Kunstmatige intelligentie
Hoe Stable Diffusion zich kan ontwikkelen als een mainstream consumentenproduct

Ironicamente, Stable Diffusion, het nieuwe AI-afbeeldingssyntheseframework dat de wereld teistert, is noch stabiel noch echt “gediffundeerd” – tenminste, nog niet.
De volledige reeks van de mogelijkheden van het systeem zijn verspreid over een wisselend aanbod van constant muterende aanbiedingen van een handvol ontwikkelaars die wanhopig de laatste informatie en theorieën uitwisselen in diverse colloquies op Discord – en de meeste installatieprocedures voor de pakketten die ze creëren of modificeren zijn verre van ‘plug and play’.
In plaats daarvan vereisen ze meestal een command-line of BAT-gestuurde installatie via GIT, Conda, Python, Miniconda en andere bleeding-edge ontwikkelingsframeworks – softwarepakketten die zo zeldzaam zijn onder de algemene consumenten dat hun installatie vaak wordt gemarkeerd door antivirus- en anti-malwareleveranciers als bewijs van een gecompromitteerd hostsysteem.

Alleen een kleine selectie van de stadia in de hindernisbaan die de standaard Stable Diffusion-installatie momenteel vereist. Veel van de distributies vereisen ook specifieke versies van Python, die in conflict kunnen komen met bestaande versies die op de machine van de gebruiker zijn geïnstalleerd – hoewel dit kan worden verholpen met Docker-gebaseerde installaties en, in zekere mate, door het gebruik van Conda-omgevingen.
Berichten in zowel de SFW- als de NSFW-Stable Diffusion-gemeenschappen worden overspoeld met tips en trucs met betrekking tot het hacken van Python-scripts en standaardinstallaties, om verbeterde functionaliteit te ermöglichen of om frequente afhankelijkheidsfouten en een reeks andere problemen op te lossen.
Dit laat de gemiddelde consument, geïnteresseerd in het creëren van geweldige afbeeldingen vanuit tekstprompts, grotendeels aan de genade van het groeiende aantal gemonetiseerde API-webinterfaces, waarvan de meeste een minimaal aantal gratis afbeeldingengeneraties bieden voordat ze het kopen van tokens vereisen.
Bovendien weigeren bijna alle van deze webgebaseerde aanbiedingen om NSFW-inhoud (veel waarvan mogelijk verband houdt met niet-pornografische onderwerpen van algemeen belang, zoals ‘oorlog’) uit te voeren, wat Stable Diffusion onderscheidt van de gezuiverde diensten van OpenAI’s DALL-E 2.
‘Photoshop voor Stable Diffusion’
Wat de bredere wereld naar verluidt verwacht, is ‘Photoshop voor Stable Diffusion’ – een cross-platform installabele applicatie die de beste en meest krachtige functionaliteit van Stability.ai’s architectuur combineert, evenals de verschillende ingenieuze innovaties van de opkomende SD-ontwikkelingsgemeenschap, zonder zwevende CLI-vensters, obscure en veranderende installatie- en update-routines, of ontbrekende functies.
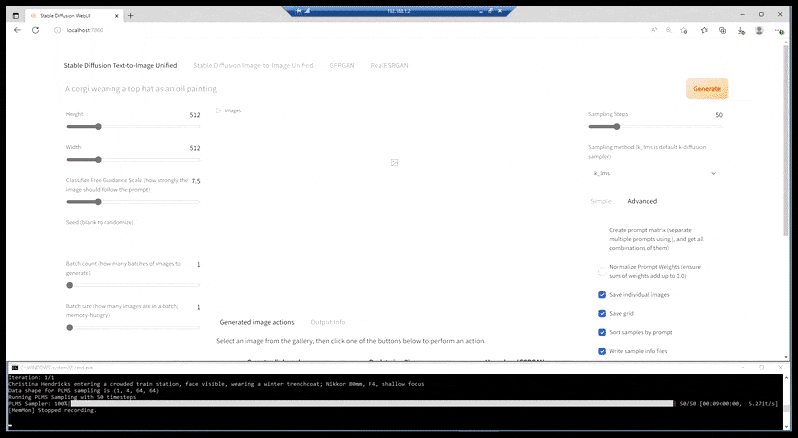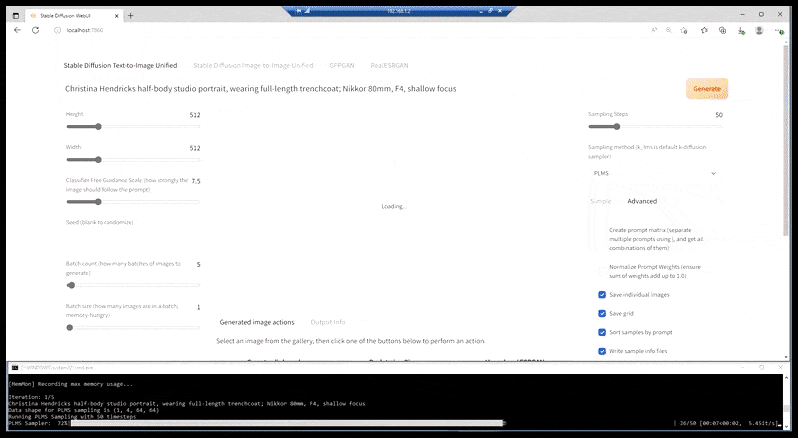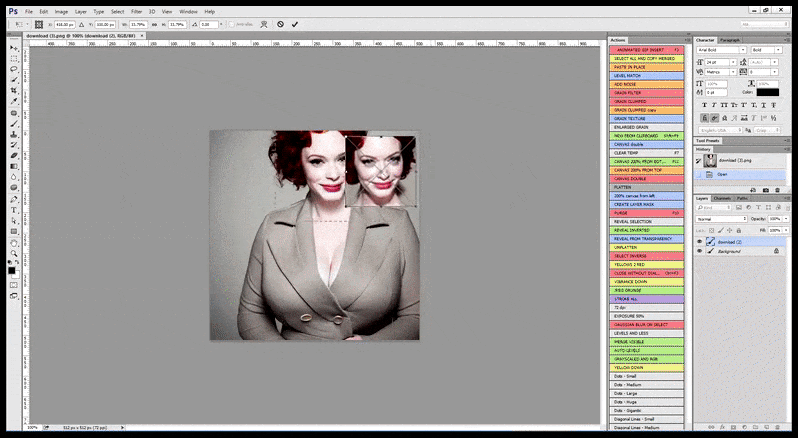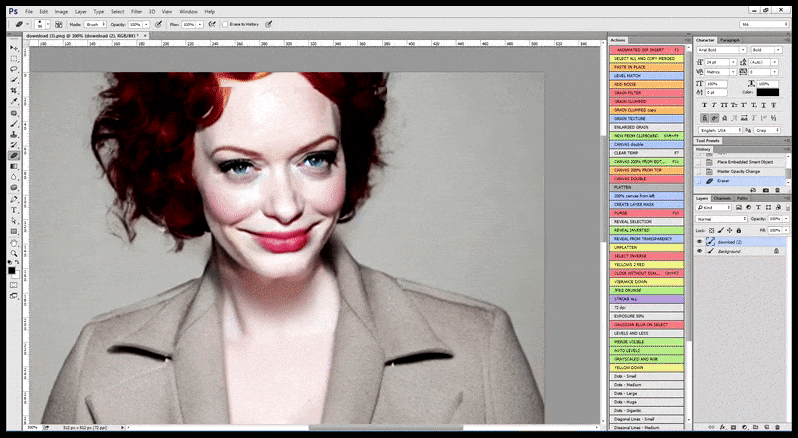
Wat we momenteel hebben, in de meeste capabele installaties, is een verschillend elegante webpagina met een losse command-line-venster, en waarvan de URL een localhost-poort is:

