Kunstmatige intelligentie
Revolutie in de gezondheidszorg: het onderzoeken van de impact en de toekomst van grote taalmodellen in de geneeskunde

De integratie en toepassing van grote taalmodellen (LLM’s) in de geneeskunde en de gezondheidszorg is een onderwerp van significant interesse en ontwikkeling.
Zoals vermeld in de Healthcare Information Management and Systems Society wereldconferentie en andere opvallende evenementen, zijn bedrijven zoals Google leidende figuren in het onderzoeken van het potentieel van generatieve AI binnen de gezondheidszorg. Hun initiatieven, zoals Med-PaLM 2, benadrukken de evoluerende landschap van AI-gedreven gezondheidsoplossingen, met name op gebieden zoals diagnostiek, patiëntenzorg en administratieve efficiëntie.
Google’s Med-PaLM 2, een pionierende LLM in de gezondheidsdomein, heeft indrukwekkende capaciteiten getoond, met name door het bereiken van een “expert”-niveau in vragen in de stijl van het Amerikaanse medische licentie-examen. Dit model, en anderen zoals het, beloven de manier waarop gezondheidsprofessionals toegang hebben tot en gebruikmaken van informatie te revolutioneren, waardoor diagnostische nauwkeurigheid en patiëntenzorg-efficiëntie mogelijk worden verbeterd.
Echter, naast deze vooruitgang, zijn er bezorgdheden geuit over de praktische toepasbaarheid en veiligheid van deze technologieën in klinische omgevingen. Zo kan de afhankelijkheid van uitgebreide internetgegevensbronnen voor modeltraining, hoewel gunstig in sommige contexten, niet altijd geschikt of betrouwbaar zijn voor medische doeleinden. Zo stelt Nigam Shah, PhD, MBBS, Chief Data Scientist voor Stanford Health Care, dat de cruciale vragen die gesteld moeten worden, gaan over de prestaties van deze modellen in reële medische omgevingen en hun daadwerkelijke impact op patiëntenzorg en gezondheidsefficiëntie.
Dr. Shah’s perspectief benadrukt de noodzaak van een meer gerichte aanpak voor het gebruik van LLM’s in de geneeskunde. In plaats van algemene modellen getraind op brede internetgegevens, stelt hij een meer gefocuste strategie voor waarbij modellen getraind worden op specifieke, relevante medische gegevens. Deze aanpak lijkt op het trainen van een medische stagiair – hen voorzien van specifieke taken, hun prestaties controleren en hen langzaam meer autonomie geven naarmate ze competentie tonen.
In overeenstemming hiermee presenteert de ontwikkeling van Meditron door EPFL-onderzoekers een interessante vooruitgang in het veld. Meditron, een open-source LLM specifiek ontworpen voor medische toepassingen, vertegenwoordigt een significante stap voorwaarts. Getraind op gecureerde medische gegevens uit betrouwbare bronnen zoals PubMed en klinische richtlijnen, biedt Meditron een meer gefocuste en potentieel meer betrouwbare tool voor medische praktijnen. De open-source aard ervan bevordert niet alleen transparantie en samenwerking, maar staat ook toe voor continue verbetering en stress testing door de bredere onderzoekscommunity.

MEDITRON-70B-achieves-an-accuracy-of-70.2-on-USMLE-style-questions-in-the-MedQA-4-options-dataset
De ontwikkeling van tools zoals Meditron, Med-PaLM 2 en anderen weerspiegelt een groeiend besef van de unieke eisen van de gezondheidszorgsector wat betreft AI-toepassingen. De nadruk op het trainen van deze modellen op relevante, hoogwaardige medische gegevens en het waarborgen van hun veiligheid en betrouwbaarheid in klinische omgevingen is zeer cruciaal.
Bovendien toont de opname van diverse datasets, zoals die uit humanitaire contexten zoals het Internationale Rode Kruis, een gevoeligheid voor de uiteenlopende behoeften en uitdagingen in de mondiale gezondheidszorg. Deze aanpak staat in overeenstemming met de bredere missie van veel AI-onderzoekscentra, die ernaar streven AI-tools te creëren die niet alleen technisch geavanceerd zijn, maar ook sociaal verantwoord en nuttig.
Het artikel met de titel “Large language models encode clinical knowledge” dat onlangs in Nature is gepubliceerd, onderzoekt hoe grote taalmodellen (LLM’s) effectief kunnen worden gebruikt in klinische omgevingen. Het onderzoek presenteert baanbrekende inzichten en methoden, en werpt licht op de capaciteiten en beperkingen van LLM’s in de medische domein.
