Kunstmatige intelligentie
Andrew Ng bekritiseert de cultuur van overfitting in machine learning
Andrew Ng, een van de meest invloedrijke stemmen in machine learning in de afgelopen decade, uitte momenteel zijn zorgen over de mate waarin de sector innovaties in modelarchitectuur boven data benadrukt – en specifiek, de mate waarin het ‘overfitte’ resultaten toestaat om te worden afgebeeld als gegeneraliseerde oplossingen of vooruitgang.
Dit zijn verstrekkende kritieken op de huidige machine learning-cultuur, afkomstig van een van de hoogste autoriteiten, en hebben implicaties voor het vertrouwen in een sector die wordt geplaagd door angsten over een derde ineenstorting van het zakenvertrouwen in AI-ontwikkeling in een periode van zestig jaar.
Ng, een professor aan de Stanford-universiteit, is ook een van de oprichters van deeplearning.ai, en publiceerde in maart een missive op de site van de organisatie die een recente toespraak van hem samenvatte tot een paar kernaanbevelingen:
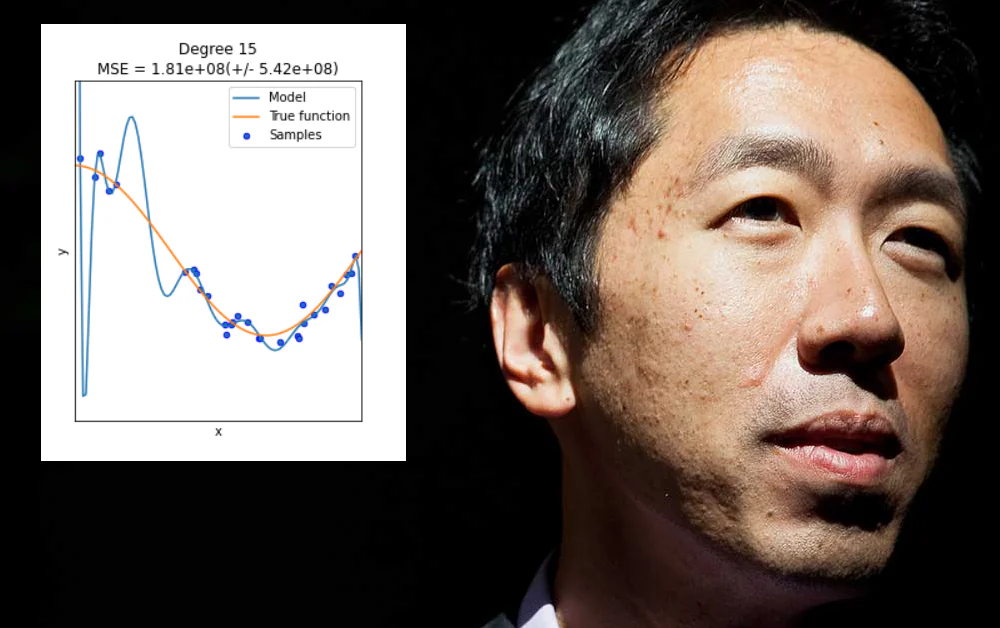
Ten eerste, dat de onderzoekscommunity moet stoppen met klagen dat data schoonmaken 80% van de uitdagingen in machine learning vertegenwoordigt, en moet beginnen met het ontwikkelen van robuuste MLOps-methodologieën en -praktijken.
Ten tweede, dat het moet afstappen van de ‘gemakkelijke overwinningen’ die kunnen worden behaald door data over te fitten aan een machine learning-model, zodat het goed presteert op dat model maar faalt om te generaliseren of om een breed inzetbaar model te produceren.
De uitdaging van data-architectuur en -curatie aanvaarden
‘Mijn mening’, schreef Ng, ‘is dat als 80 procent van ons werk data-voorbereiding is, dan is het waarborgen van datakwaliteit het belangrijke werk van een machine learning-team.’
Hij vervolgde:
‘In plaats van te vertrouwen op ingenieurs die toevallig de beste manier vinden om een dataset te verbeteren, hoop ik dat we MLOps-hulpmiddelen kunnen ontwikkelen die helpen om AI-systemen te bouwen, inclusief het bouwen van high-quality datasets, meer herhaalbaar en systematisch te maken.
‘MLOps is een embryonale sector, en verschillende mensen definiëren het op verschillende manieren. Maar ik denk dat het belangrijkste organisatieprincipe van MLOps-teams en -hulpmiddelen moet zijn om de consistente en high-quality stroom van data door alle fasen van een project te waarborgen. Dit zal helpen om veel projecten soepeler te laten verlopen.’