Soortgelijk aan CLI-gestuurde synthes apps zoals FaceSwap, en de BAT-georiënteerde DeepFaceLab, toont de ‘prepack’-installatie van Stable Diffusion zijn command-line-wortels, met de interface die toegankelijk is via een localhost-poort (zie bovenaan de afbeelding hierboven) die communiceert met de CLI-gebaseerde Stable Diffusion-functionaliteit.
Zonder twijfel komt er een meer gestroomlijnde applicatie. Er zijn al verschillende Patreon-gebaseerde integrale applicaties die kunnen worden gedownload, zoals GRisk en NMKD (zie afbeelding hieronder) – maar geen enkele die, tot nu toe, de volledige reeks functies integreren die sommige van de geavanceerdere en minder toegankelijke implementaties van Stable Diffusion kunnen bieden.

Vroege, Patreon-gebaseerde pakketten van Stable Diffusion, licht ‘ge-appt’. NMKD’s is de eerste die de CLI-uitvoer rechtstreeks in de GUI integreert.
Laten we eens kijken naar hoe een meer gepolijste en integrale implementatie van deze verbazingwekkende open source-marvel eruit kan zien – en welke uitdagingen het kan tegenkomen.
Rechtelijke overwegingen voor een volledig gefinancierde commerciële Stable Diffusion-toepassing
De NSFW-factor
De Stable Diffusion-broncode is vrijgegeven onder een extreem permissieve licentie die commerciële herimplementaties en afgeleide werken die uitgebreid zijn gebouwd vanuit de broncode, niet verbiedt.
Behalve de eerdergenoemde en groeiende aantal Patreon-gebaseerde Stable Diffusion-bouwsels, evenals het uitgebreide aantal applicatieplug-ins die worden ontwikkeld voor Figma, Krita, Photoshop, GIMP, en Blender (onder anderen), is er geen praktische reden waarom een goed gefinancierde softwareontwikkelingshuis niet een veel meer geavanceerde en capabele Stable Diffusion-toepassing kan ontwikkelen. Vanuit een marktperpectief is er elke reden om aan te nemen dat verschillende van dergelijke initiatieven al goed op weg zijn.
Hier staat zo’n inspanning onmiddellijk voor de dilemma of Stable Diffusion’s native NSFW-filter (een fragment van code), moet worden uitgeschakeld.
‘Begraven’ van de NSFW-schakelaar
Hoewel Stability.ai’s open source-licentie voor Stable Diffusion een breed interpreteerbare lijst van toepassingen bevat waarvoor het niet kan worden gebruikt (waaronder, naar alle waarschijnlijkheid, pornografische inhoud en deepfakes), is de enige manier waarop een leverancier dit soort gebruik effectief kan verbieden, door de NSFW-filter te compileren in een ondoorzichtige uitvoerbaar bestand in plaats van een parameter in een Python-bestand, of door een checksum-vergelijking af te dwingen op het Python-bestand of DLL dat de NSFW-richtlijn bevat, zodat renderingen niet kunnen plaatsvinden als gebruikers deze instelling wijzigen.
Dit zou de vermeende toepassing ‘gecastreerd’ achterlaten op een manier die vergelijkbaar is met hoe DALL-E 2 momenteel is, waardoor de commerciële aantrekkingskracht wordt vermindert. Bovendien zouden onvermijdelijk gecompileerde ‘gekloonde’ versies van deze componenten (ofwel originele Python-runtime-elementen of gecompileerde DLL-bestanden, zoals momenteel worden gebruikt in de Topaz-lijn van AI-afbeeldingsverbeteringstools) waarschijnlijk verschijnen in de torrent/hacking-gemeenschap om dergelijke beperkingen te omzeilen, door simpelweg de belemmerende elementen te vervangen en de checksum-eisen te negeren.
Uiteindelijk kan de leverancier ervoor kiezen om eenvoudigweg Stability.ai’s waarschuwing tegen misbruik te herhalen, die het eerste uitvoeren van veel huidige Stable Diffusion-distributies kenmerkt.
Echter, de kleine open source-ontwikkelaars die momenteel informele disclaimer gebruiken, hebben weinig te verliezen in vergelijking met een softwarebedrijf dat aanzienlijke hoeveelheden tijd en geld heeft geïnvesteerd in het maken van Stable Diffusion volledig functioneel en toegankelijk – wat dieper overleg nodig maakt.
