracht achter het CMS bijna 40% van alle websites, alleen .webp-ondersteuning toegevoegd drie maanden geleden.
PNG was een late (misschien wel te late) intrede in de beeldformaatsector, ontstaan als een open source-oplossing in het laatste deel van de jaren 1990 als reactie op een verklaring uit 1995 door Unisys en CompuServe dat er voortaan royalty's betaald zouden moeten worden op het LZW-compressieformaat dat gebruikt wordt in GIF-bestanden, die destijds algemeen werden gebruikt voor logo's en egale kleurelementen, zelfs als het formaat verrijzenis in de vroege jaren 2010 gericht op het vermogen om korte bandbreedte, pittige geanimeerde inhoud te bieden (ironisch genoeg hebben geanimeerde PNG's nooit aan populariteit of brede steun gewonnen, en werden ze zelfs verbannen van Twitter in 2019).
Ondanks de tekortkomingen is JPEG-compressie snel, ruimtebesparend en diep ingebed in alle soorten systemen - en zal daarom waarschijnlijk niet volledig verdwijnen uit de machine learning-scene in de nabije toekomst.
Het beste uit de AI/JPEG-ontspanning halen
Tot op zekere hoogte heeft de machine learning-gemeenschap zich aangepast aan de zwakheden van JPEG-compressie: in 2011 publiceerde de European Society of Radiology (ESR) een studies over de 'Bruikbaarheid van onomkeerbare beeldcompressie bij radiologische beeldvorming', met richtlijnen voor 'aanvaardbaar' verlies; wanneer de eerbiedwaardige MNIST tekstherkenningsdataset (waarvan de beeldgegevens oorspronkelijk in een nieuw binair formaat werden aangeleverd) werd overgezet naar een 'normaal' beeldformaat, JPEG, niet PNG, was gekozen; en een eerdere (2020) samenwerking van de auteurs van het nieuwe artikel aangeboden 'een nieuwe architectuur' voor het kalibreren van machine learning-systemen voor de tekortkomingen van variërende JPEG-beeldkwaliteit, zonder dat modellen hoeven te worden getraind in elke JPEG-kwaliteitsinstelling - een functie die in het nieuwe werk wordt gebruikt.
Onderzoek naar het nut van kwaliteitsafhankelijke JPEG-gegevens is inderdaad een relatief bloeiend veld in machine learning. Een (niet-gerelateerd) project uit 2016 van het Center for Automation Research aan de Universiteit van Maryland eigenlijk concentreert zich op het DCT-domein (waar JPEG-artefacten optreden bij lage kwaliteitsinstellingen) als een route naar diepe feature-extractie; een ander project uit 2019 concentreert zich op lezen op byteniveau van JPEG-gegevens zonder de tijdrovende noodzaak om de afbeeldingen daadwerkelijk te decomprimeren (dwz ze ergens in een geautomatiseerde workflow te openen); en een studies uit Frankrijk in 2019 maakt actief gebruik van JPEG-compressie ten dienste van objectherkenningsroutines.
Testen en conclusies
Om terug te komen op het laatste onderzoek van UoM en Facebook: de onderzoekers probeerden de begrijpelijkheid en bruikbaarheid van JPEG te testen op afbeeldingen die zijn gecomprimeerd tussen 10-90 (waaronder het beeld onmogelijk verstoord is en waarboven het gelijk is aan compressie zonder verlies). Afbeeldingen die in de tests werden gebruikt, werden vooraf gecomprimeerd bij elke waarde binnen het beoogde kwaliteitsbereik, wat ten minste acht trainingssessies omvatte.
Modellen werden getraind op stochastische gradiëntafdaling via vier methoden: basislijn, waar geen aanvullende maatregelen zijn toegevoegd; begeleide finetuning, waar de trainingsset het voordeel heeft van vooraf getrainde gewichten en gelabelde gegevens (hoewel de onderzoekers toegeven dat dit moeilijk te repliceren is in toepassingen op consumentenniveau); artefact correctie, waarbij voorafgaand aan de training augmentatie/verbetering wordt uitgevoerd op de gecomprimeerde beelden; En taakgerichte artefactcorrectie, waar het artefact-correcte netwerk wordt verfijnd op geretourneerde fouten.