De medische domein wordt gekenmerkt door zijn complexiteit, met een uitgebreid scala aan symptomen, ziekten en behandelingen die constant evolueren. LLM’s moeten niet alleen deze complexiteit begrijpen, maar ook up-to-date blijven met de laatste medische kennis en richtlijnen.
Het kernonderzoek draait om een nieuw gecreëerd benchmark genaamd MultiMedQA. Deze benchmark combineert zes bestaande medische vraag-en-antwoord-datasets met een nieuwe dataset, HealthSearchQA, die bestaat uit medische vragen die vaak online worden gezocht. Deze uitgebreide aanpak heeft tot doel LLM’s te evalueren over verschillende dimensies, waaronder feitelijkheid, begrip, redenering, mogelijke schade en vooroordeel, en zo de beperkingen van eerdere geautomatiseerde evaluaties aan te pakken die waren gebaseerd op beperkte benchmarks.
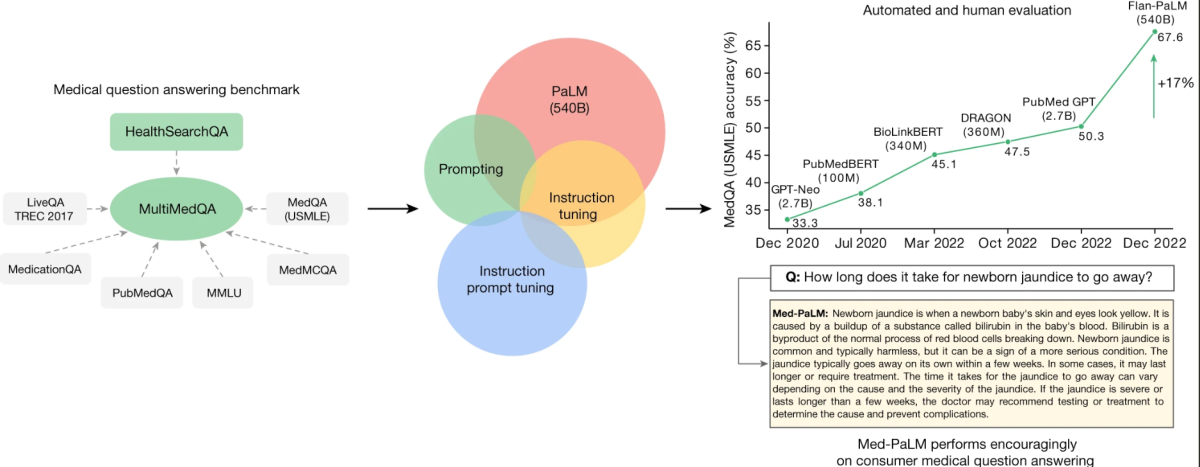
MultiMedQA, a benchmark for answering medical questions spanning medical exam
Een sleutelaspect van deze studie is de evaluatie van het Pathways Language Model (PaLM), een 540-miljard parameter LLM, en zijn instructie-gefinetuneerde variant, Flan-PaLM, op de MultiMedQA. Opmerkelijk is dat Flan-PaLM een state-of-the-art nauwkeurigheid bereikt op alle multiple-choice datasets binnen MultiMedQA, waaronder een nauwkeurigheid van 67,6% op MedQA, die bestaat uit vragen in de stijl van het Amerikaanse medische licentie-examen. Deze prestatie markeert een significante verbetering ten opzichte van eerdere modellen, en overtreft het vorige state-of-the-art met meer dan 17%.
MedQA
De MedQA-dataset3 bevat vragen in de stijl van het Amerikaanse medische licentie-examen, elk met vier of vijf antwoordopties. Het bevat een ontwikkelingsset met 11.450 vragen en een testset met 1.273 vragen.
Formaat: vraag en antwoord (Q + A), multiple choice, open domein.
Voorbeeldvraag: Een 65-jarige man met hypertensie komt bij de arts voor een routineonderzoek. Hij gebruikt momenteel atenolol, lisinopril en atorvastatine. Zijn pols is 86 min-1, ademhalingen zijn 18 min-1 en bloeddruk is 145/95 mmHg. Het cardiologisch onderzoek onthult een einddiastolisch murmel. Wat is de meest waarschijnlijke oorzaak van deze fysieke onderzoeksbevinding?
Antwoorden (correct antwoord in vet): (A) Verminderde compliantie van de linkerventrikel, (B) Myxomateuze degeneratie van de mitraliskleppen (C) Ontsteking van het pericard (D) Dilatatie van de aortawortel (E) Verdikking van de mitraliskleppen.