Tijdens een Zoom-gesprek op een live gestreamde Q&A-sessie eind april, besprak Ng het tekort aan toepasbaarheid in machine learning-analyse-systemen voor radiologie:
“Het blijkt dat wanneer we data verzamelen uit het Stanford Hospital, en dan trainen en testen op data uit hetzelfde ziekenhuis, we inderdaad papers kunnen publiceren die aantonen dat [de algoritmes] vergelijkbaar zijn met menselijke radiologen in het opsporen van bepaalde aandoeningen.
“…[Wanneer] je datzelfde model, datzelfde AI-systeem, naar een ouder ziekenhuis in de straat brengt, met een oude machine, en de technicus een iets andere beeldvormingsprotocol gebruikt, dan veroorzaakt die data-afwijking een aanzienlijke achteruitgang in de prestaties van het AI-systeem. In tegenstelling tot een menselijke radioloog, die gewoon naar het oude ziekenhuis kan lopen en het prima doet.”
Onderspecificatie is geen oplossing
Overfitting treedt op wanneer een machine learning-model specifiek is ontworpen om de eigenaardigheden van een bepaalde dataset (of de manier waarop de data is opgemaakt) te accommoderen. Dit kan bijvoorbeeld het specificeren van gewichten omvatten die goede resultaten opleveren voor die dataset, maar die niet ‘generaliseren’ op andere data.
In veel gevallen worden dergelijke parameters gedefinieerd op ‘non-data’-aspecten van de trainingsset, zoals de specifieke resolutie van de verzamelde informatie, of andere eigenaardigheden die niet gegarandeerd zijn om opnieuw te verschijnen in latere datasets.
Hoewel het leuk zou zijn, is overfitting geen probleem dat kan worden opgelost door blindelings de reikwijdte of flexibiliteit van data-architectuur of modelontwerp te vergroten, wanneer wat eigenlijk nodig is, zijn breed toepasbare en hoogwaardige kenmerken die goed presteren in een reeks data-omgevingen – een prikkelender uitdaging.
In het algemeen leidt dit type ‘onderspecificatie’ alleen maar tot de problemen die Ng onlangs heeft omschreven, waarin een machine learning-model faalt op ongeziene data. Het verschil in dit geval is dat het model faalt, niet omdat de data of data-opmaak anders is dan de oorspronkelijke trainingsset, maar omdat het model te flexibel is in plaats van te broos.
Laat in 2020 publiceerde de paper Underspecification Presents Challenges for Credibility in Modern Machine Learning intense kritiek op deze praktijk, en droeg de namen van niet minder dan veertig machine learning-onderzoekers en wetenschappers van Google en MIT, onder andere instituten.
De paper bekritiseert ‘shortcut learning’, en observeert de manier waarop onderspecificeerde modellen kunnen afwijken van de random seed-punt waarop de modeltraining begint. De bijdragers observeren:
‘We hebben gezien dat onderspecificatie overal in praktische machine learning-pijpleidingen voorkomt. Inderdaad, dankzij onderspecificatie, worden substantieel belangrijke aspecten van de beslissingen bepaald door willekeurige keuzes, zoals de random seed die wordt gebruikt voor parameterinitialisatie.’
Economische implicaties van het veranderen van de cultuur
Ondanks zijn academische referenties, is Ng geen luchthartige academicus, maar heeft hij diepe en hoogwaardige industrie-ervaring als mede-oprichter van Google Brain en Coursera, als voormalig hoofdwetenschapper voor Big Data en AI bij Baidu, en als oprichter van Landing AI, die $175 miljoen USD beheert voor nieuwe startups in de sector.
Wanneer hij zegt “Alles van AI, niet alleen gezondheidszorg, heeft een proof-of-concept-to-productiegap”, is het bedoeld als een wake-up call voor een sector waarvan het huidige niveau van hype en gespotte geschiedenis het steeds meer heeft gekenmerkt als een onzekere langetermijnzakelijke investering, geplaagd door problemen van definitie en reikwijdte.
Desondanks kunnen propriëtaire machine learning-systemen die goed functioneren in-situ en falen in andere omgevingen de soort marktaandeel vertegenwoordigen die industrie-investeringen kan belonen. Het presenteren van het ‘overfitting-probleem’ in de context van een beroepsgevaar biedt een oneerlijke manier om corporatie-investeringen in open source-onderzoek te monetiseren, en om (effectief) propriëtaire systemen te produceren waarbij replicatie door concurrenten mogelijk is, maar problematisch.
Of deze aanpak op lange termijn zal werken, hangt af van de mate waarin echte doorbraken in machine learning blijvend steeds grotere niveaus van investering vereisen, en of alle productieve initiatieven uiteindelijk naar FAANG zullen migreren vanwege de kolossale middelen die nodig zijn voor hosting en operaties.