Deepfake-aansprakelijkheid
Zoals we onlangs hebben opgemerkt, bevat de LAION-aesthetics-database, onderdeel van de 4,2 miljard afbeeldingen waarop de voortdurende modellen van Stable Diffusion zijn getraind, een groot aantal beroemdhedenafbeeldingen, waardoor gebruikers in staat zijn om effectief deepfakes te creëren, inclusief deepfake-beroemdhedenpornografie.

Uit ons recente artikel, vier stadia van Jennifer Connelly over vier decennia van haar carrière, afgeleid van Stable Diffusion.
Dit is een afzonderlijk en meer omstreden kwestie dan de generatie van (meestal) legale ‘abstracte’ pornografie, die geen ‘echte’ mensen afbeeldt (hoewel dergelijke afbeeldingen worden afgeleid van meerdere echte foto’s in de trainingsmaterialen).
Aangezien een toenemend aantal Amerikaanse staten en landen wetten tegen deepfake-pornografie ontwikkelen of hebben ingevoerd, kan de mogelijkheid van Stable Diffusion om deepfakes van beroemdheden te creëren betekenen dat een commerciële toepassing die niet geheel is gecensureerd (d.w.z. die pornografische materialen kan creëren) mogelijk enige vorm van filtering van vermeende beroemdhedengezichten nodig heeft.
Een methode kan zijn om een ingebouwd ‘zwarte lijst’ van termen te bieden die niet zullen worden geaccepteerd in een gebruikersprompt, met betrekking tot beroemdhedennamen en fictieve personages waarmee ze geassocieerd kunnen worden. Verondersteld wordt dat dergelijke instellingen zouden moeten worden ingesteld in meer talen dan alleen Engels, aangezien de oorspronkelijke gegevens andere talen bevatten. Een andere benadering kan zijn om beroemdhedenherkenningssystemen zoals die van Clarifai te integreren.
Het kan nodig zijn voor softwareproducenten om dergelijke methoden te integreren, mogelijk eerst uitgeschakeld, om te helpen voorkomen dat een volledig zelfstandige Stable Diffusion-toepassing beroemdhedengezichten genereert, in afwachting van nieuwe wetgeving die een dergelijke functionaliteit onwettig kan maken.
Nogmaals, een dergelijke functionaliteit kan onvermijdelijk worden gecompileerd en omgekeerd door geïnteresseerde partijen; echter kan de softwareproducent in dat geval beweren dat dit effectief ongeautoriseerde vandalisme is – zolang dit soort reverse-engineering niet te gemakkelijk wordt gemaakt.
Functies die kunnen worden opgenomen
De core-functionaliteit in elke distributie van Stable Diffusion zou verwacht worden van elke goed gefinancierde commerciële toepassing. Deze omvatten de mogelijkheid om tekstprompts te gebruiken om passende afbeeldingen te genereren (tekst-naar-afbeelding); de mogelijkheid om schetsen of andere afbeeldingen te gebruiken als richtlijnen voor gegenereerde afbeeldingen (afbeelding-naar-afbeelding); de middelen om aan te passen hoe ‘verbeeldingskrachtig’ het systeem is geïnstrueerd om te zijn; een manier om render tijd af te wegen tegen kwaliteit; en andere ‘basics’, zoals optionele automatische afbeelding/prompt-archivering, en routine optionele upscaling via RealESRGAN, en ten minste basis ‘face fixing’ met GFPGAN of CodeFormer.
Dat is een vrij ‘vanille’-installatie. Laten we eens kijken naar enkele van de geavanceerdere functies die momenteel worden ontwikkeld of uitgebreid, die kunnen worden geïntegreerd in een volledig uitgeruste ‘traditionele’ Stable Diffusion-toepassing.
Stochastische bevriezing
Zelfs als je een zaadje opnieuw gebruikt van een eerder geslaagde render, is het verschrikkelijk moeilijk om Stable Diffusion te laten herhalen van een transformatie als enig deel van de prompt of de bronafbeelding (of beide) is gewijzigd voor een latere render.
Dit is een probleem als je EbSynth wilt gebruiken om Stable Diffusion’s transformaties op te leggen op echte video op een temporeel coherente manier – hoewel de techniek zeer effectief kan zijn voor eenvoudige hoofd-en-schouderopnamen:

Beperkte beweging kan EbSynth een effectief medium maken om Stable Diffusion-transformaties om te zetten in realistische video. Bron: https://streamable.com/u0pgzd
EbSynth werkt door een kleine selectie van ‘gewijzigde’ sleutelkaders uit te breiden tot een video die is gerenderd in een reeks afbeeldingsbestanden (en die later opnieuw kan worden samengesteld tot een video).

In dit voorbeeld van de EbSynth-site, zijn een paar frames van een video op een artistieke manier geschilderd. EbSynth gebruikt deze frames als stijlgidsen om de hele video te wijzigen zodat deze overeenkomt met de geschilderde stijl. Bron: https://www.youtube.com/embed/eghGQtQhY38
In het onderstaande voorbeeld, dat vrijwel geen beweging vertoont van de (echte) blonde yogainstructrice links, heeft Stable Diffusion nog steeds moeite om een consistent gezicht te behouden, omdat de drie afbeeldingen die worden getransformeerd als ‘sleutelkaders’ niet helemaal identiek zijn, zelfs niet als ze allemaal hetzelfde numerieke zaadje delen.

Hier, zelfs met dezelfde prompt en zaadje voor alle drie transformaties, en zeer weinig veranderingen tussen de bronkaders, variëren de lichaamsspieren in grootte en vorm, maar belangrijker nog, het gezicht is inconsistent, waardoor temporele consistentie in een potentiële EbSynth-render wordt belemmerd.
Hoewel de SD/EbSynth-video hieronder zeer inventief is, waarbij de vingers van de gebruiker zijn getransformeerd in (respectievelijk) een wandelend paar broekspijpen en een eend, typeren de inconsistentie van de broek de problemen die Stable Diffusion heeft bij het behouden van consistentie over verschillende sleutelkaders, zelfs wanneer de bronkaders vergelijkbaar zijn met elkaar en het zaadje consistent is.

Een man zijn vingers worden een wandelende man en een eend, via Stable Diffusion en EbSynth. Bron: https://old.reddit.com/r/StableDiffusion/comments/x92itm/proof_of_concept_using_img2img_ebsynth_to_animate/
De gebruiker die deze video opmerkte dat de eendtransformatie, die naar alle waarschijnlijkheid het meest effectief was, slechts één getransformeerd sleutelkader vereiste, terwijl het nodig was om 50 Stable Diffusion-afbeeldingen te renderen om de wandelende broek te creëren, die meer temporele inconsistentie vertoont. De gebruiker merkte ook op dat het vijf pogingen kostte om consistentie te bereiken voor elk van de 50 sleutelkaders.
Daarom zou het een groot voordeel zijn voor een echt alomvattende Stable Diffusion-toepassing om functionaliteit te bieden die kenmerken maximaliseert over sleutelkaders.
Een mogelijkheid is dat de toepassing de gebruiker toelaat om de stochastische codering voor de transformatie op elk kader te ‘bevriezen’, wat momenteel alleen kan worden bereikt door de broncode handmatig te wijzigen. Zoals het onderstaande voorbeeld laat zien, helpt dit bij temporele consistentie, hoewel het zeker niet alle temporele problemen oplost:

Een Reddit-gebruiker transformeerde webcambeelden van zichzelf in verschillende beroemde mensen door niet alleen het zaadje te behouden (wat elke implementatie van Stable Diffusion kan doen), maar door ervoor te zorgen dat de stochastic_encode() parameter identiek was in elke transformatie. Dit werd bereikt door de code te wijzigen, maar kan gemakkelijk een gebruikers-toegankelijke schakelaar worden. Het is duidelijk dat dit echter niet alle temporele problemen oplost.
Cloud-gebaseerde tekstuele inversie
Een betere oplossing voor het oproepen van temporeel consistente personages en objecten is om ze ‘in te bakken’ in een tekstuele inversie – een 5KB-bestand dat kan worden getraind in een paar uur op basis van slechts vijf geannoteerde afbeeldingen, die vervolgens kunnen worden opgeroepen door een speciale ‘*’ prompt, waardoor een persistente verschijning van nieuwe personages mogelijk wordt voor opname in een verhaal.

Afbeeldingen die zijn geassocieerd met passende tags, kunnen worden omgezet in discrete entiteiten via tekstuele inversie, en worden opgeroepen zonder ambiguïteit, en in de juiste context en stijl, door speciale tokenwoorden. Bron: https://huggingface.co/docs/diffusers/training/text_inversion
Tekstuele inversies zijn aanvullende bestanden op het zeer grote en volledig getrainde model dat Stable Diffusion gebruikt, en worden effectief ‘ingesloten’ in het oproepen/promptproces, zodat ze kunnen deelnemen aan model-afgeleide scènes, en profiteren van het enorme database van kennis over objecten, stijlen, omgevingen en interacties van het model.
Echter, hoewel een tekstuele inversie niet lang duurt om te trainen, vereist het een grote hoeveelheid VRAM; volgens verschillende huidige walkthroughs, ergens tussen 12, 20 en zelfs 40GB.
Aangezien de meeste casual gebruikers waarschijnlijk niet over dat soort GPU-kracht beschikken, zijn cloudservices al in opkomst die deze bewerking zullen uitvoeren, waaronder een Hugging Face-versie. Hoewel er Google Colab-implementaties zijn die tekstuele inversies voor Stable Diffusion kunnen creëren, kunnen de vereiste VRAM en tijdsvereisten deze moeilijk maken voor gratis Colab-gebruikers.
Voor een potentieel volledig uitgeruste en goed geïnvesteerde Stable Diffusion-toepassing (geïnstalleerd) lijkt het doorsturen van deze zware taak naar de cloudservers van het bedrijf een voor de hand liggende monetarisatiestrategie (onder de voorwaarde dat een lage of kosteloze Stable Diffusion-toepassing doordringt van dergelijke niet-gratis functionaliteit, wat waarschijnlijk is in veel toepassingen die in de komende 6-9 maanden uit deze technologie zullen voortkomen).
Bovendien kan het vrij gecompliceerde proces van annoteren en formatteren van de ingediende afbeeldingen en tekst worden gebaat bij automatisering in een geïntegreerde omgeving. Het potentieel ‘verslavende’ aspect van het creëren van unieke elementen die kunnen verkennen en interageren met de uitgebreide werelden van Stable Diffusion, lijkt potentieel verslavend, zowel voor algemene enthousiasten als voor jongere gebruikers.
Veelzijdige prompt-gewicht
Er zijn veel huidige implementaties die de gebruiker toelaten om grotere nadruk te leggen op een deel van een lange tekstprompt, maar de instrumentatie varieert nogal tussen deze, en is vaak onhandig of niet-intuïtief.
De zeer populaire Stable Diffusion-fork van AUTOMATIC1111, bijvoorbeeld, kan de waarde van een promptwoord verlagen of verhogen door het te omvatten in enkele of meerdere haakjes (voor de-emfasering) of vierkante haakjes voor extra-emfasering.