Het onderzoek identificeert ook kritieke hiaten in de prestaties van het model, met name bij het beantwoorden van consumentenmedische vragen. Om deze problemen aan te pakken, introduceren de onderzoekers een methode genaamd instructiepromptfinetuning. Deze techniek aligneert LLM’s efficiënt met nieuwe domeinen met behulp van enkele voorbeelden, waardoor Med-PaLM ontstaat. Het Med-PaLM-model, hoewel het bemoedigende resultaten laat zien en verbetering toont in begrip, kennisopname en redenering, blijft nog steeds achter bij clinici.
Een opvallend aspect van dit onderzoek is het gedetailleerde kader voor humane evaluatie. Dit kader beoordeelt de antwoorden van de modellen op overeenstemming met wetenschappelijke consensus en potentieel schadelijke uitkomsten. Zo stemden slechts 61,9% van Flan-PaLM’s lange antwoorden overeen met wetenschappelijke consensus, maar dit cijfer steeg tot 92,6% voor Med-PaLM, vergelijkbaar met antwoorden gegenereerd door clinici. Evenzo werd het potentieel voor schadelijke uitkomsten aanzienlijk verlaagd in Med-PaLM’s antwoorden in vergelijking met Flan-PaLM.
De humane evaluatie van Med-PaLM’s antwoorden benadrukte zijn vaardigheid in verschillende gebieden, die dicht aansluiten bij antwoorden gegenereerd door clinici. Dit onderstreept Med-PaLM’s potentieel als ondersteunend instrument in klinische omgevingen.
Het onderzoek dat hierboven wordt besproken, gaat in op de nuances van het verbeteren van Large Language Models (LLM’s) voor medische toepassingen. De technieken en observaties uit deze studie kunnen worden gegeneraliseerd om de capaciteiten van LLM’s in verschillende domeinen te verbeteren. Laten we deze belangrijke aspecten onderzoeken:
Instructietuning verbetert prestaties
- Algemene toepassing: Instructietuning, die het fijnafstemmen van LLM’s met specifieke instructies of richtlijnen inhoudt, heeft aangetoond dat het de prestaties aanzienlijk kan verbeteren over verschillende domeinen. Deze techniek kan worden toegepast in andere gebieden zoals juridisch, financieel of onderwijs om de nauwkeurigheid en relevantie van LLM-uitvoer te verbeteren.
Schaalmodelgrootte
- Brede implicaties: De observatie dat het schalen van de modelgrootte de prestaties verbetert, is niet beperkt tot medische vraagbeantwoording. Grotere modellen, met meer parameters, hebben de capaciteit om meer nuances en complexe antwoorden te verwerken en te genereren. Dit schalen kan gunstig zijn in domeinen zoals klantenservice, creatief schrijven en technische ondersteuning, waar nuances begrip en antwoordgeneratie cruciaal zijn.
Chain of Thought (COT) prompting
- Uiteenlopende domeintoepassing: Het gebruik van COT-prompting, hoewel het niet altijd de prestaties in medische datasets verbetert, kan waardevol zijn in andere domeinen waar complex probleemoplossing vereist is. Bijvoorbeeld in technische storingen of complexe besluitvormingsscenario’s, kan COT-prompting LLM’s leiden om informatie stap voor stap te verwerken, wat leidt tot meer accurate en gerede uitvoer.
Zelfconsistentie voor verbeterde nauwkeurigheid
- Brede toepassing: De techniek van zelfconsistentie, waarbij meerdere uitvoer wordt gegenereerd en het meest consistente antwoord wordt geselecteerd, kan de prestaties aanzienlijk verbeteren in verschillende gebieden. In domeinen zoals financiën of juridisch, waar nauwkeurigheid van het grootste belang is, kan deze methode worden gebruikt om gegenereerde uitvoer te cross-verifiëren voor een hogere betrouwbaarheid.
Onzekerheid en selectieve voorspelling
- Overkoepelende relevantie: Het communiceren van onzekerheidschattingen is cruciaal in domeinen waar misinformatie ernstige gevolgen kan hebben, zoals gezondheidszorg en recht. Het gebruik van LLM’s om onzekerheid uit te drukken en selectief te definiëren wanneer het vertrouwen laag is, kan een cruciaal instrument zijn in deze domeinen om de verspreiding van onnauwkeurige informatie te voorkomen.
De reële toepassing van deze modellen gaat verder dan het beantwoorden van vragen. Ze kunnen worden gebruikt voor patiënteneducatie, bijstaan bij diagnostische processen en zelfs bij het trainen van medische studenten. Echter, hun inzet moet zorgvuldig worden beheerd om te voorkomen dat men te veel vertrouwt op AI zonder adequate menselijke toezicht.
Naarmate de medische kennis evolueert, moeten LLM’s ook aanpassen en leren. Dit vereist mechanismen voor continue leren en updaten, om ervoor te zorgen dat de modellen relevant en nauwkeurig blijven over tijd.