De training vond plaats op een grote verscheidenheid aan apt-datasets, waaronder meerdere varianten van ResNet, SnelRCNN, MobielNetV2, maskerRCNN en Keras' AanvangV3.
Resultaten van monsterverlies na taakgerichte artefactcorrectie worden hieronder gevisualiseerd (lager = beter).
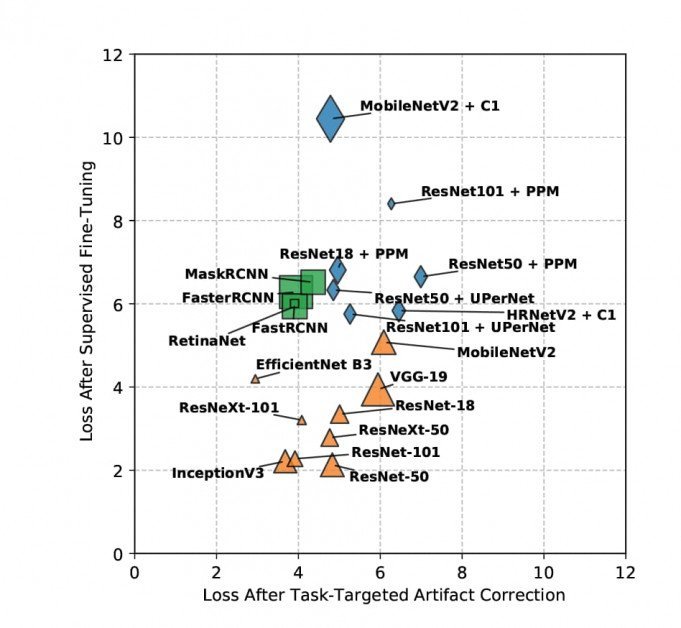
Het is niet mogelijk om diep in de details van de resultaten van het onderzoek te duiken, omdat de bevindingen van de onderzoekers verdeeld zijn tussen het doel om JPEG-artefacten te evalueren en nieuwe methoden om dit te verlichten; de training werd herhaald per kwaliteit over zoveel datasets; en de taken omvatten meerdere doelen, zoals objectdetectie, segmentatie en classificatie. In wezen positioneert het nieuwe rapport zichzelf als een alomvattend naslagwerk waarin meerdere kwesties worden behandeld.
Desalniettemin concludeert de krant in grote lijnen dat 'JPEG-compressie over de hele linie een forse straf heeft voor zware tot matige compressie-instellingen'. Het beweert ook dat zijn nieuwe niet-gelabelde mitigatiestrategieën superieure resultaten opleveren ten opzichte van andere vergelijkbare benaderingen; dat de begeleide methode van de onderzoekers voor complexe taken ook beter presteert dan die van zijn collega's, ondanks dat hij geen toegang heeft tot grondwaarheidslabels; en dat deze nieuwe methodologieën hergebruik van modellen mogelijk maken, aangezien de verkregen gewichten overdraagbaar zijn tussen taken.
In termen van classificatietaken stelt de paper expliciet dat 'JPEG zowel de gradiëntkwaliteit verslechtert als lokalisatiefouten veroorzaakt'.
De auteurs hopen toekomstige studies uit te breiden naar andere compressiemethoden, zoals de grotendeels genegeerde JPEG 2000, evenals WebP, heif en BPG. Ze suggereren verder dat hun methodologie zou kunnen worden toegepast op analoog onderzoek naar algoritmen voor videocompressie.
Omdat de taakgerichte artefactcorrectiemethode zo succesvol is gebleken in het onderzoek, geven de auteurs ook aan dat ze van plan zijn de tijdens het project getrainde gewichten vrij te geven, in de verwachting dat '[veel] toepassingen baat zullen hebben bij het gebruik van onze TTAC-gewichten zonder aanpassingen'.
nb Bronafbeelding voor het artikel is afkomstig van thispersondoesnotexist.com