Vierkante haakjes en/of haakjes kunnen uw ontbijt transformeren in deze versie van Stable Diffusion-prompt-gewichten, maar het is een cholesterol-nachtmerrie op welke manier dan ook.
Andere iteraties van Stable Diffusion gebruiken uitroeptekens voor de-emfasering, terwijl de meest veelzijdige gebruikers toelaten om gewichten toe te wijzen aan elk woord in de prompt via de GUI.
Het systeem zou ook negatieve prompt-gewichten moeten toelaten – niet alleen voor horror-fans, maar omdat er minder alarmerende en meer verheffende mysteries in Stable Diffusion’s latent space kunnen zijn dan onze beperkte taalgebruik kan oproepen.
Uitschilderen
Kort na de sensationele open-sourcing van Stable Diffusion, probeerde OpenAI – grotendeels tevergeefs – enige van zijn DALL-E 2-thunder terug te winnen door ‘uitschilderen’ aan te kondigen, waarmee een gebruiker een afbeelding kan uitbreiden buiten zijn grenzen met semantische logica en visuele coherentie.
Natuurlijk is dit sindsdien geïmplementeerd in verschillende vormen voor Stable Diffusion, evenals in Krita, en zou zeker moeten worden opgenomen in een alomvattende, Photoshop-achtige versie van Stable Diffusion.
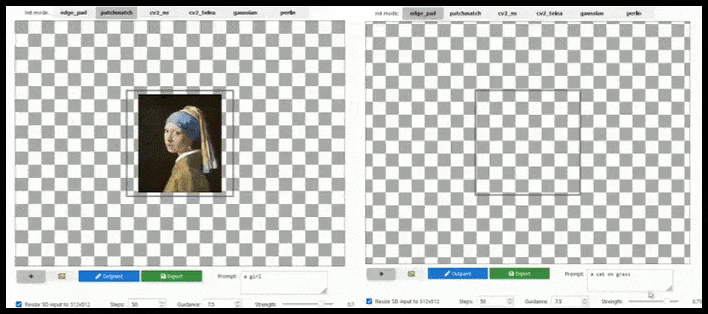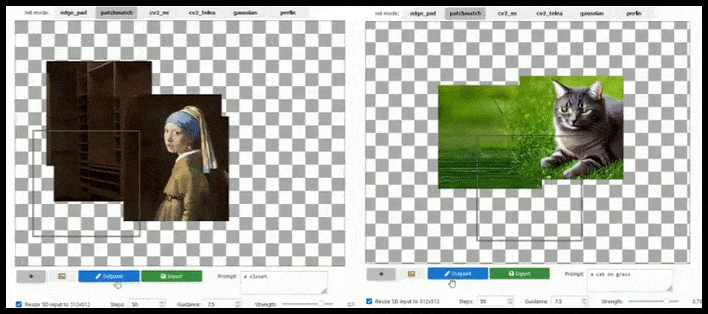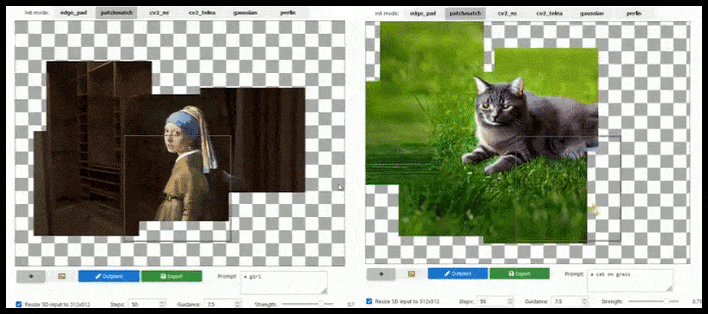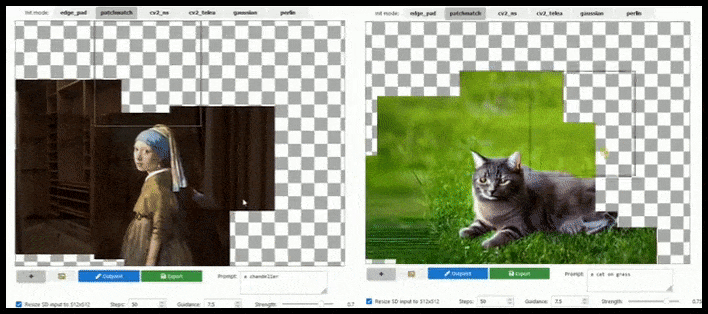
Tegel-gebaseerde augmentatie kan een standaard 512×512-render bijna oneindig uitbreiden, zolang de prompts, bestaande afbeelding en semantische logica dit toelaten. Bron: https://github.com/lkwq007/stablediffusion-infinity
Omdat Stable Diffusion is getraind op 512x512px-afbeeldingen (en om een aantal andere redenen), snijdt het vaak de hoofden (of andere essentiële lichaamsdelen) van menselijke onderwerpen af, zelfs waar de prompt duidelijk ‘hoofd-emfasering’ aangaf, enz..

Typische voorbeelden van Stable Diffusion ‘decapitatie’; maar uitschilderen kan George terug in het beeld brengen.
Elke uitschilderimplementatie van het type dat in de geanimeerde afbeelding hierboven wordt getoond (die uitsluitend is gebaseerd op Unix-bibliotheken, maar zou moeten kunnen worden gerepliceerd op Windows) zou ook moeten worden geïnstrumenteerd als een een-klik/prompt-oplossing voor dit probleem.
Momenteel breiden veel gebruikers het canvas van ‘gedecapiteerde’ afbeeldingen uit naar boven, vullen ze de hoofdgebieden ongeveer in, en gebruiken ze img2img om de mislukte render te voltooien.
Effectieve masking die context begrijpt
Masking kan een verschrikkelijk hit-and-miss-aangelegenheid zijn in Stable Diffusion, afhankelijk van de fork of versie in kwestie. Vaak, waar het mogelijk is om een coherente masker te tekenen, eindigt het geselecteerde gebied met inhoud die niet de hele context van de afbeelding in overweging neemt.
Op één gelegenheid maskerde ik de cornea’s van een gezichtsafbeelding en gaf ik de prompt ‘blauwe ogen’ als een masker-inpaint – alleen om te ontdekken dat ik door twee uitgesneden menselijke ogen keek naar een afbeelding van een onwerkelijk uitziende wolf. Ik denk dat ik geluk heb dat het niet Frank Sinatra was.
Semantische bewerking is ook mogelijk door het identificeren van de ruis die de afbeelding heeft gegenereerd, waardoor de gebruiker specifieke structurele elementen in een render kan aanspreken zonder de rest van de afbeelding te verstoren:

Het wijzigen van één element in een afbeelding zonder traditionele masking en zonder aangrenzende inhoud te wijzigen, door het identificeren van de ruis die de afbeelding oorspronkelijk heeft gegenereerd en het aanspreken van de delen ervan die hebben bijgedragen aan het doelgebied. Bron: https://old.reddit.com/r/StableDiffusion/comments/xboy90/a_better_way_of_doing_img2img_by_finding_the/
Deze methode is gebaseerd op de K-Diffusion-sampler.
Semantische filters voor fysiologische fouten
Zoals we eerder hebben vermeld, kan Stable Diffusion vaak ledematen toevoegen of verwijderen, grotendeels vanwege gegevensproblemen en tekortkomingen in de annotaties die de afbeeldingen begeleiden die het hebben getraind.

Net als dat ondeugende kind dat zijn tong uitsteekt in de schoolgroepsfoto, zijn de biologische gruweldaden van Stable Diffusion niet altijd onmiddellijk duidelijk, en u kunt uw laatste AI-meesterwerk op Instagram hebben gezet voordat u de extra handen of gesmolten ledematen opmerkt.
Het is zo moeilijk om deze soorten fouten te corrigeren dat het nuttig zou zijn als een volledig uitgeruste Stable Diffusion-toepassing een soort anatomische herkenningssysteem zou bevatten dat semantische segmentatie gebruikt om te berekenen of de binnenkomende afbeelding ernstige anatomische tekortkomingen vertoont (zoals in de afbeelding hierboven), en deze verwerpt ten gunste van een nieuwe render voordat deze aan de gebruiker wordt gepresenteerd.

Natuurlijk kunt u de godin Kali, of Doctor Octopus, of zelfs een onbeïnvloed deel van een ledemaat-geplaagde afbeelding willen renderen, dus deze functie zou een optionele schakelaar moeten zijn.
Als gebruikers het telemetry-aspect kunnen tolereren, kunnen dergelijke misfires zelfs anoniem worden doorgegeven in een collectieve inspanning van federatief leren dat kan helpen bij het verbeteren van toekomstige modellen en hun begrip van anatomische logica.
LAION-gebaseerde automatische gezichtsverbetering
Zoals ik in mijn eerder onderzoek naar drie dingen die Stable Diffusion in de toekomst kan aanpakken, heb ik opgemerkt, zou het niet alleen aan GFPGAN moeten worden overgelaten om gegenereerde gezichten in eerste instantie te ‘verbeteren’.
De ‘verbeteringen’ van GFPGAN zijn verschrikkelijk generisch, ondermijnen vaak de identiteit van het individu dat wordt afgebeeld, en werken uitsluitend op een gezicht dat geen meer verwerkingstijd of aandacht heeft ontvangen dan enig ander deel van de afbeelding.
Daarom zou een professionele standaardprogramma voor Stable Diffusion in staat moeten zijn om een gezicht te herkennen (met een standaard- en relatief lichtgewicht bibliotheek zoals YOLO), om de volledige kracht van de beschikbare GPU te gebruiken om het opnieuw te renderen, en om het verbeterde gezicht te mengen met de oorspronkelijke volledige context-render, of om het afzonderlijk op te slaan voor handmatige recompositie. Momenteel is dit een vrij ‘hands-on’ operatie.
In gevallen waarin Stable Diffusion is getraind op een adequaat aantal afbeeldingen van een beroemdheid, is het mogelijk om de volledige GPU-capaciteit te richten op een latere render van alleen het gezicht van de gegenereerde afbeelding, wat meestal een opvallende verbetering is – en, in tegenstelling tot GFPGAN, put uit informatie uit LAION-getrainde gegevens, in plaats van alleen het renderen van pixels aan te passen.
In-app LAION-zoekopdrachten
Sinds gebruikers begonnen te realiseren dat het zoeken naar LAION’s database naar concepten, personen en thema’s een hulp kan zijn voor een beter gebruik van Stable Diffusion, zijn verschillende online LAION-verkenners gemaakt, waaronder haveibeentrained.com.

De zoekfunctie op haveibeentrained.com laat gebruikers toe om de afbeeldingen te verkennen die de kracht vormen achter Stable Diffusion, en ontdekken of objecten, personen of ideeën die ze misschien willen oproepen uit het systeem, waarschijnlijk zijn getraind in het. Dergelijke systemen zijn ook nuttig om aangrenzende entiteiten te ontdekken, zoals de manier waarop beroemdheden zijn gegroepeerd, of het ‘volgende idee’ dat voortkomt uit het huidige. Bron: https://haveibeentrained.com/?search_text=bowl%20of%20fruit
Hoewel dergelijke webgebaseerde databases vaak enkele van de tags onthullen die de afbeeldingen begeleiden, betekent het proces van generalisatie dat plaatsvindt tijdens modeltraining dat het onwaarschijnlijk is dat een bepaalde afbeelding kan worden opgeroepen door het gebruik van de tag als prompt.
Bovendien betekent de verwijdering van ‘stopwoorden’ en de praktijk van stemming en lemmatisering in Natural Language Processing dat veel van de zinnen die worden weergegeven zijn opgesplitst of weggelaten voordat ze werden getraind in Stable Diffusion.
Niettemin kan de manier waarop esthetische groeperingen samenbinden in deze interfaces de eindgebruiker veel leren over de logica (of, naar alle waarschijnlijkheid, de ‘persoonlijkheid’) van Stable Diffusion, en kan het een hulp zijn bij betere afbeeldingsproductie.
Conclusie
Er zijn veel andere functies die ik zou willen zien in een volledig native desktop-implementatie van Stable Diffusion, zoals native CLIP-gebaseerde afbeeldingsanalyse, die het standaard Stable Diffusion-proces omkeert en de gebruiker toelaat om zinnen en woorden op te roepen die het systeem van nature zou associëren met de bronafbeelding, of de render.
Bovendien zou echte tegel-gebaseerde schaling een welkome toevoeging zijn, aangezien ESRGAN bijna even bot is als GFPGAN. Gelukkig zijn plannen om de txt2imghd-implementatie van GOBIG te integreren, snel deze realiteit maken over de distributies, en lijkt het een voor de hand liggende keuze voor een desktop-iteratie.
Sommige andere populaire verzoeken van de Discord-gemeenschappen interesseren me minder, zoals geïntegreerde promptwoordenboeken en toepasselijke lijsten van artiesten en stijlen, hoewel een in-app-notitieboek of aangepast lexicon van zinnen een logische toevoeging zou lijken.
Evenzo zijn de huidige beperkingen van mensgerichte animatie in Stable Diffusion, hoewel aangezet door CogVideo en verschillende andere projecten, nog steeds ongelooflijk embryonaal, en aan de genade van upstream-onderzoek naar temporele prioriteiten met betrekking tot authentieke menselijke beweging.
Voor nu is Stable Diffusion-video strikt psychedelisch, hoewel het een veel heldere toekomst kan hebben in deepfake-poppenspel, via EbSynth en andere relatief embryonale tekst-naar-video-initiatieven (en het is de moeite waard om op te merken het ontbreken van gesynthesizeerde of ‘gewijzigde’ personen in Runway’s laatste promotionele video).
Een andere waardevolle functionaliteit zou transparante Photoshop-doorstroom zijn, die al lang is gevestigd in Cinema4D’s texture-editor, onder andere soortgelijke implementaties. Hiermee kunt u afbeeldingen gemakkelijk tussen applicaties schakelen en elke applicatie gebruiken om de transformaties uit te voeren waarin het uitblinkt.
Tenslotte, en misschien wel het belangrijkste, zou een volledig desktop-Stable Diffusion-programma in staat moeten zijn om niet alleen gemakkelijk tussen checkpoints (d.w.z. versies van het onderliggende model dat het systeem aandrijft) te schakelen, maar ook om aangepaste Textual Inversions te updaten die werkten met eerdere officiële modelreleases, maar die mogelijk zijn gebroken door latere versies van het model (zoals ontwikkelaars op het officiële Discord hebben aangegeven dat dit het geval kan zijn).
Ironisch genoeg is de organisatie in de beste positie om een dergelijke krachtige en geïntegreerde matrix van tools voor Stable Diffusion te creëren, Adobe, zo sterk verbonden met de Content Authenticity Initiative dat het een retrograde PR-misstap zou kunnen lijken voor het bedrijf – tenzij het Stable Diffusion’s generatieve krachten zou beperken zoals OpenAI dat heeft gedaan met DALL-E 2, en het zou positioneren als een natuurlijke evolutie van zijn aanzienlijke bezit in stockfotografie.
Eerst gepubliceerd op 15 september 2022.












